
Panel II
How Do We Make Software and Why Is It Unique?
INTRODUCTION
Dale W. Jorgenson
Harvard University
Dr. Jorgenson introduced the leadoff speaker of the second panel, Dr. Monica Lam, a professor of computer science at Stanford who was trained at Carnegie Mellon and whom he described as one of the world’s leading authorities on the subject she was to address.
HOW DO WE MAKE IT?
Monica Lam
Stanford University
Dr. Lam commenced by defining software as an encapsulation of knowledge. Distinguishing software from books, she noted that the former captures knowledge in an executable form, which allows its repeated and automatic application to new inputs and thereby makes it very powerful. Software engineering is like many other kinds of engineering in that it confronts many difficult problems,
but a number of characteristics nonetheless make software engineering unique: abstraction, complexity, malleability, and an inherent trade-off of correctness and function against time.
That software engineering deals with an abstract world differentiates it from chemical engineering, electrical engineering, and mechanical engineering, all of which run up against physical constraints. Students of the latter disciplines spend a great deal of time learning the laws of physics; yet there are tools for working with those laws that, although hard to develop initially, can be applied by many people in the building of many different artifacts. In software, by contrast, everything is possible, Dr. Lam said: “We don’t have these physical laws, and it is up to us to figure out what the logical structure is and to develop an abstract toolbox for each domain.” In Dr. Lam’s opinion, this abstraction, which carries with it the necessity of studying each separate domain in order to learn how artifacts may be built in it, makes software much more difficult than other fields of engineering.
The Most Complex Thing Humans Build
As to complexity, a subject raised by previous speakers, software may be the most complex thing that humans have learned how to build. This complexity is at least in part responsible for the fact that software development is still thriving in the United States. Memory chips, a product of electrical engineering, have left this country for Japan, Korea, and Taiwan. But complexity makes software engineering hard, and the United States continues to do very well in it.
The third characteristic is malleability. Building software is very different from building many other things—bridges, for example. The knowledge of how to build bridges accrues, but with each new bridge the engineer has a chance to start all over again, to put in all the new knowledge. When it comes to software, however, it takes time for hundreds of millions of lines of code to accrue, which is precisely how software’s complexity arises. A related problem is that of migrating the software that existed a long time ago to the present, with the requirements having changed in the meantime—a problem that again suggests an analogy to the Winchester Mystery House.
Trading Off Correctness Against Other Pluses
That no one really knows how to build perfect software—because it is abstract, complex, and at the same time malleable—gives rise to its fourth unique aspect: It can work pretty well even if it is not 100 percent correct.12 “There is a choice here in trading off correctness for more features, more function, and better
time to market,” Dr. Lam explained, “and the question ‘How do we draw this balance?’ is another unique issue seen in software development.”
Turning to the problem of measuring complexity, Dr. Lam noted that a theoretical method put forth by Kolmogorov measures the complexity of an object by the size of the Turing machine that generates it. Although it is the simplest kind of machine, the Turing machine has been proven equivalent in power to any supercomputer that can possibly be built. It does not take that many lines of Turing machine code to describe a hardware design, even one involving a billion transistors, because for the most part the same rectangle is repeated over and over again. But software involves millions and millions of lines of code, which probably can be compressed, but only to a limited degree. Pointing to another way of looking at complexity, she stated that everything engineered today—air-planes, for example—can be described in a computer. And not only can the artifact be described, it can be simulated in its environment.
The Stages of Software Development
Furthermore, the software development process comprises various stages, and those stages interact; it is a misconception that developers just start from the top and go down until the final stage is reached. The process begins with some idea of requirements and, beyond that, Dr. Lam said, “it’s a matter of how you put it together.” There are two aspects of high-level design—software architecture and algorithms—and the design depends on the kind of problem to be solved. If the problem is to come up with a new search engine, what that algorithm should be is a big question. Even when, as if often the case, the software entails no hard algorithmic problems, the problem of software architecture—the struggle to put everything together—remains. Once the high-level design is established, concern shifts to coding and testing, which is often carried out concurrently. These phases are followed by that of software maintenance, which she characterized as “a long tail.”
Returning to requirements, she noted that these evolve and that it is impossible to come up all at once with the full stack. Specifying everything about how a piece of software is supposed to work would yield a program not appreciably smaller than the voluminous assemblages of code that now exist. And the end user does not really know what he or she wants; because there are so many details involved, the only way to identify all the requirements is to build a working prototype. Moreover, requirements change across time and, as software lasts awhile, issues of compatibility with legacy systems can arise.
As for architectural design, each domain has its own set of concepts that help build systems in the domain, and the various processes available have to be automated. Just as in the case of requirements, to understand how to come up with the right architecture, one must build it. Recalling the injunction in The Mythical Man-Month, Fred Brook’s influential book, to “throw one away” when building a
system, Dr. Lam said that Brooks had told her some months before: “ ‘Plan to throw one away’ is not quite right. You have to plan to throw several of them away because you don’t really know what you are doing; it’s an iterative process; and you have to work with a working system.”13 Another important fact experience has taught is that a committee cannot build a new architecture; what is needed is a very small, excellent design team.
Two Top Tools: Abstraction and Modularity
About the only tools available are represented by the two truly important words in computer science: “abstraction” and “modularity.” A domain, once understood, must be cut up into manageable pieces. The first step is to create levels of abstraction, hiding the details of one from another, in order to cope with the complexity. In the meantime, the function to be implemented must be divided into modules, the tricky part being to come up with the right partitioning. “How do you design the abstraction? What is the right interface?” asked Dr. Lam, remarking: “That is the hard problem.”
Each new problem represents a clean slate. But what are the important concepts in the first place? How can they be put together in such a manner that they interact as little as possible and that they can be independently developed and revised? Calling this concept “the basic problem” in computer science, Dr. Lam said it must be applied at all levels. “It’s not just a matter of how we come up with the component at the highest level,” she explained, “but, as we take each of these components and talk about the implementation, we have to recursively apply the concepts of abstraction and modularity down to the individual functions that we write in our code.”
Reusing Components to Build Systems
Through the experience of building systems, computer scientists identify components that can be reused in similar systems. Among the tasks shared by a large number of applications are, at the operating-system level, resource sharing and protections between users. Moving up the stack, protocols have been developed that allow different components to talk to each other, such as network protocols and secure communication protocols. At the next level, common code can be shared through the database, which Dr. Lam described as “a simple concept that is very, very powerful.” Graphical tool kits are to be found at the next level up. Dr. Lam emphasized that difficulty decreases as one rises through the stack, and
that few people are able to master the concurrency issues associated with lower-level system functions.
