
2
Proposed Approach
This chapter is the core of the report. It describes an approach to the development of dependable software that the committee believes could be widely adopted, and would be more effective than the approaches that are currently in widespread use.
The proposed approach can be summarized in three key points—“the three Es”:
-
Explicit claims. No system can be dependable in all respects and under all conditions. So to be useful, a claim of dependability must be explicit. It must articulate precisely the properties the system is expected to exhibit and the assumptions about the system’s environment on which the claim is contingent. The claim should also make explicit the level of dependability claimed, preferably in quantitative terms. Different properties may be assured to different levels of dependability.
-
Evidence. For a system to be regarded as dependable, concrete evidence must be present that substantiates the dependability claim. This evidence will take the form of a “dependability case,” arguing that the required properties follow from the combination of the properties of the system itself (that is, the implementation) and the environmental assumptions. So that independent parties can evaluate it, the dependability case must be perspicuous and well-structured; as a rule of thumb, the cost of reviewing the case should be at least an order of magnitude less than the cost of constructing it. Because testing alone is usually insufficient to establish properties, the case will typically combine evidence from testing
-
with evidence from analysis. In addition, the case will inevitably involve appeals to the process by which the software was developed—for example, to argue that the software deployed in the field is the same software that was subjected to analysis or testing.
-
Expertise. Expertise—in software development, in the domain under consideration, and in the broader systems context, among other things—is necessary to achieve dependable systems. Flexibility is an important advantage of the proposed approach; in particular the developer is not required to follow any particular process or use any particular method or technology. This flexibility provides experts the freedom to employ new techniques and to tailor the approach to their application and domain. However, the requirement to produce evidence is extremely demanding and likely to stretch today’s best practices to their limit. It will therefore be essential that the developers are familiar with best practices and diverge from them only with good reason. Expertise and skill will be needed to effectively utilize the flexibility the approach provides and discern which best practices are appropriate for the system under consideration and how to apply them. This chapter contains a short catalog of best practices, judged by the committee to be those that are most important for dependability.
These notions—to be explicit, to demand and produce evidence, and to marshall expertise—are, in one sense, entirely traditional and uncontroversial. Modern engineering of physical artifacts marshals evidence for product quality by measuring items against explicit criteria, and licensing is often required in an attempt to ensure expertise. Applying these notions to software, however, is not straightforward, and many of the assumptions that underlie statistical process control (which has governed the design of production lines since the 1920s) do not hold for software. Some of the ways in software systems differ from more traditional engineering projects include the following:
-
Criteria. The criteria for physical artifacts are often simpler, often comprising no more than a failure or breakage rate for the artifact as a whole. Because of the complexity of software and its interdependence on the environment in which it operates, explicit and precise articulation of claims is both more challenging and more important than for traditional engineering.
-
Feasibility of testing. For physical artifacts, limited testing provides compelling evidence of quality, with the continuity of physical phenomena allowing widespread inferences to be drawn from only a few sample points. In contrast, limited testing of software can rarely provide compelling evidence of behavior under all conditions.
-
Process/product correlation. The fundamental premise of statistical
-
quality control is that sampling the product coming out of a process gives a measure of the quality of the process itself, which in turn will determine the quality of items that are not sampled. Although better software process can lead to better software, the correlation is not sufficiently strong to provide evidence of dependability. Unlike physical engineering, in which large classes of identical artifacts are produced, software engineering rarely produces the same artifact twice, so evidence about one software system rarely bears on another such system. And even an organization with the very best process can produce seriously flawed software.
These differences have profound implications, so that the application of standard engineering principles to software results in an approach that is far from traditional. Practitioners are likely to find the proposed approach radical in three respects. First, the articulation of explicit dependability claims suggests that software systems requirements should be structured differently, with requirements being prioritized (separating the crucial dependability properties from other desirable, but less crucial, ones) and environmental assumptions being elevated to greater prominence. Second, the standard of evidence for a system that must meet a high level of dependability cannot generally be achieved using the kind of testing regimen that is accepted by many certification schemes today. Instead, it will be necessary to show an explicit connection between the tests performed and the properties claimed; the inevitable gap will likely have to be filled by analysis. Third, constructing the dependability case after the implementation is complete will not usually be feasible. Instead, considerations of the ease of constructing the case will permeate the development, influencing the choice of features, the architecture, the implementation language, and so on, and the need to preserve the chain of evidence will call for a rigorous process. Achieving all of this will demand significant and broad-ranging expertise.
Lest the reader be concerned that the proposed approach is too risky, it should be noted that although widespread adoption of the proposed approach would be a radical change for the software industry, the constituent practices that the approach would require are far from novel and have been used successfully in complex, critical software projects for over a decade. Moreover, the underlying sensibility of the approach is consistent with the attitude advocated by the field of systems engineering—often referred to as “systems thinking”—whose validity is widely accepted and repeatedly reaffirmed by accidents and failures that occur when it is not applied.
Because the proposed approach is very different from the approach used to build most software today, it will not only require a change in mindset but will also probably demand skills that are in short supply. A radical improvement in software will therefore depend on improvements
in education (e.g., better curricula). Furthermore, the high standards imposed by this approach may not always be achievable at reasonable cost. In some cases, this will mean reducing expectations of dependability—in other words, limiting the functionality and complexity of the system. If no acceptable trade-off can be agreed upon, it may not be possible to build the system at all using today’s technology. Without major advances brought about by fundamental research, many software systems that society will want or need in the coming decade will probably be impossible to build to appropriate dependability standards. The approach advocated here is technology-neutral, so as technology advances, more effective and economical means of achieving society’s goals will become possible, and systems that cannot be built today may be feasible in the future.
EXPLICIT DEPENDABILITY CLAIMS
What Is Dependability?
Until now, this report has relied on the reader’s informal understanding of the term “dependable.” This section clarifies the way in which the term is used in the context of this report.
The list of adjectives describing the demands placed on software has grown steadily. Software must be reliable and available; usable and flexible; maintainable and adaptable; and so on. It would not be helpful simply to add “dependable” to this long list, with the meaning that a “dependable” software system is one on which the user can depend.
One could imagine, though, that demanding dependability in this broad sense from a software system is not unreasonable. After all, do not users of all kinds of nonsoftware systems demand, and obtain, dependability from them? Since the late 1970s, for example, drivers have come to expect all-round dependability from their cars. But large software systems are more complex than most other engineered systems, and while it might make sense to demand dependability from a car in its entirety, it makes less sense to demand the same of a large software system. It is clear what services are expected of a car: If the car fails in deep water, for example, few drivers would think to point to that as a lack of dependability.1 Most
large software systems, in contrast, perform a large range of complex functions in a complex and changing environment. Users are not typically aware of a system’s inherent limitations, nor can they always even detect changes in the environment that might compromise the system’s reliability.