While the reuse of components is one attempt at solving the problem of complexity, another is the use of tools, the most important of which are probably high-level programming languages and compilers. High-level programming languages can increase software productivity by sparing programmers worry over such low-level details as managing memory or buffer overruns. Citing Java as an example of a generic programming language, Dr. Lam said the principle can be applied higher up via languages designed for more specific domains. As illustrations of such higher-level programming languages, she singled out both Matlab, for enabling engineers to talk about mathematical formulas without having to code up the low-level details, and spreadsheets, for making possible the visual manipulation of data without requiring the writing of programs. In many domains, programmers are aided in developing abstractions by using the concept of object orientation: They create objects that represent different levels of abstraction, then use these objects like a language that is tailored for the specific domain.
Individual Variations in Productivity
But even with these tools for managing complexity, many problems are left to the coders, whose job is a hard one. Dr. Lam endorsed Dr. Raduchel’s assertion that productivity varies by orders of magnitude from person to person, noting that coding productivity varies widely even among candidates for the Ph.D. in computer science at Stanford. Recalling the “mythical man-month” discussed in Brooks’ book, she drew an analogy to the human gestation period, asking: “If it takes one woman 9 months to produce a baby, how long would it take if you had nine women?” And Brooks’ concept has darker implications for productivity, since he said that adding manpower not only would fail to make a software project finish earlier, it would in fact make a late software project even later.
But, at the same time that coding is acknowledged to be hard, “it’s also deceptively simple,” Dr. Lam maintained. If some of her students, as they tell her, were programming at the age of 5, how hard can programming be? At the heart of the paradox is the fact that the majority of a program has to do with handling exceptions; she drew an analogy to scuba-diving licenses, studying for which is largely taken up with “figuring out what to do in emergencies.” Less than 1 percent of debugging time is required to get a program to 90 percent correctness, and it will probably involve only 10 percent of the code. That is what makes it hard to estimate software development time. Finally, in a large piece of software there is an exponential number of ways to execute the code. Experience has taught her, Dr. Lam said, that any path never before seen to have worked probably will not work. This leads to the trade-off between correctness and time to market, features, and speed. In exchange for giving up on correctness, the software developer can get the product to market more quickly, put a lot more features on it, and produce
code that actually runs faster—all of which yields a cost advantage. The results of this trade-off are often seen in the consumer software market: When companies get their product to a point where they judge it to be acceptable, they opt for more features and faster time to market.
How Hardware, Software Design Handle Error
This highlights a contrast between the fields of software design and hardware design. While it may be true that hardware is orders of magnitude less complicated than software, it is still complicated enough that today’s high-performance microprocessors are not without complexity issues.14 But the issues are dealt with differently by the makers of hardware, in which any error can be very costly to the company: Just spinning a new mask, for example, may cost half a million dollars. Microprocessor manufacturers will not throw features in readily but rather introduce them very carefully. They invest heavily in CAD tools and verification tools, which themselves cost a lot of money, and they also spend a lot more time verifying or testing their code. What they are doing is really the same thing that software developers do, simulating how their product works under different conditions, but they spend more time on it. Of course, it is possible for hardware designers to use software to take up the slack and to mask any errors that are capable of being masked. In this, they have an advantage over software developers in managing complexity problems, as the latter must take care of all their problems at the software level.
“Quality assurance” in software development by and large simply means testing and inspection. “We usually have a large number of testers,” Dr. Lam remarked, “and usually these are not the people whom you would trust to do the development.” They fire off a lot of tests but, because they are not tied to the way the code has been written, these tests do not necessarily exercise all of the key paths through the system. While this has advantages, it also has disadvantages, one of which is that the resulting software can be “very fragile and brittle.” Moreover, testers have time to fix only the high-priority errors, so that software can leave the testing process full of errors. It has been estimated that a good piece of software may contain one error every thousand lines, whereas software that is not mature may contain four and a half errors per thousand lines.
If Windows 2000, then, has 35 million lines of code, how many errors might there be? Dr. Lam recalled that when Microsoft released the program, it also—accidentally—released the information that it had 63,000 known bugs at the time of release, or about two errors per thousand lines of code. “Remember: These are
the known bugs that were not fixed at the time of release,” she stated. “This is not counting the bugs that were fixed before the release or the bugs that they didn’t know about after the release.” While it is infeasible to expect a 100 percent correct program, the question remains: Where should the line be drawn?
Setting the Bar on Bugs
“I would claim that the bar is way too low right now,” declared Dr. Lam, arguing that there are “many simple yet deadly bugs” in Windows and other PC software. For an example, she turned to the problem of buffer overrun. Although it has been around for 15 years, a long time by computer-industry standards, this problem is ridiculously simple: A programmer allocates a buffer, and the code, accessing data in the buffer, goes over the bound of the buffer without checking that that is being done. Because the software does this, it is possible to supply inputs to the program that would seize control of the software so that the operator could do whatever he or she wanted with it. So, although it can be a pretty nasty error, it is a very simple error and, in comparison to some others, not that hard to fix. The problem might, in fact, have been obviated had the code been written in Java in the first place. But, while rewriting everything in Java would be an expensive proposition, there are other ways of solving the problem. “If you are just willing to spend a little bit more computational cycles to catch these situations,” she said, “you can do it with the existing software,” although this would slow the program down, something to which consumers might object.
According to Dr. Lam, however, the real question is not whether these errors can be stopped but who should be paying for the fix, and how much. Today, she said, consumers pay for it every single time they get a virus: The Slammer worm was estimated to cost a billion dollars, and the MS Blaster worm cost Stanford alone $800,000. The problem owes its existence in part to the monopoly status of Microsoft, which “doesn’t have to worry about a competitor doing a more reliable product.”
To add insult to injury, every virus to date has been known ahead of time. Patches have been released ahead of the attacks, although the lead time has been diminishing—from 6 weeks before the virus hits to, more recently, about 1 week. “It won’t be long before you’ll be seeing the zero-day delay,” Dr. Lam predicted. “You’ll find out the problem the day that the virus is going to hit you.” Asking consumers to update their software is not, in her opinion, “a technically best solution.”
Reliability: Software to Check the Software
A number of places have been doing research on improving software reliability, although it is of a different kind from that at the Software Engineering
Institute. From Dr. Lam’s perspective, what is needed to deal with software complexity is “software to go check the software,” which she called “our only hope to make a big difference.” Tools are to be found in today’s research labs that, running on existing codes such as Linux, can find thousands of critical errors—that is, errors that can cause a system to crash. In fact, the quality of software is so poor that it is not that hard to come up with such tools, and more complex tools that can locate more complex errors, such as memory leaks, are also being devised. Under study are ideas about detecting anomalies while the program runs so that a problem can be intercepted before it compromises the security of the system, as well as ideas for higher-level debugging tools. In the end, the goal should not be to build perfect software but software that can automatically recover from some errors. Drawing a distinction between software tools and hardware tools, she asserted that companies have very little economic incentive to encourage the growth of the former. If, however, software producers become more concerned about the reliability of their product, a little more growth in the area of software tools may ensue.
In conclusion, Dr. Lam reiterated that many problems arise from the fact that software engineering, while complex and hard, is at the same time deceptively simple. She stressed her concern over the fact that, under the reigning economic model, the cost of unreliability is passed to the unwitting consumer and there is a lack of investment in developing software tools to improve the productivity of programmers.
INTRODUCTION
James Socas
Senate Committee on Banking
Introducing the next speaker, Dr. Hal Varian, Mr. Socas noted that Dr. Varian is the Class of 1944 Professor at the School of Information Management and Systems of the Haas School of Business at the University of California at Berkeley, California; co-author of a best-selling book on business strategy, Information Rules: A Strategic Guide to the Network Economy; and contributor of a monthly column to the New York Times.
OPEN-SOURCE SOFTWARE
Hal R. Varian
University of California at Berkeley
While his talk would be based on work he had done with Carl Shapiro focusing specifically on the adoption of Linux in the public sector, Dr. Varian noted
that much of that work also applies to Linux or open-source adoption in general.15 Literature on the supply of open source addresses such questions as who creates it, why they do it, what the economic motivations are, and how it is done.16 A small industry exists in studying CVS logs: how many people contribute, what countries they’re from, a great variety of data about open-source development.17 The work of Josh Lerner of Harvard Business School, Jean Tirole, Neil Gandal, and several others provides a start in investigating that literature.18 Literature on the demand for open source addresses such questions as who uses it, why they use it, and how they use it. While the area is a little less developed, there are some nice data sources, including the FLOSS Survey, or Free/Libre/Open-Source Software Survey, conducted in Europe.19
Varian and Shapiro’s particular interest was looking at economic and strategic issues involving the adoption and use of open-source software with some focus on the public sector. Their research was sponsored by IBM Corporation, which, as Dr. Varian pointed out, has its own views on some of the issues studied. “That’s supposed to be a two-edged sword,” he acknowledged. “One edge is that that’s who paid us to do the work, and the other edge is that they may not agree with what we found.”
Definition of Open Source
Distinguishing open-source from commercial software, Dr. Varian defined open source as software whose source code is freely available. Distinguishing open interface from proprietary interface, he defined an open interface as one that is completely documented and freely usable, saying that could include the pro-
|
15 |
See Hal R. Varian and Carl Shapiro, “Linux Adoption in the Public Sector: An Economic Analysis,” Department of Economics, University of California at Berkeley, December 1, 2003. Accessed at <http://www.sims.berkeley.edu/~hal/Papers/2004/linux-adoption-in-the-public-sector.pdf>. |
|
16 |
An extended bibliography on open-source software has been compiled by Brenda Chawner, School of Information Management, Victoria University of Wellington, New Zealand. Accessed at <http://www.vuw.ac.nz/staff/brenda_chawner/biblio.html>. |
|
17 |
CVS (Concurrent Versions System) is a utility used to keep several versions of a set of files and to allow several developers to work on a project together. It allows developers to see who is editing files, what changes they made to them, and when and why that happened. |
|
18 |
See Josh Lerner and Jean Tirole, “The Simple Economics of Open Source,” Harvard Business School, February 25, 2000. Accessed at <http://www.hbs.edu/research/facpubs/>. See also Neil Gandal and Chaim Fershtman, “The Determinants of Output per Contributor in Open Source Projects: An Empirical Examination,” CEPR Working Paper 2650, 2004. Accessed at <http://spirit.tau.ac.il/public/gandal/Research.htmworkingpapers/papers2/9900/00-059.pdf>. |
|
19 |
The FLOSS surveys were designed to collect data on the importance of open source software (OSS) in Europe and to assess the importance of OSS for policy- and decision-making. See FLOSS Final Report, accepted by the European Commission in 2002. Accessed at <http://www.infonomics.nl/FLOSS/report/index.htm>. |
grammer interface, the so-called Application Programming Interface or API; the user interface; and the document interface. Without exception, in his judgment, open-source software has open interfaces; proprietary software may or may not have open interfaces.20 Among the themes of his research is that much of the benefit to be obtained from open-source software comes from the open interface, although a number of strategic issues surrounding the open interface mandate caution. Looking ahead to his conclusion, he called open-source software a very strong way to commit to an open interface while noting that an open interface can also be obtained through other sorts of commitment devices. Among the many motivations for writing software—“scratching an itch, demonstrating skill, generosity, [and] throwing it over the fence” being some he named—is making money, whether through consulting, furnishing support-related services, creating distributions, or providing complements.
The question frequently arises of how an economic business can be built around open source. The answer is in complexity management at the level of abstraction above that of software. Complexity in production processes in organizations has always needed to be managed, and while software is a tool for managing complexity, it creates a great deal of complexity itself. In many cases—in the restaurant business, for instance—there is money to be made in combining standard, defined, explicit ingredients and selling them. The motor vehicle provides another example: “I could go out and buy all those parts and put them together in my garage and make an automobile,” Dr. Varian said, “but that would not be a very economic thing to do.” In software as well, there is money to be made by taking freely available components and combining them in ways that increase ease of management, and several companies are engaged in doing that.
The Problem of Forking or Splintering
The biggest danger in open-source software is the problem of forking or splintering, “a la UNIX.” A somewhat anarchic system for developing software may yield many different branches of that software, and the challenge in many open-source software projects is remaining focused on a standard, interchangeable, interoperable distribution. Similarly, the challenge that the entire open-source industry will face in the future is managing the forking and splintering problem.