For these reasons, the dependability of a software system cannot be judged by a simple metric. A system is dependable only with respect to particular claimed properties; unless these properties are made explicit, dependability has little meaning. Moreover, dependability is not a local property of software that can be determined module by module but has to be articulated and evaluated from a systems perspective that takes into account the context of usage. A system may be dependable even though some of its functions fail repeatedly; conversely, it may be regarded as undependable if it causes unexpected effects in its environment, even if it suffers no obvious failures. These issues are discussed in more detail below (see “Software as a System Component”).
In addition, dependability does not reside solely within a system but is also reflected in the degree of trust that its users are willing to place in it. Systems may meet all of their dependability requirements, but if users cannot be convinced that this is so, the systems will not be seen as dependable. That is, dependability is an “ability to deliver service that can justifiably be trusted,”2 and for such justification, evidence will be required.
Why Claims Must Be Explicit
With limitless resources, it might be possible to build a system that is highly dependable in all of its properties, but in practice—for systems of even minimal complexity—this will not be achievable at a reasonable cost. A key characteristic of a system designed with dependability in mind will therefore be differentiation—that is, the properties of the system will not be uniform in the confidence they warrant but, on the contrary, will be assured to (possibly dramatically) differing degrees of confidence.
It follows that the users of a system can depend on it only if they know which properties can be relied upon. In other words, the crucial properties should be explicitly articulated and made clear not only to the user, as consumer of the system, but also to the developer, as its producer. Currently, consumer software is typically sold with few explicit representations of the properties it offers or its fitness for any purpose. Apple and Adobe, for example, provide software “as is” and “with all faults” and
disclaim all warranties. Google offers “no warranties whatsoever” for its services, and Microsoft warrants only that the software will “perform substantially in accordance with the accompanying materials for a period of (ninety) 90 days.”3 Software systems that are developed specially for a particular client are typically built to meet preagreed requirements, but these requirements are often a long and undifferentiated list of detailed functions.
Software as a System Component
Engineering fields with long experience in building complex systems (for example, aerospace, chemicals, and nuclear engineering) have developed approaches based on systems thinking; these approaches focus on the properties of the system as a whole and on the interactions among its components, especially those (often neglected) between a component being constructed and the components of its environment.
Systems thinking can have impacts on component design that may surprise those who have not encountered such thinking before. For example, the designer of a component viewed in isolation may think it a good idea to provide graceful degradation in response to perceived error situations. In a systems context, however, this could have negative consequences: For example, another component might be better placed to respond to the error, but its response might be thwarted by the gracefully degraded behavior of the original component, and its own attempts to work around this degraded behavior could have further negative consequences elsewhere. It might have been better for the original component simply to have shut itself down in response to the error.
As software has come to be deployed in—indeed has enabled— increasingly complex systems, the systems aspects have come to dominate in questions of software dependability. Dependability is not an intrinsic property of software. Software is merely one component of a system and a software component may be dependable in the context of one system but not dependable in another.4
|
3 |
See, for example, warranty and disclaimer information at the following Web pages for each of the companies mentioned: <http://www.adobe.com/products/eula/warranty/> (Adobe); <http://www.apple.com/legal/sla/macosx.html> (Apple); <http://www.microsoft.com/windowsxp/home/eula.mspx> (Microsoft); and <http://desktop.google.com/eula.html> (Google). |
|
4 |
The guidance software for the Ariane 4 rocket was dependable as part of that system, but when it was reused in the Ariane 5, the assumptions about its operating environment were no longer valid, and the system failed catastrophically. J.L. Lions, 1996, “ARIANE 5: Flight 501 failure,” Report by the Inquiry Board. Available online at <http://www.cs.unibo.it/~laneve/papers/ariane5rep.html>. |
A system is not simply the sum of its components: A system causes its components to interact in ways that can be positive (producing desirable emergent behavior) or negative (often leading to surprising outcomes, including failures). Consequently, the properties of a system may not be related in a simple way to those of its components: It is possible to have a faulty system composed of correct components, and it is possible for a system correctly to achieve certain properties despite egregious flaws in its components.
Generally, what systems components should do is spelled out in their requirements and specification documents. These documents assume, but sometimes do not articulate, a certain environment. When placed in a system context, however, some of these assumptions may be violated. That is, the actual operational profile includes circumstances for which there may be no specified behavior (which means it is unclear what will happen) or for which the specified behavior is actually inappropriate. When these circumstances are encountered, failure often results. These sources of system failure are far more common, and often far more serious, than those due to simple bugs or coding errors.
People—the operators, users (and even the developers and maintainers) of a system—may also be viewed as system components. If a system meets its dependability criteria only if people act in certain ways, then those people should be regarded as part of the system, and an estimate of the probability of them behaving as required should be part of the evidence for dependability.5 For example, if airline pilots are assumed to behave in a certain way as part of the dependability claim for an aircraft, then their training and the probability of human error become part of the system dependability analysis.
Accidental Systems and Criticality Creep
Many enterprises introduce software, or software-enabled functions, into their organization without realizing that they are constructing a system or modifying an existing system. For example, a hospital may introduce a wireless network to allow physicians to access various databases from handheld PDAs and may link databases (for example, patient and pharmacy records) to better monitor for drug interactions. Those developing software to perform these integrations often encounter systems issues but may not recognize them as such. For example, they may recognize that network protocols introduce potential vulnerabilities and will consider the security of the wireless connection and the appropriate
cryptography to employ, but they may not recognize the larger systems issues of linking previously separate systems with their own security and access control policies.
As another example, emergency care units may have a dozen or more different medical devices connected to the same patient. These devices are designed and developed in isolation, but they form an accidental system (that is, a system constructed without conscious intent) whose components interact through the patient’s physiology and through the cognitive and organizational faculties of the attending physicians and nurses. Each device typically attempts to monitor and support the stabilization of some parameter (heart rate, breathing, blood chemistry) but it does so in ignorance of the others even though these parameters are physiologically coupled. The result can be suboptimal whole-body stabilization6 and legitimate concern that faults in a device, or in its operation, may propagate to other devices. Because they are designed in isolation, the devices have separate operator interfaces and may present similar information in different ways and require similar operations to be performed in different ways, thereby inviting operator errors.
A consequence of accidental system construction is that components may come to be used in contexts for which they were not designed and in which properties (typically internal failures and response to external faults) that were benign in their original context become more serious. An example is the use of desktop software in mission critical systems, as in the case of U.S.S. Yorktown, whose propulsion system failed on September 21, 1997, due to a software failure. An engineer with the Atlantic Fleet Technical Support Center attributed the failure to the integration and configuration of a commodity operating system without providing for adequate separation and process isolation.7
A more subtle but pervasive form of criticality creep occurs when the distinction between safety-critical and mission-critical features becomes blurred as users become dependent on features that they previously lived without. An avionics system, for example, might provide a moving map display—generally not flight-critical—that produces information for a pilot, on which the pilot might come to depend.