As examples of open source Dr. Varian named Linux and BSD, or Berkeley Standard Distribution. Although no one knows for certain, Linux may have
18 million users, around 4 percent of the desktop market. Many large companies have chosen Linux or BSD for their servers; Amazon and Google using the former, Yahoo the latter. These are critical parts of their business because open source allows them to customize the application to their particular needs. Another prominent open-source project, Apache, has found through a thorough study that its Web server is used in about 60 percent of Web sites. “So open source is a big deal economically speaking,” Dr. Varian commented.
What Factors Influence Open-source Adoption?
Total cost of ownership. Not only the software code figures in, but also support, maintenance, and system repair. In many projects the actual expense of purchasing the software product is quite low compared to the cost of the labor necessary to support it. Several studies have found a 10 to 15 percent difference in total cost of ownership between open-source and proprietary software—although, as Dr. Varian remarks, “the direction of that difference depends on who does the study” as well as on such factors as the time period chosen and the actual costs recorded. It is also possible that, in different environments, the costs of purchasing the software product and paying the system administrators to operate it will vary significantly. Reports from India indicate that a system administrator is about one-tenth of the cost of a system administrator in the U.S., a fact that could certainly change the economics of adoption; if there is a 10 to 15 percent difference in total cost of ownership using U.S. prices, there could be a dramatic difference using local prices when labor costs are taken into account.
Switching costs. Varian and Shapiro found this factor, which refers to the cost incurred in switching to an alternative system with similar functionality, to be the most important. Switching tends to cost far more with proprietary interfaces for the obvious reason that it requires pretty much starting from scratch. When a company that has bought into a system considers upgrading or changing, by far the largest cost component it faces is involved in retraining, changing document formats, and moving over to different systems. In fact, such concerns dominate that decision in many cases, and they are typically much lower for software packages with open interfaces.
Furthermore, cautioned Dr. Varian, “vendors—no matter what they say—will typically have an incentive to try to exploit those switching costs.” They may give away version n of a product but then charge what the market will bear for version n + 1. While this looms as a problem for customers, it also creates a problem for vendors. For the latter, one challenge is to convince the customer that, down the road, they will not exploit the position they enjoy as not only supplier of the product but also the sole source of changes, upgrades, updates, interoperability, and so on. One way of doing so is to have true open interfaces, and since open source is a very strong way to achieve the open interface that customers demand, it is attractive as a business model.
By way of illustration, Dr. Varian invoked the history of PostScript, whose origin was as a page-description language called Interleaf that was developed by Xerox. The company wanted to release the system as a proprietary product, but potential adopters, afraid of locking themselves into Xerox, shied away from buying it. Interleaf’s developer left Xerox to start Adobe; developed a similar language, PostScript; and released its specification into the public domain, which allowed anybody to develop a PostScript interpreter. Creating a competitive environment was necessary because, unless they had a fallback, customers would not commit to the product.
The Limits of Monopoly Power
According to Dr. Varian, this has increasingly become an issue in software systems, to the point that in many cases it is hard to exploit a monopoly position. Microsoft, for instance, faces an extremely difficult business-strategy problem when it comes to the Chinese market. “Why should [China’s government] allow users there to take the first shot of a very expensive drug?” he asked. “It’s cheap now—maybe it’s free because it’s a pirated copy—but in the future it will be expensive.” Since most communication in China is still domestic and from Chinese to Chinese, the network effects are relatively small. So the government has an incentive to choose the system with the lowest switching cost, then build its own network for document interchange. Microsoft, for its part, faces a dilemma; perhaps it can tolerate, even encourage piracy for a while to try to get the system adopted widely on the ground. But how can it commit to refraining from future exploitation?
Mandating open interface, now being discussed by the European Union, would be “a big help” in solving this problem. Because mandating open interface is also a strong way of committing to lowering switching costs, it is in many ways attractive from the point of the adopting company, although it could spill over into existing markets and cut into profits in incumbent markets.
Reasons for Adopting Open Source
The FLOSS Survey previously mentioned, having investigated reasons for adoption of open source, argued that higher stability was very important and that maintainability was also important because the structure of the software was more attractive. Since the software is developed in a very distributed manner, it has to be more modular because of the nature of the production process.21 Modular
software is typically more robust, and forcing modularity through the development process may simplify maintenance.
Usability is another interesting case. User testing is typically very labor intensive and costly, but the intellectual property status of interfaces is still somewhat ambiguous. Dr. Varian recalled that the U.S. Supreme Court split 4-4 on the Lotus-Quattro case, and the question of to just what degree a user interface may be copied is not clear under U.S. laws.22 In addition, it may be possible for investment in user testing to be appropriated by other vendors. Indeed, many open-source projects look very similar, with respect to the user interface, to some well-known proprietary products.
Then there’s the issue of security. One advantage of having access to the source code is that it permits customizing product to meet specific goals. On its Web site, NSA posts a hardened version of Linux that can be downloaded and used for certain applications, and that can be made smaller, larger, harder, more secure, more localized, and so on. Such flexibility is an advantage.
Turning to licensing, Dr. Varian noted that there are many different licenses and referred to a paper in a legal journal that distinguished some 45 of them. Perhaps the most notorious is the GNU public license, which has a provision, “Copyleft,” requiring those who modify and distribute open-source software outside their organization to include the source code. While this is a somewhat controversial provision, it applies only under narrow conditions and is in some respect not so different from any other kind of intellectual property right: It is simply a provision of the license that the creator has put into the product.
Open Source and Economic Development
Because this original focus of Varian and Shapiro’s work was on adoption in the public sector, it treats claims about the importance of open-source software for economic development. The first and most prominent piece of advice that one might give, Dr. Varian stated, is to favor open interfaces wherever possible. He reiterated that while the open interface is provided by open source, there are other ways to get software with open interfaces, and much proprietary software has relatively open interfaces. He also recommended being very careful about the lock-in problem: “If you’re going to have switching costs down the road from adopting, let’s say, something with a proprietary interface on any of the sides I mentioned, then it’s going to be difficult in terms of the interoperability.” Recalling Dr. Raduchel’s praise of standards, he insisted on a single qualification: Such
examples as the flathead screw and the resolution of U.S. TV show that premature standardization can lock users into a standard that later they wish they hadn’t chosen. Progress stops in a component when it becomes standardized and everybody produces to that standard. This can spur innovation, because this component can be used to build other, more complex systems. But there is always a choice—which in many cases is very agonizing—as to whether that is the right point at which to standardize the particular technology.
Another constructive role played by open-source software, said Dr. Varian, is in education: “Imagine trying to train mechanics if they could never work with real engines!” This point was championed by Donald Knuth through his release of TeX, a large open-source program. Knuth was concerned that students could never get access to real programs; they were unable to see how proprietary programs worked, and the programs they could see, written by physicists, provided terrible instruction for computer scientists. Knuth’s aim was to write a program that, because it was good from the viewpoint of design and structure, could serve as a model for future students. A great deal of open-source software has the side effect of being extremely valuable in training and education. According to the Berkeley computer science department’s chair, all of its students use Linux and many claim not to know Windows at all. Admittedly, this may be accounted for partly by pride and partly by a desire to avoid being dragooned into fixing their friends’ systems. But what is important is that Linux is the model they use for software development, something that also applies in less-developed countries.
In closing, Dr. Varian pointed to a paper posted on his Web site that is accompanied by discussion of economic effects of open-source software, including the issues of complementarities, commitment, network effects, licensing terms, and bundling (See Figure 4).23 He then invited questions.
DISCUSSION
Dr. Varian was asked whether the fact that today’s scientists typically do not understand the software they use implies limits on their understanding of the science in which they are engaged.
Who Should Write the Software?
Acknowledging this as a perennial problem, Dr. Varian pointed to a related phenomenon that can be observed at most universities: While there is a separate statistics department, individual departments have internal statistics departments that pursue, for example, psychometrics, econometrics, biometrics, or public-
|
23 |
Professor Varian’s papers can be accessed at <http://www.sims.berkeley.edu/~hal/people/hal/papers.html>. |
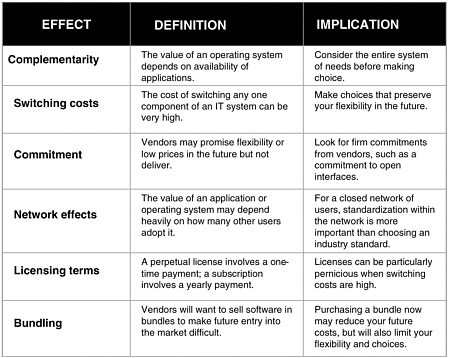
FIGURE 4 Economic effects.
health statistics. All sciences need to know something about software engineering in order to build systems that can meet their needs, but is it better that they build them themselves, outsource them to somebody else, or strike a more collaborative arrangement? Berkeley is trying an interdisciplinary approach.
Dr. Lam, offering a computer scientist’s perspective, said that computer science people don’t necessarily know any better than scientists in other disciplines what their software is doing. “Otherwise,” she asked, “why do we have this software problem?” Whether the software is open source or not is not the issue. The fact is that, after writing a program, one can look at all the lines of code and still not know what the software is doing. Even the more readily accessible high levels will behave differently than expected because there are going to be bugs in them. Part of the object of current research is achieving a fuller view of what the code is actually doing so that one is not just staring at the source lines.
Work Organization for Software Development
Mr. Socas, alluding to his experience working in Silicon Valley, recalled that one of the big debates was on how to organize people for software development.
In competition were the industrial or factory model, which is the way most of the U.S. economy is set up, and the “Hollywood” or campus model, which assumes that the skill set needed to create software is unique and that, therefore, those with the talent to do it should be given whatever it is they want. He asked the panelists to comment on the organizational challenges remaining to optimal software development and on whether open-source software changes the game by providing an alternative to the hierarchical, all-in-one company model.
Dr. Varian, disclaiming expertise in the matter, nonetheless remarked that the success of the distributed model of open-source development—with contributions from around the world being merged into a product that actually works—has come as a big surprise to some. He mentioned the existence of a Pareto distribution or power law for the field under which a relatively small number of people contribute a “big, big chunk of the code,” after which bug fixes, patches, and other, minor pieces are contributed “here or there.”24 This underlines the importance of the power programmer: the principle that a few very good people, made more accessible by the advent of the Internet, can be far more productive than many mediocre people. Returning to the question of China, he posited that if that nation “really does go open source in a very big way,” the availability of hundreds of millions of Chinese engineers for cleaning up code could have a major and beneficial impact on the rest of the world.
Open-Source vs. Proprietary in the Future
Asked to speculate on the relative dominance of open-source and proprietary platforms a decade down the road, Dr. Varian predicted that open source would make a strong impact. This will be particularly true in parts of the world where networks are not yet in place, as building to an open standard is easier and far better for long-run development. With China, India, and other countries making major efforts in this area, the United States and, to a lesser extent, Europe will be on their own path, using a different standard from the rest of the world. He acknowledged this as “an extreme prediction,” but added: “That would be my call at this point.”
Kenneth Walker of SonicWALL noted that, although it is not widely known, the Mac OS (operating system) was built on top of BSD.25 Open source, there-
fore, is “the kernel of what the Mac is,” and even the changes that Apple has made to that kernel and core have been put out by the company as an open-source project called Darwin—which, “interestingly enough,” runs on Intel hardware.
Rights Specified in Copyright Licenses
Dr. Varian was asked for his recommendations on what should not be allowed in a license that constrains subsequent use of software should Congress move to revise copyright laws to state what types of licenses copyright owners of software should and should not be able to specify.
While declining to make strong recommendations for the time being, Dr. Varian pointed out that software is most valuable when it can be combined, recombined, and built upon to produce a secure base upon which additional applications can in turn be built. The challenge is ensuring the existence of incentives sufficient to developing those basic components, while at the same time ensuring that, once they are built, they will be widely available at low cost so that future development is stimulated. Of major concern are licenses that have some ex-post manipulability, he said, describing what economists call “holdup”: “I release a license, and you use it for 2 years. When it’s up for renewal I say, ‘Wow, you’ve built a really fantastic product out of this component—so I’m going to triple the price.’ ” Since holdup discourages widespread use of a product, it is important that licenses, whatever form they take, can be adopted with some confidence that the path to future use of the product is secure.
Who Uses Open-Source, and Where Are They?
Asked by Egils Milbergs of the Center for Accelerating Innovation to characterize the users of open-source software, Dr. Varian said that very few are end users and that many products developed in open source are meant for developers. He explained this by elaborating on one of the motivations he had listed for writing software, “scratching an itch:” A software professional confronted by a particular problem builds a tool that will help solve it, then decides to make the tool available to others to use and improve. While there have been many efforts to make software more user-friendly down to the end-user level, that is often a very difficult task. Since copying existing interfaces may be the easiest way to accomplish this, it is what has commonly been done.