The formation of accidental systems may not always be avoidable, but it can be mitigated in two ways. The developer may be able to limit
|
6 |
See, for example, a talk given by Timothy Buchman titled “Devices, data, information, treatment: A bedside perspective from the intensive care unit” at the June 2005 High Confidence Medical Device Software and Systems Workshop in Philadelphia, Pennsylvania. More information can be found online at <http://rtg.cis.upenn.edu/hcmdss/index.php3>. |
|
7 |
See Gregory Slabodkin, 1998, “Software glitches leave Navy smart ship dead in the water,” Government Computer News, July 13. Available online at <http://www.gcn.com/print/17_17/33727-1.html>. |
the exposure of the system as a whole to failures in some components, by designing interfaces carefully. For example, if a medical device is to be integrated into a hospital-wide information system, the developer might erect firewalls in the design of the software and hardware to ensure that the critical functions of the device cannot be controlled remotely. If this is not possible, the accidental system effect can be countered by recognizing the scope of the system as a whole and ensuring that the dependability case covers it.
Evolution and Recertification
Because systems and their operating environments evolve, a system that was dependable at the time it was introduced may become undependable after some time, necessitating a review and perhaps reworking of its dependability case. This review may conclude that the system no longer meets its original dependability criteria in its new environment. If so, the system may need to be modified, replaced, withdrawn from service, or simply accepted as being undependable.
When a system has been accepted as fit to put into service and it has been in use for some time, two issues may arise. First (and most commonly) something will happen—perhaps a bug fix, or the modification of a feature, or a change to an interface—that requires that the software be changed. How should the modified system be recertified as fit for service? A modified system is a new system, and local changes may affect the behavior of unmodified parts of the system, through interactions with the modified code or even (in many programming languages) as a result of recompilation of unmodified code. The evidence for dependability should therefore be reexamined whenever the system is modified and, if the evidence is no longer compelling, new evidence of dependability should be generated and the dependability case amended to reflect the changes. Ideally, most of the dependability case will be reusable. It is also important to rerun the system test suite (including additional tests showing that any known faults have indeed been corrected) as software maintenance can subtly violate the assumptions on which the dependability case was originally based.
Second, in-service experience may show that the dependability case made incorrect assumptions about the environment. For example, a protection system for an industrial process may have the dependability requirement that it fails no more frequently than once in every thousand demands, based on an assumption that the control system would limit the calls on the protection system to no more than 10 each year. After a few months of service, it might be apparent that the protection system is being called far more often than was assumed would happen. In such cases, the
system should be taken out of service (or protected in some other way that is known to have the necessary dependability) until the dependability case has been reexamined under the new assumptions and shown to be adequate, or until sufficient additional evidence of the dependability of the protection system has been obtained.
Third, in the security case, if a new class of vulnerability is discovered, software that was understood to be secure might become vulnerable. In such a case new tests, tools, or review processes must be developed and applied, and the system updated as needed to operate in the new threat environment. The level of revision required to make the system’s security acceptable in the face of the new threat will vary depending on the scope and impact of the vulnerability.
What to Make Explicit
The considerations in the previous sections suggest two important principles regarding what should be made explicit. First, it makes no sense to talk about certifiable dependability and justifiable confidence without defining the elements of the service that must be delivered if the system is to be considered dependable. In general, this will be a subset of the complete service provided by the system: Some requirements will not be considered important with respect to dependability in the specific context under consideration. Nor will it always be necessary to guarantee conformance to these properties to the highest degree. Dependability is not necessarily something that must be applied to all aspects of a system, and a system that is certified as dependable need not work perfectly all the time. Second, any claim about a service offered by a software component will be contingent on assumptions about the environment, and these assumptions will need to be made explicit.
Stating the requirements for a particular software component will generally involve three steps:
-
The first step is to be explicit about the desired properties: to articulate the functional dependability properties precisely. These should be requirements properties expressed in terms of the expected impact of the software in its environment rather than specification properties limited to the behavior of the software at its interface with other components of the larger system (see next section).
-
The second step is to be explicit about the degree of dependence that will be placed on each property. This may be expressed as the probability of failure on demand (pfd) or per hour (pfh) or as a mean time between failures (MTBF). In general, the dependence on different properties will be different: For example, it might be tolerable for a rail signal to
-
give an incorrect “stop” command once every 10,000 hours but an incorrect “go” would be tolerated only once every 100 million hours, because the former would only cause delay, whereas the latter might cause a fatal accident.
-
The third step is to be explicit about the environmental assumptions. These assumptions will generally include a characterization of the system or systems within which the software should be dependable and particular assumed properties of those systems. These properties may be arbitrarily complex, but sometimes they may involve little more than ranges of conditions under which the system will be operating. For example, an airborne collision-avoidance system may dependably provide separation for all geometries of two conflicting aircraft approaching each other at less than Mach 1 but become undependable if the approach is at Mach 2 (because the alerts could not be given in time for effective action to be taken) or when more than two aircraft are in conflict (because resolving the conflict between two aircraft might endanger the third).
Requirements, Specifications, and Domain Assumptions
The properties of interest to the user of a system are typically located in the physical world: that a radiotherapy machine deliver a certain dose, that a telephone transmit a sound wave faithfully, that a printer make appropriate ink marks on paper, and so on. The software, on the other hand, is typically specified in terms of properties at its interfaces, which usually involve phenomena that are not of direct interest to the user: that the radiotherapy machine, telephone, or printer send or receive certain signals at certain ports, with the inputs related to the outputs according to some rules.
It is important, therefore, to distinguish the requirements of a software system, which involve properties in the physical world, from the specification of a software system, which characterizes the behavior of the software system at its interface with the environment.8 When the software system is itself only one component of a larger system, the other components in the system (including perhaps, as explained above, the people who work with the system) will be viewed as part of the environment.
One fundamental aspect of a systems perspective, as outlined in the early sections of this chapter, is paying attention to this distinction. Indeed, many failures of software systems can be attributed exactly to a
failure to recognize this distinction, in which undue emphasis was placed on the specification at the expense of the requirements. The properties that matter to the users of a system are the requirements; the properties the software developer can enforce are represented by the specification; and the gap between the two should be filled by properties of the environment itself.
The dependability properties of a software system, therefore, should be expressed as requirements, and the dependability case should demonstrate how these properties follow from the combination of the specification and the environmental assumptions.
In some cases, the requirements, specification, and environmental and domain assumptions will talk about the same set of phenomena. More often, though, the phenomena that can be directly controlled or monitored by the software system are not the same phenomena of interest to the user. A key step, therefore, in articulating the dependability properties, is to identify these sets of phenomena and classify them according to whether they lie at the interface or beyond. In large systems involving multiple components, it will be profitable to consider all the various interfaces between the components and to determine which phenomena are involved at each interface.
This viewpoint is illustrated in Figure 2.1. The outermost box represents the collection of phenomena in the world that are relevant to the problem the software is designed to address. The box labeled “machine” represents the phenomena of the software system being built (and the machine it runs on). The box labeled “environment” represents the phenomena of the components in the environment in which the software operates, including other computer systems, physical devices, and the human operators about whom assumptions are made. The box labeled “user” represents the phenomena involving the users. The gray borders of the boxes represent shared phenomena. The three spots denote archetypal phenomena. The phenomenon m is internal to the machine and invisible from outside; the instructions that execute inside the computer, for example, are such phenomena. The phenomenon s is a specification phenomenon, at the interface of the machine, shared with its environment. The phenomenon r is a requirements phenomenon, visible to the user and shared with the environment but not with the machine. This view simplifies the situation somewhat. It also shows the user as distinct from the environment, in order to emphasize that the phenomena that the user experiences (labeled r) are not generally the same as the phenomena controlled by the software (labeled s). In practice, the sets of specification and requirement phenomena overlap, and the user cannot be cleanly separated from the environment.
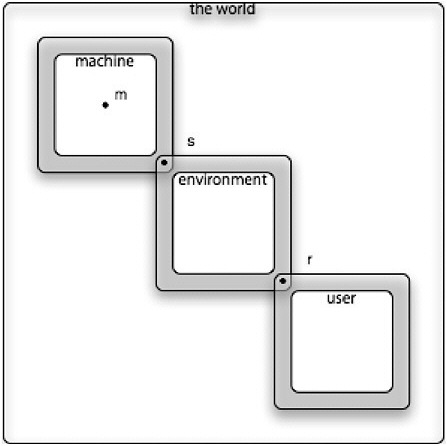
FIGURE 2.1 Specification and requirements.
The dependability case will involve m, s, and r. The argument will have two pieces. First, a correctness argument for the software will show how s follows from m: that is, how the intended properties of the software system at its interface are ensured by its implementation. Second, a specification-requirements argument will show how r follows from s: that is, how the desired requirement as observed by the user is ensured by the behavior of the software system at its interface. The correctness argument can be constructed in terms of the software alone and is entirely formal (in the sense that it does not involve any notions that cannot in principle be perfectly formalized). The specification-requirements argument, on the other hand, must combine knowledge about the software system with knowledge of the environment. In its general form, it will say that the requirements follow from the combination of the specification and the properties of the environment. This argument cannot usually be entirely
formal, because determining the properties of the environment will in general have to be an informal matter. So whereas the correctness argument is in theory amenable to mechanized checking, the specification-requirements argument will rest on assumptions about the environment that will need to be confirmed by domain experts. To illustrate the idea, here are some examples:
-
Traffic lights. The key dependability property of a traffic light system at a particular intersection is to prevent accidents. This is a requirement, and the phenomenon of two cars crashing is an example of an r. The software system interacts with the environment by receiving sensor inputs and generating control signals for the lights; these are the s phenomena. Assumptions about the environment include that the sensor and traffic light units satisfy certain specifications (for example, that a control signal sent to a traffic light will change the light in a certain way) and that the drivers behave in certain ways (for example, stopping at red lights and not in the middle of the intersection).
-
Radiotherapy. A key dependability property of a radiotherapy system is to not deliver an overdose to the patient. The phenomena r are those involving the location of the target of the beam, the dosage delivered, the identity of the patient, and so on. The software system interacts with the operator through user interfaces and with the physical devices that control and monitor the beam settings. Assumptions include that the physical devices behave in certain ways and obey commands issued to them within certain tolerances, that the patient behaves in a certain way (not moving during irradiation, for example), and that the human organization of the facility obeys certain rules (such as preventing other people from entering the treatment room when the beam is on and ensuring that the correct patient is placed on the bed).
-
Criminal records. A dependability property of a system for maintaining criminal records may be that no records are permanently lost. The phenomena r involve the records and the means by which they are created and accessed. The phenomena s at the interface of the software system might include these and, in addition, commands sent to a disk drive. The key assumptions, for example, are that the disk drive offers certain reliability guarantees and that unauthorized access to the file system is prevented. The demarcation between a software system and its environment is not always clear and will often be determined as much by economic and organizational issues as by technical ones. For example, if the criminal records system is built on top of an existing service (such as a database or replicated file system), that service will be regarded as part of the environment.
The Warsaw airport Airbus accident in September 1993 has been cited as an example of a failure to distinguish between specifications and requirements. An Airbus A320-211 came in to land in heavy winds. The aircraft aquaplaned for 9 seconds before reverse thrust was enabled, overran the runway, and collided with an embankment, killing 1 pilot and seriously injuring 2 other crew members and 51 passengers. The reverse thrust system was designed to be disabled under software control unless both left and the right landing gears were under compression, indicating contact with the ground. The software met its specification flawlessly, but unfortunately the specification did not match the desired dependability property. The crucial property, a requirement, was that reverse thrust should be disabled only when airborne, and this was certainly not satisfied. Had the dependability of the system been expressed and evaluated in terms of this property, attention might have been drawn to the domain assumption that lack of compression always accompanies being airborne, and the construction of a dependability case might have revealed that this assumption was invalid.9
The inevitable gap between specification and requirements properties speaks directly to the dependability of a service provision. At a minimum, software developers must appreciate this distinction, and as part of developing a dependable case there should be accountability for ensuring that the specification properties guarantee the requirements properties and for providing evidence (in the form of justifiable environmental assumptions) for this connection. A useful analogy may be the role of architects in the design of a new building: The architects capture the extrinsic requirements (accommodation needs, relationships between different rooms, workflow, aesthetic considerations); they add the safety requirements and regulatory requirements and, with the help of specialists such as structural engineers, convert the whole into a set of specifications that can be implemented by a construction firm. The architects accept responsibility and accountability for the relationship between extrinsic and intrinsic requirements.