In response to another question from Mr. Milbergs, on the geographic distribution of open-source users, Dr. Varian noted that logs from CVS, a system used
|
|
Systems Research Group (CSRG) was the most important source of Unix development outside of Bell Labs. Along with AT&T’s own System V, BSD became one of the two major Unix flavors. See <http://kb.iu.edu/data/agom.html>. |
to manage the development of open-source software, are an important source of data. These publicly available logs show how many people have checked in, their email addresses, and what lines they have contributed. Studies of the logs that examine geographic distribution, time distribution, and lines contributed paint a useful picture of the software-development process.
Assigning Value to Freely Distributed Code
David Wasshausen of the U.S. Department of Commerce asked how prevalent the use of open-source code currently is in the business world and how value is assigned both to code that is freely distributed and to the final product that incorporates it. As an economic accountant, he said, he felt that there should be some value assigned to it, adding, “It’s my understanding that just because it’s open-source code it doesn’t necessarily mean that it’s free.”26 He speculated that the economic transaction may come in with the selling of complete solutions based on open-source code, citing the business model of companies like Red Hat.
Dr. Varian responded by suggesting that pricing of open-source components be based on the “next-best alternative.” He recounted a recent conversation with a cash-register vendor who told him that the year’s big innovation was switching from Windows 95 to Windows 98—a contemporary cash register being a PC with an alternative front end. Behind this switch was a desire for a stable platform which had known bugs and upon which new applications could be built. Asked about Linux, the vendor replied that the Europeans were moving into it in a big way. Drawing on this example, Dr. Varian posited that if running the cash register using Linux rather than Windows saved $50 in licensing fees, then $50 would be the right accounting number. He acknowledged that the incremental cost of developing and supporting the use of Linux might have to be added. However, he likened the embedding of Linux in a single-application device such as a cash register to the use of an integrated circuit or, in fact, of any other standardized part. “Having a component that you can drop into your device, and be pretty confident it’s going to work in a known way, and modify any little pieces you need to modify for that device,” he said, “is a pretty powerful thing.” This makes using Linux or other open-source software extremely attractive to the manufacturer who is building a complex piece of hardware with a relatively simple interface and needs no more than complexity management of the electronics. In such a case, the open-source component can be priced at the next-best alternative.
INTRODUCTION
James Socas
Senate Committee on Banking
Introducing Kenneth Walker of SonicWALL, Mr. Socas speculated that his title—Director of Platform Evangelism—is one that “you’ll only find in Silicon Valley.”
MAKING SOFTWARE SECURE AND RELIABLE
Kenneth Walker
SonicWALL
Alluding to the day’s previous discussion of the software stack, Mr. Walker stated as the goal of his presentation increasing his listeners’ understanding of the security stack and of what is necessary to arrive at systems that can be considered secure and reliable. To begin, he posed a number of questions about what it means to secure software:
-
What is it we’re really securing?
-
Are we securing the individual applications that we run: Word? our Web server? whatever the particular machinery-control system is that we’re using?
-
Or are we securing access to the machine that that’s on?
-
Or are we securing what you do with the application? the code? the data? the operating system?
All of the above are involved with the security even of a laptop, let alone a network or collection of machines and systems that have to talk to each other—to move data back and forth—in, hopefully, a secure and reliable way.
Defining Reliability in the Security Context
The next question is how to define reliability. For some of SonicWALL’s customers, reliability is defined by the mere fact of availability. That they connect to the network at all means that their system is up and running and that they can do something; for them, that amounts to having a secure environment. Or is reliability defined by ease of use? by whether or not the user has to reboot all the time? by whether there is a backup mechanism for the systems that are in place? Mr. Walker restated the questions he raised regarding security, applying them to reliability: “Are we talking about applications? or the operating system? or the machine? or the data that is positively, absolutely needed right now?”
Taking up the complexity of software, Mr. Walker showed a chart depicting the increase in the number of lines of code from Windows 3.1 through Windows
XP (See Figure 5). In the same period, attacks against that code—in the form of both network-intrusion attempts and infection attempts—have been growing “at an astronomical pace” (See Figure 6). When Code Red hit the market in 2001, 250,000 Web servers went down in 9 hours, and all corners of the globe were affected. The Slammer worm of 2003 hit faster and took out even more systems.
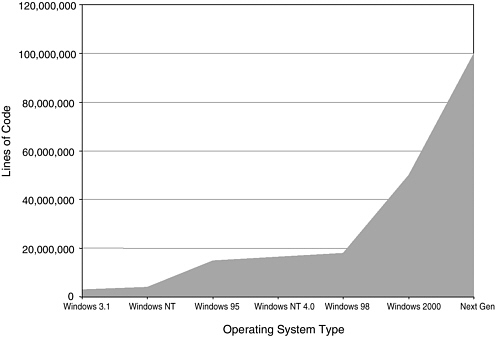
FIGURE 5 Software is getting more complex.
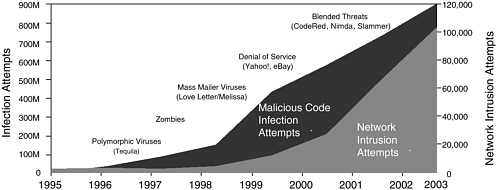
FIGURE 6 Attacks against code are growing.
NOTE: Analysis by Symantec Security Response using data from Symantec, IDC & ICSA.
Threats to Security from Outside
These phenomena are signs of a change in the computing world that has brought with it a number of security problems Mr. Walker classified as “external,” in that they emanate from the environment at large rather than from within the systems of individual businesses or other users. In the new environment, the speed and sophistication of cyber-attacks are increasing. The code that has gone out through the open-source movement has not only helped improve the operating-system environment, it has trained the hackers, who have become more capable and better organized. New sorts of blended threats and hybrid attacks have emerged.27
Promising to go into more detail later on the recent Mydoom attack, Mr. Walker noted in passing that the worm did more than infect individuals’ computers, producing acute but short-lived inconvenience, and then try to attack SCO, a well-known UNIX vendor.28 It produced a residual effect, to which few paid attention, by going back into each machine’s settings; opening up ports on the machine; and, if the machine was running different specific operating systems, making it more available to someone who might come in later, use that as an exploit, and take over the machine for other purposes—whether to get at data, reload other code, or do something else. The attack on SCO, he cautioned, “could be considered the red herring for the deeper issue.” Users could have scrubbed their machines and gotten Mydoom out of the way, but the holes that the worm left in their armor would still exist.