The idea of distinguishing requirements from specifications is not new. In process control, the need to express requirements in terms of observable, extrinsic properties has long been recognized and was codified
|
9 |
The official report of this incident has been translated by Peter Ladkin and can be found online (see below). Interestingly, although the report notes in its recommendations the deficiencies of the software, it attributes the cause of the accident to the flight crew, blaming them for not aborting the landing. See Peter Ladkin, transcriber, 1994, “Transcription of report on the accident to Airbus A320-211 aircraft in Warsaw on 14 September 1993,” Main Commission, Aircraft Accident Investigation, Warsaw. Available online at <http://www.rvs.uni-bielefeld.de/publications/Incidents/DOCS/ComAndRep/Warsaw/warsaw-report.html>. |
in Parnas’s four-variable model.10 It distinguishes the specification phenomena—the inputs and outputs of the machine—from the requirements phenomena—the monitored and controlled variables—thus accounting for the imperfections of the monitors and actuators that mediate between the machine and the environment. Recent work has extended this to systems of more general structure.11
EVIDENCE
A user should not depend on a system without some evidence that confidence is justified. Dependability and evidence of dependability are thus inseparable, and a system whose dependability is unknown cannot be regarded as dependable. In general, it will not be feasible to generate strong evidence for a system’s dependability after it is built (but before deployment); the evidence will need to be produced as part of the development process. Beta-testing, controlled release, and other field-testing strategies may provide some evidence that software is acceptably dependable in applications that only require low dependability, but even in these less-critical applications, the evidence obtained through field-testing will rarely be sufficient to provide high confidence that the software has the required properties.
Goal-Based Versus Process-Based Assurance
To date, most approaches to developing dependable software (i.e., traditional approaches) have relied on fixed prescriptions, in which particular processes are applied and from which dependability is assumed to follow. The approach recommended in this report might be characterized in contrast as goal-based.
Even if a system has the same components and design as some other system, it is likely to be unique in its context of use and in the concerns of its stakeholders. For this reason, assurance for systems by reference to some fixed prescription is no longer advocated; instead, a goal-based approach is preferred. In a goal-based approach, the stakeholders first agree on the goals for which assurance is required (for example, “this device must not harm people”); then the developers produce specific claims (for example, “the radiation delivered by this device will never
exceed so much intensity”) and an argument to justify the claims based on verifiable evidence (for example, “there is a mechanical interlock on the beam intensity and here is evidence, derived from extensive testing, that it works”). The top levels of the argument will generally employ methods from systems thinking, such as hazard analysis, fault tree analysis, and failure modes and effects analysis, while lower levels will employ more specialized techniques appropriate to the system and technology concerned.
Process-based assurance will typically mandate (or strongly recommend) the processes that the developers must follow to support a claim for a particular level of dependability. For example, the avionics standard DO-178 mandates modified condition/decision coverage (MCDC) testing—described in Chapter 1—for the most critical software. This can lead to a culture where software producers follow the standard and then claim that their software has achieved the required dependability without providing any direct evidence that the resulting product actually has the required properties. In contrast, goal-based standards require the developers to state their dependability targets and to justify why these are adequate for the application, and then to choose development and assurance methods and to show how these methods provide sufficient evidence that the dependability targets have been achieved. Goal-based assurance will usually provide a far stronger dependability case than process-based assurance.
Another advantage of goal-based assurance cases over more prescriptive methods for assurance is that they allow expert developers to choose suitable solutions to novel design problems. In addition, goal-based assurance approaches are able to keep pace with technological change and with the attendant changes in system functions and hazards along with the goals of their stakeholders. As noted earlier, the increased flexibility demands expertise and judgment in discerning what technological and process approaches are best suited in a given circumstances to meet explicit requirements and develop the evidence needed for an ultimate dependability case.
In short, then, as explained above, the developers make explicit claims about the dependability properties of the delivered system. For these claims to be useful to the consumers of the system, the developers present, along with the claims, a dependability case arguing that the system has the claimed properties. Such an approach is only useful to the extent that the claims can be substantiated by the dependability case, and that the case is convincing. It therefore requires transparency so that the consumer (broadly construed) can assess the case’s credibility and accountability to discourage misrepresentation.
The Dependability Case
Dependability requires justifiable confidence, which in turn requires that there be adequate evidence to support the claims of dependability, and that this evidence be available to those who have to assess the degree of confidence that the evidence supports. Claims for certifiably dependable software should therefore be not only explicit but also backed by sufficient evidence, and this evidence should be open to inspection and analysis by those assessing the dependability case.
What constitutes sufficient evidence for dependability depends on the nature of the claim and the degree of dependability that is required. In general, however, the evidence will constitute a dependability case that takes into account all components of the system as a whole: the software, physical devices with which it interacts, and assumptions about the domain in which it operates (which will usually include both assumptions about the physical environment and assumptions about the behavior of human operators).
Of course, the construction of those parts of the dependability case that go beyond the software may require skills and knowledge beyond those of the software engineer and may be relegated to domain experts. But it is vital that the software engineer still be responsible for ensuring not only that the part of the case involving software is sound, but also that it is used appropriately in the larger case.
The Role of Domain Assumptions
As explained in the preceding section, a dependability claim for a system should be made in terms of requirements that involve the phenomena of the environment; it is to affect these phenomena that the system is introduced in the first place. The software itself, on the other hand, is judged against a specification that involves only phenomena at the interface of the machine and the environment, which the software is capable of controlling directly.
Between the requirements and the specification lie domain assumptions. A dependability case will generally involve a statement of domain assumptions, along with their justifications, and an argument that the specification of the software and the domain assumptions together imply the requirements. Insisting on this tripartite division of responsibility— checking the software, checking the domain assumptions, and checking that they have the correct combined effect—is not a pedantry. As the Warsaw Airbus incident illustrates, the meeting point of these three components of the dependability case is often a system’s Achilles’ heel.
The Role of Architecture
The demand for evidence of dependability and the difficulty of producing such evidence for complex systems have a straightforward but profound implication. Any component for which compelling evidence of dependability has been constructed at reasonable cost will likely be small by the standards of most modern software systems. Every critical specification property, therefore, will have to be assured by one, or at most a few, small components. Sometimes it will not be possible to separate concerns so cleanly, and in that case, the dependability case will be less credible or more expensive to produce.
The case that the system satisfies a property has three parts:
-
An argument that the requirements properties will be satisfied by the specification of the system, in conjunction with the domain assumptions. As explained above, this requires that the domain assumptions are made explicit and shown to be justified. For example, the specification of a controller that is used to maintain a safe level in a reservoir may depend on assumptions about signals from sensors, the behavior of valves, and the flow rate through outflow pipes under a range of operational conditions. These assumptions should be stated and reviewed by domain experts and may need to be tested under operational conditions to achieve the necessary confidence that they are correct.
-
An independence argument, based on architectural principles, that only certain components are relevant. The independence argument will rely on properties of both the particular architecture and the language and implementation platform on which it stands. The easiest case will be where the components are physically separated, for example by running on separate processors with no shared memory. Where the components share memory, unless they use a safe, well-defined language and a robust, fully specified platform, such an argument will not be possible. For example, if the language allows arbitrary integers to be used as if they were pointers to variables (as in C), it will not be possible to argue that the regions of memory read and written by distinct modules are disjoint, so even modules implementing functionality unrelated to the property at issue would have to be treated as relevant. These shortcomings might be overcome, but only at considerable cost. For example, memory safety could be established by restricting the code to a subset that disallows certain constructs and then performing a review, preferably with the aid of automated tools, to ensure that the restriction has been obeyed.
-
A more detailed argument that the components behave appropriately. This argument is likely to involve analysis of the specification for completeness and consistency, analysis of the design to show conformance with the specification, and analysis of the implemented software to show
-
consistency with the design and the absence of unsafe properties (such as memory faults or the use of undefined values). The components, subsystems, and system will then usually be tested to provide some end-to-end assurance.
The degree of coupling between components, in the form of dependences that cause one component to rely on another, is likely to be a good indicator of the effort that will be required to construct a dependability argument. In general, the more dependences and the stronger the dependences, the more components will need to be considered and the more detailed their specifications will need to be, even to establish a limited property.
The Role of Testing
Testing is indispensable, and no software system can be regarded as dependable if it has not been extensively tested, even if its correctness has been proven mathematically. Testing can find flaws that elude analysis because it exercises the system in its entirety, where analysis must typically make assumptions about the execution platform that may turn out to be unwarranted. Human observation of an executing system, especially one that interacts heavily with a user, can also reveal serious flaws in the user interface, and even in the formulation of the dependability properties themselves.
Testing plays two distinct roles in software development. In the first role, testing is an integral component of the software development process. Automatic tests, run every time a change is made to the code, have proven to be extremely effective at catching faults unwittingly introduced during maintenance. If code is frequently refactored (that is, if code is modified to simplify its structure without changing its functionality) retesting is especially important. When a fault is found in the code, standard practice requires the construction of a regression test to ensure that the fault is not reintroduced later. Having programmers develop unit tests for their own modules encourages them to pay attention to specifications and can eliminate faults that would be more expensive to detect after integration. (There is some evidence, however, that unit tests are not particularly effective or necessary if code is developed from a formal specification and is subject to static analysis.12)
Testing is often an inexpensive way to catch major flaws, especially in areas (such as user interfaces) where analysis is awkward. A skillfully
constructed test suite can also find faults that would rarely fail in service but in ways difficult to diagnose; experienced programmers, for example, will insert diagnostics into concurrent code in patterns that are likely to expose data races and deadlocks. “Fuzz testing,” in which a program is subjected to a huge suite of randomly generated test cases, often reveals faults that have escaped detection in other ways. The power of testing can be greatly amplified if formal models, even very partial ones, are available; tests can be generated automatically from state machine models using a technique known as “model-based testing” and from invariants or run-time assertions.
As Dijkstra observed, however, testing can reveal the presence of errors but not their absence.13 The theoretical inadequacies of testing are well known. To test a program exhaustively would involve testing all possible inputs in all possible combinations and, if the program maintains any data from previous executions, all possible sequences of tests. This is clearly not feasible for most programs, and since software lacks the continuity of physical systems that allow inferences to be drawn from one sample execution about neighboring points, testing says little or nothing about the cases that were not exercised. Because state space14 coverage is unattainable and hard even to measure, less ambitious forms of coverage have been invented, such as “all-statements” (in which every statement of the program must be executed at least once), “all-branches” (in which every branch in the control flow must be taken), and a variety of predicate coverage criteria (in which the aim is to achieve combinations of logical outcomes from the expressions that comprise the condition of each loop or if-statement). Testing researchers established early on that many of the intuitions that a tester might have that give confidence in the value of coverage are incorrect—for example, a coverage criterion that is stricter (in the sense that it rejects a larger set of test suites as inadequate) is not necessarily more effective at finding faults.15 Moreover, a recent study showed that even the predicate coverage criterion known as MCDC (used
widely in avionics and regarded as extremely burdensome) does not ensure the detection of a class of bugs found easily by static analysis.16
As Hoare has noted,17 testing is, in practice, “more effective than it has any right to be” in improving the quality and dependability of software. Hoare’s explanation is that while the contribution of testing to exposing bugs might only account for low levels of dependability, its contribution to providing feedback on the development process might account for much higher levels. In Hoare’s words: “The real value of tests is not that they detect bugs in the code but that they detect inadequacies in the methods, concentration, and skills of those who design and produce the code.” The most conscientious development teams indeed use testing in this manner. When a module or subsystem fails too many tests, the developers do not simply attempt to patch the code. Instead, they look to the development process to determine where the error was introduced that eventually resulted in the failure, and they make the correction there. This might involve clarifying requirements or specifications, reworking a design, recoding one or more modules from scratch, and, in extreme cases, abandoning the entire development and starting afresh.
In short, testing is a powerful and indispensable tool, and a development that lacks systematic testing should not be regarded as acceptable in any professional setting, let alone for critical systems. How a software supplier uses testing is important information in assessing the credibility of its dependability claims (see the discussion of transparency in Chapter 3).
The second role of testing is in providing concrete evidence that can be used in a dependability case. Testing is an essential complement to analysis. Because the activities of testing differ so markedly from those involved in analysis, testing provides important redundancy and can catch mistakes made during the analysis process, whether by humans or tools. The dependability case for an extrinsic property will often rely on assumptions about a physical device, which will be represented as a formal model for the purpose of analysis. Such formal models should obviously be tested—ideally before they are used as the basis for development. A patient monitoring system, for example, might assume certain properties of accuracy and responsiveness for the monitoring devices; the case for the system as a whole will require these to be substantiated by extensive and rigorous testing, ideally not only by the suppliers of the
devices but also by the developers of the system that uses them. End-to-end tests are especially important to catch interactions and couplings that may not have been predicted. In a radiotherapy system, for example, the beam would be examined with a dosimeter to ensure that the physical dose delivered at the nozzle matches the prescribed dose entered earlier at the therapist’s workstation.
At the same time, it is important to realize that testing alone is very rarely sufficient to establish high levels of dependability. Testing will be an essential component of a dependability case but will not in general suffice, because even the largest test suites typically used will not exercise enough paths to provide evidence that the software is correct and have little statistical significance for the levels of confidence usually desired. It is erroneous to believe that a rigorous development process in which testing and code review are the only verification techniques would justify claims of extraordinarily high levels of dependability. Some certification schemes, for example, associate higher “safety integrity levels” with more burdensome process prescriptions and imply that following the processes recommended for the highest integrity levels gives confidence that the failure rate will be less than 1 failure per 1 billion hours. Such claims have no scientific basis.
Furthermore, unless a system is very small or has been meticulously developed bearing in mind the construction of a dependability case, credible claims of dependability are usually impossible or impractically expensive to demonstrate after design and development of the system have been completed.18
Another form of evidence that is widely used in dependability claims for a component or system to be used in a critical setting is its prior extensive use. In fact, the internal state space of a complex software system may be so large that even several years’ worth of execution by millions of users cannot be assumed to achieve complete coverage. A new environment might expose unknown vulnerabilities in a component. Components designed for use in commercial, low-criticality contexts are not suitable for critical settings unless justified by an explicit dependability case that places only appropriate weight on previous successful uses.