Returning to the general features of the new environment, Mr. Walker pointed out that the country has developed a critical infrastructure that is based on a network. Arguing that the only way to stop some security threats would be to kill the Internet, he asked how many in the audience would be prepared to give up email or see it limited to communication between departments, and to go back to faxes and FedEx. Concluding his summary of external security issues, he said it was important to keep in mind that cyber-attacks cross borders and that they do not originate in any one place.
Threats to Security from Inside
Internal security issues abound as well. Although it is not very well understood by company boards or management, many systems now in place are misconfigured, or they have not had the latest patches applied and so are out of date. Anyone who is mobile and wireless is beset by security holes, and mobile workers are extending the perimeter of the office environment. “No matter how good network security is at the office, when an employee takes a laptop home and plugs up to the network there, the next thing you know, they’re infected,” Mr. Walker said. “They come back to the office, plug up, and you’ve been hacked.” The outsourcing of software development, which is fueled by code’s growing complexity, can be another source of problems. Clients cannot always be sure what the contractors who develop their applications have done with the code before giving it back. It doesn’t matter whether the work is done at home or abroad; they don’t necessarily have the ability to go through and test the code to make sure that their contractor has not put back doors into it that may compromise their systems later.
Mr. Walker stressed that there is no one hacker base—attacks have launched from all over the globe—and that a computer virus attack can spread instantaneously from continent to continent. This contrasts to a human virus outbreak, which depends on the physical movement of individuals and is therefore easier to track.
Taking Responsibility for Security
While there is a definite problem of responsibility related to security, it is a complicated issue, and most people do not think about it or have not thought about it to date. Most reflexively depend on “someone in IT” to come by with a disk to fix whatever difficulties they have with their machines, never pausing to think about how many other machines the information specialist may have to visit. Similarly, managers simply see the IT department as taking care of such problems and therefore rarely track them. But “prevention, unfortunately, takes people to do work,” said Mr. Walker, adding, “We haven’t gotten smart enough around our intrusion-prevention systems to have them be fully automated and not make a lot of mistakes.” The frequency of false positives and false negatives may lead businesses to throw away important protections against simple threats.
Perceptions of Security
Masking the amount of work that goes into security is the fact that the user can tell security is working correctly only when nothing goes wrong, which makes adequate security appear easy to attain. Masking its value is that no enterprise gets any economic value for doing a good job securing itself; the economic value
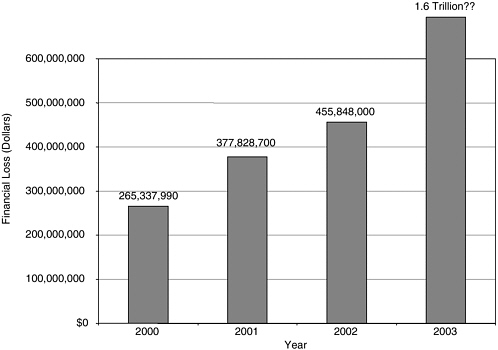
FIGURE 7 Financial impact of worms and viruses.
becomes apparent only when a business starts to be completely taken down by not having invested in security.29 For this reason, time and money spent on security are often perceived as wasted by managers, whose complaint Mr. Walker characterized as “ ‘I’ve got to put in equipment, I’ve got to train people in security, I’ve got to have people watching my network all the time.’ ” The St. Paul Group, in fact, identified the executive’s top concern in 2003 as “How do I cut IT spending?” Unless more money is spent, however, enterprise security will remain in its current woeful state, and the financial impact is likely to be considerable. E-Commerce Times has projected the global economic impact of 2003’s worms and viruses at over $1 trillion (See Figure 7).
The Mydoom Virus and its Impact
The first attack of 2004, Mydoom, was a mass-mailing attack and a peer-to-peer attack. Mr. Walker described it as “a little insidious” in that, besides hitting as a traditional email worm, it tried to spread by copying itself to the shared directory for Kazaa clients when it could find it. Infected machines then started sharing data back and forth even if their email was protected. “The worm was smart enough to pay attention to the social aspects of how people interact and share files, and wrote itself into that,” he commented. Mydoom also varied itself, another new development. Whereas the Code Red and Slammer worms called themselves the same thing in every attachment, Mydoom picked a name and a random way of disguising itself: Sometimes it was a zip file, sometimes it wasn’t. It also took the human element into account. “As much as we want to train our users not to,” Mr. Walker observed, “if there’s an attachment to it, they double-click.” There was a woman in his own company who clicked on the “I Love You” variant of Slammer 22 times “because this person was telling her he loved her, and she really wanted to see what was going on, despite the fact that people were saying, ‘Don’t click on that.’ ”
As for impact, Network Associates estimated Mydoom and its variants infected between 300,000 and 500,000 computers, 10 to 20 times more than the top virus of 2003, SoBig. F-Secure’s estimate was that on January 28, 2004, Mydoom accounted for 20 to 30 percent of global email traffic, well above previous infections. And, as mentioned previously, there were after-effects: MyDoom left ports open behind it that could be used as doorways later on. On January 27, 2004, upon receipt of the first indications of a new worm’s presence, Network Associates at McAfee, Symantec, and other companies diligently began trying to deconstruct it, figure out how it worked, figure out a way to pattern-match against it, block it, and then update their virus engines in order to stop it in its tracks. Network Associates came out with an update at 8:55 p.m., but, owing to the lack of discipline when it comes to protecting machines, there was a peak of infection the next morning at 8:00, when users launched their email and started to check the messages (See Figure 8). There are vendors selling automated methods of enforcing protection, but there have not been many adopters. “People need to think about whether or not enforced antivirus in their systems is important enough to pay for,” Mr. Walker stated.
The Hidden Costs of Security Self-Management
Self-management of antivirus solutions has hidden costs. For Mydoom, Gartner placed the combined cost of tech support and productivity lost owing to workers’ inability to use their machines at between $500 and $1,000 per machine infected. Mr. Walker displayed a lengthy list of cost factors that must be taken into account in making damage estimates and commented on some of these elements:
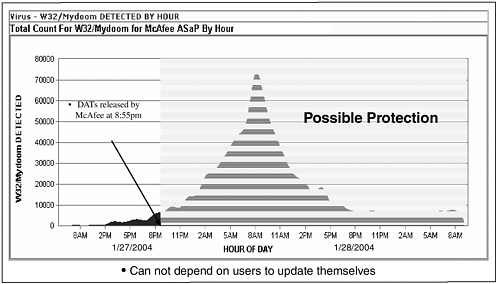
FIGURE 8 Antivirus enforcement in action.