Testing offered as part of a dependability case, like all other components of the dependability case, should be carefully justified. Since the purpose of the dependability case is to establish the critical properties of the system, the degree of confidence warranted by the testing will vary
according to the strength of the connection between the tests and the properties claimed. At one extreme, if a component can be tested exhaustively for all possible inputs, testing becomes tantamount to proof, giving very high confidence. At the other extreme, execution of even a large set of end-to-end tests, even if it achieves high levels of code coverage, in itself says little about the dependability of the system as a whole.
It cannot be stressed too much that for testing to be a credible component of a dependability case, the relationship between testing and the properties claimed will need to be explicitly justified. The tester may appeal to known properties of the internals of the system or to a statistical analysis involving the system’s operational profile. In many cases, the justification will necessarily involve an argument based on experience—for example, that attaining a certain coverage level has in the past led to certain measured failure rates. That experience should be carefully evaluated. Sometimes, the test suite itself may be treated as direct evidence for dependability. For a standard test suite (such as the Java Compatibility Kit used for testing implementations of the Java platform19), it will be possible to base the degree of confidence on the opinions of experts familiar with the suite. But a custom test suite, however credible, may place an unreasonable burden on those assessing the dependability case.
Until major advances are made, therefore, testing should be regarded in general as only a limited means of finding flaws, and the evidence of a clean testing run should carry weight in a dependability argument only to the extent that its implications for critical properties can be explicitly justified.
The Role of Analysis
Because testing alone is insufficient, for the foreseeable future the dependability claim will also require evidence produced by analysis. Moreover, because analysis links the software artifacts directly to the claimed properties, for the highest levels of dependability, the analysis component of the dependability case will usually contribute confidence at lower cost.
Analysis may involve well-reasoned informal argument, formal proofs of code correctness, and mechanical inference (as performed, for example, by “type checkers” that confirm that every use of each variable in a program is consistent with the properties that the variables were defined to have). Indeed, the dependability case for even a relatively simple system will usually require all of these kinds of analysis, and they will need to be fitted together into a coherent whole.
|
19 |
For more information on the Java Compatibility Kit, see <https://jck.dev.java.net/>. |
Type checking, for example, may be used to establish the independence of modules; known properties of the operating system may be used to justify the assumption that address space separation is sound; modular correctness proofs used to establish that, under these assumptions, the software satisfies its intrinsic specifications; and informal argument, perhaps augmented with some formal reasoning, to make the link to the crucial extrinsic properties.
An argument taking the form of a chain of reasoning cannot be stronger than its weakest link. (Recent research20 on combining diverse arguments opens the possibility that independent, weak arguments for the dependability of a system could some day be combined to provide a quantifiably stronger argument.) It will therefore be necessary to ensure that the tools and notations used to construct and check the argument are robust. If they are not, extraordinary efforts will be required to overcome their limitations. For example, if a language is used that does not require that the allowable properties of every program object are tightly defined and enforced (i.e., a “type-unsafe” or “weakly typed” language), a separate, explicit argument will need to be constructed to ensure that there are no violations of memory discipline that would compromise modular reasoning. If the programming language has constructs that are not precisely defined, or that result in compiler-dependent behavior, it will be necessary to restrict programmers to a suitable subset that is immune to the known problems.
As noted in Chapter 1, there are difficulties and limits to contemporary software analysis methods, owing in part to the need for a highly trained and competent software development staff. Indeed, the quality of the staff is at least as important as the development methods and tools that are used, and so these factors should also be included in the evidence.
Rigorous Process: Preserving the Chain of Evidence
Although it might be possible to construct a dependability case after the fact, in practice it will probably only be achievable if the software is built with the dependability case in mind. Each step in developing the software needs to preserve the chain of evidence on which will be based the argument that the resulting system is dependable.
At the start, the domain assumptions and the required properties of the system should be made explicit; they should be expressed unambigu-
ously and in a form that permits systematic analysis to ensure that there are no unresolvable conflicts between the required properties. Because each subsequent stage of development should preserve the evidence chain that these properties have been carried forward without being corrupted, each form in which the design or implementation requirements are expressed should support sufficient checking that the required properties have been preserved.
What is sufficient will vary with the required dependability, but preserving the evidence chain necessitates that the checks are carried out in a disciplined way, following a documented procedure and leaving auditable records—in other words, a rigorous process. For example, if the dependability argument relies, in part, on reasoning from the properties of components, then the system build process should leave evidence that the system has been built out of the specific versions of each component for which there is evidence that the component has the necessary properties. This can be thought of as “rigorous configuration management.”
Components and Reuse
Complex components are seldom furnished with the information needed to support dependability arguments for the systems that use them. For use within a larger argument, the details of the dependability case of a component need not be known (and might involve proprietary details of the component’s design). But the claims made for a component should be known and clearly understood, and it should be possible to assess their credibility by, for example, the reputation of a third-party reviewer (in much the same way as the FAA credibly assures the airworthiness of aircraft) or the nature of the evidence.
Not all systems and not all properties are equally critical, and not all the components in a system need assurance to the same level: for example, we may demand that one component can fail to satisfy some property no more than one time in a billion, while for another property we might tolerate one failure in a thousand. Until recently, there has been little demand for components to be delivered with the claims, argument, and evidence needed to support the dependability case for a system that uses the component. At lower levels of criticality, and in accidental systems, explicit dependability cases have seldom been constructed, so there has been no perceived need for component-level cases. At the other extreme, systems with highly critical assurance goals (such as airplanes) have driven their dependability cases down into the details of their components and have lacked regulatory mechanisms to support use of prequalified critical components, which would allow the case for the larger system
to use the case for its components without inquiring into all the details of the components themselves.
With greater reuse of components, and a concomitant awareness of the risks involved (especially of using commodity operating systems in critical settings), component-level assurance will become an essential activity throughout the industry. In the case of critical systems such as airplanes, it used to be the case that their software was built on highly idiosyncratic platforms that were seldom reused from one airplane to the next, and the same was true of the architectural frameworks that tie multiple computer systems and buses together to support fault-tolerant functions such as autopilot, autoland, flight management, and so on. Nowadays, however, the software is generally built on real-time operating systems such as LynxOS-178 that are highly specialized but nonetheless standardized components, and standardized architectural frameworks such as Primus Epic and the Time-Triggered Architecture (TTA) have emerged to support Integrated Modular Avionics (IMA).