-
help-desk support for those who are unsure whether their machines have been affected, to which the expense of 1-800 calls may be added in the case of far-flung enterprises;
-
false positives, in which time and effort are expended in ascertaining that a machine has not, in fact, been infected;
-
overtime payments to IT staff involved in fixing the problem;
-
contingency outsourcing undertaken in order to keep a business going while its system is down, an example being SCO’s establishing a secondary Web site to function while its primary Web site was under attack;
-
loss of business;
-
bandwidth clogging;
-
productivity erosion;
-
management time reallocation;
-
cost of recovery; and
-
software upgrades.
According to mi2g consulting, by February 1, 2004, Mydoom’s global impact had reached $38.5 billion.
Systems Threats: Forms and Origins
The forms of system threats vary with their origins. The network attack targets an enterprise’s infrastructure, depleting bandwidth and degrading or com-
promising online services. Such an attack is based on “the fact that we’re sharing a network experience,” Mr. Walker commented, adding, “I don’t think any of us really wants to give that up.” In an intrusion, rather than bombarding a network the attacker tries to slide into it surreptitiously in order to take control of the system—to steal proprietary information, perhaps, or to alter or delete data. Mr. Walker invited the audience to imagine a scenario in which an adversary hired a hacker to change data that a company had attested as required under the Sarbanes-Oxley Act, then blew the whistle on the victim for non-compliance. Defining malicious code, another source of attack, as “any code that engages in an unwanted and unexpected result,” he urged the audience to keep in mind that “software security is not necessarily the same thing as security software.”
Attacks also originate in what Mr. Walker called people issues. One variety, the social engineering attack, depends on getting workers to click when they shouldn’t by manipulating their curiosity or, as in the case of the woman who opened the “I Love You” virus 22 times, more complex emotions. This form of attack may not be readily amenable to technical solution, he indicated. Internal resource abuses are instances of employees’ using resources incorrectly, which can lead to a security threat. In backdoor engineering, an employee “builds a way in [to the system] to do something that they shouldn’t do.”
Proposing what he called “the best answer overall” to the problem of threats and attacks, Mr. Walker advocated layered security, which he described as a security stack that is analogous to the stack of systems. This security stack would operate from the network gateway, to the servers, to the applications that run on those servers. Thus, the mail server and database servers would be secured at their level; the devices, whether Windows or Linux or a PDA or a phone, would be secured at their level; and the content would be secured at its level (See Figure 9). Relying on any one element of security, he argued would be “the same as saying, ‘I’ve got a castle, I’ve got a moat, no one can get in.’ But when somebody comes up with a better catapult and finds a way to get around or to smash my walls, I’ve got nothing to defend myself.” The security problem, therefore, extends beyond an individual element of software.
DISCUSSION
Charles Wessner of the National Research Council asked Mr. Walker whether he believed in capital punishment for hackers and which risks could be organized governmentally.
Punishment or Reward for Hackers?
While doubting that hackers would be sentenced to death in the United States, Mr. Walker speculated that governments elsewhere might justify “extremely brutal” means of keeping hackers from their territory by citing the destruction
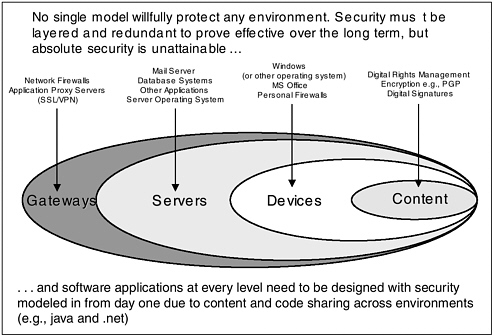
FIGURE 9 The solution: layered security.
that cyber-attacks can wreak on a national economy. He pointed to Singapore’s use of the death penalty for drug offenses as an analogue.
Following up, Dr. Wessner asked whether the more usual “punishment” for hackers wasn’t their being hired by the companies they had victimized under a negotiated agreement.
Mr. Walker assented, saying that had been true in many cases. Hackers, he noted, are not always motivated by malice; sometimes they undertake their activities to test or to demonstrate their skill. He called it unfortunate that, in the aftermath of 9/11, would-be good Samaritans may be charged with hacking if, having stumbled into a potential exploit, they inform the company in question of the weakness they have discovered.
Dr. Lam protested against imposing severe punishment on the hackers. “What happens is that somebody detects a flaw, posts that information—in fact, tells the software companies that there is such an error and gives them plenty of time to release a patch—and then this random kid out there copies the code that was distributed and puts it into an exploit.” Rejecting that the blame lies with the kid, she questioned why a company would distribute a product that is so easily tampered with in the first place.
Concurring, Mr. Walker said that, in his personal view, the market has rewarded C-level work with A-level money, so that there is no incentive to fix
flaws. He laid a portion of attacks on businesses to pranks, often perpetrated by teenagers, involving the misuse of IT tools that have been made available on the Net by their creators. He likened this activity to a practical joke he and his colleagues at a past employer would indulge in: interrupting each other’s work by sending a long packet nicknamed the “Ping of Death” that caused a co-worker’s screen to come up blue.30
The Microsoft OS Source Code Release
The panelists were asked, in view of the release some 10 days before of the Microsoft OS source code, what had been learned about: (a) “security practices in the monoculture”; (b) how this operating system is different from the code of open-source operating systems; and (c) whether Microsoft’s product meets the Carnegie Mellon standards on process and metrics.
Saying that he had already seen reports of an exploit based on what had been released, Mr. Walker cautioned that the Microsoft code that had been made public had come through “somebody else.” It might not, therefore, have come entirely from Microsoft, and it was not possible to know the levels at which it might have been tampered with. According to some comments, the code is laced with profanity and not necessarily clear; on the other hand, many who might be in a position to “help the greater world by looking at it” were not looking at it for fear of the copyright issues that might arise if they did look at it and ever worked on something related to Windows in the future.31
Dr. Lam said that she had heard that some who had seen the code said it was very poorly written, but she added that the Software Engineering Institute processes do not help all that much in establishing the quality of code; there are testing procedures in place, but the problem is very difficult.
Going back to a previous subject, she asserted that there are “very big limitations” as to what can be built using open-source methodologies. A great deal of open-source software now available—including Netscape, Mozilla, and Open Office—was originally built as proprietary software. Open source can be as much an economic as a technical solution, and it is Microsoft’s monopoly that has caused sources to be opened.




