To support these developments, the FAA developed an advisory circular on reusable software components,21 and guidelines for IMA have been developed by the appropriate technical bodies (SC200 of RTCA and WG60 of EUROCAE) and are currently being voted on. Both of these developments are rather limited, however, in that they allow only for a software component that has been used in the traditional assurance case for a certified airplane to take the assurance data developed in that certification into the assurance case for additional airplanes; they fall short of allowing the assurance case for a system to build on the assurance cases for its components.
In the case of less-critical systems, much attention has been focused recently on the use of commercial off-the-shelf (COTS) subsystems and software of uncertain pedigree/unknown provenance (SOUP). While the attention has focused mostly on the use of architectural mechanisms (for example, wrappers) to mitigate the unknown (un)reliability of these components, it has also highlighted the lack of assurance data for these components: It matters less that they are unreliable than that it is unknown how unreliable they are, and in what ways their unreliability is manifested.
Accidental systems often use COTS and SOUP and do so in contexts that promote criticality creep (see previous discussion). If these cases were recognized appropriately as systems and subjected to an appropriate dependability regime, the cost of providing adequate dependability
|
21 |
Federal Aviation Administration (FAA), 2004, “Reusable software components,” AC 20-148, FAA, Washington, D.C. Available online at <http://www.airweb.faa.gov/Regulatory_and_Guidance_Library/rgAdvisoryCircular.nsf/0/EBFCCB29C0E78FFF86256F6300617BDD?OpenDocument>. |
evidence for the COTS/SOUP component might exceed the cost of developing a new component when high dependability is required.
It is apparent that at all levels of criticality it is currently impossible to develop dependability cases for systems based solely on those cases for their components. In the case of critical systems such as airplanes this is mostly because the regulatory framework does not allow it, in part because the science base does not yet provide the ability to reason about system-level properties such as safety or security based solely on the properties of the system’s components. In the case of less critical and accidental systems, it is often because such systems rely on COTS and SOUP, for which no suitable assurance data are available.
EXPERTISE
Building software is hard; building dependable software is harder. Although the approach advocated in this report is designed to be as free as possible from the fetters of particular technologies, it also assumes that developers are using the very best techniques and tools available. A development team that is unfamiliar and inexperienced with best practices is very unlikely to succeed.
This section therefore contains an outline of some of today’s best practices. It might be used in many ways: for educational planning, for assessing development organizations, for evaluating potential recruits, and even as the basis for licensing. However, the committee offers the outline only as guidance and would not want it to be seen as binding in all circumstances. Few best practices have universal application, and most need to be adjusted to the context of a particular problem.
Different problems and different development contexts call for different practices. Moreover, what is considered to be best practice changes over time, as new languages and tools appear and ideas about how to develop software continue to mature. The committee therefore felt it would be unwise to tie its recommendations to particular practices. In addition, merely applying a set of best practices absent a carefully constructed dependability case does not warrant confidence in the system’s dependability.
At the same time, in order to make concrete the importance of best practices, the committee decided to offer a list of practices that it regards as representative of a broad consensus at the time of writing. It also seemed desirable to provide some guidance regarding today’s best practices, especially since developers in smaller organizations are often unaware of simple practices that can dramatically improve software quality.
This section begins with a discussion of simplicity, because a commitment to simplicity is key to achieving justifiable confidence and depend-
able software. A commitment to simplicity is often the mark of true expertise. The list of particular best practices that follows this discussion is by no means exhaustive. It represents the consensus of the committee on a core set of practices that can be widely applied and that can bring dramatic benefit at relatively low cost. For the most part, these practices represent minimal standards of software engineering. In some cases, for development of a noncritical system in which high dependablity is not required, less stringent practices may make sense, as noted in the list.
Simplicity
The price of reliability is the pursuit of the utmost simplicity. It is a price which the very rich find most hard to pay.22
In practice, the key to achieving dependability at reasonable cost is a serious and sustained commitment to simplicity. An awareness of the need for simplicity usually comes only with bitter experience and the humility gained from years of practice. Moreover, the ability to achieve simplicity likewise comes from experience. As Alan Perlis said, “Simplicity does not precede complexity, but follows it.”23
The most important form of simplicity is that produced by independence, in which particular system-level properties are guaranteed by individual components, much smaller than the system as a whole, whose preservation of these properties is immune to failures in the rest of the system. Independence can be established in the overall design of the system with the support of architectural mechanisms. Its effect is to dramatically reduce the cost of constructing a dependability case for a property, since only a relatively small part of the system needs to be considered. Where independence is not possible, well-formed dependence is critical. Independence allows the isolation of safe critical functions to a small number of components. Well-formed dependence (wherein a less-critical service may depend on a critical service but not vice versa) allows critical services to be safely used by the rest of the system. Independence and well-formed dependence are important design principles of overall system architecture. Simplicity has wider applications, however, which the rest of this section discusses.
A major attraction of software as an implementation medium is its capacity for complexity. Functions that are hard, expensive, or impossible
|
22 |
C.A.R. Hoare, 1981, “The emperor’s old clothes” (Turing Award Lecture), Communications of the ACM 24(2):75-83. Available online at <http://portal.acm.org/citation.cfm?id=358561>. |
|
23 |
Alan J. Perlis, 1982, “Epigrams on programming,” SIGPLAN Notices 17(9):7-13. |
to implement by other means (whether automatically in physical devices or manually in human organizations) can often be realized at low cost in software. Indeed, the marginal cost of complexity in software can seem negligible, as the cost of computational resources drops. In fact, however, complexity can inflict large costs. When a software system grows as new and more complex functions are added, its structure tends to deteriorate, and each new modification becomes harder to perform, requiring more parts of the code to be changed. It is not uncommon for a system to collapse under the weight of its own complexity.24
Developers usually cannot shield the user from the complexity of software. As the specification becomes more complex, it typically loses any coherence it once possessed. The user has no intelligible conceptual model of the system’s behavior and can obtain predictable results only by sticking to well-tried scenarios.
Complexity has, of course, a legitimate role. After all, software is often used precisely to satisfy the need for complex functions that are more cheaply and reliably implemented by software than by other means, mechanical or human. But complexity exacts a heavy price. The more complex a system is, the less well it is understood by its developers and the harder it is to test, review, and analyze. Moreover, complex systems are likely to consist of complex individual components. Complex individual components are more likely to fail individually than simpler components and more likely to suffer from unanticipated interactions. These interactions are most serious amongst systems and between systems and their human users; in many accidents (for example, at Three Mile Island25), users unwittingly took a system toward catastrophe because they were unable to understand what the system was doing.
Whether a system’s complexity is warranted is, of course, a difficult judgment, and systems serving more users and offering more powerful functionality will generally be more complex. Moreover, the demand for dependability itself tends to increase complexity in some areas. For example, a system may require a very robust storage facility for its data. This will inevitably make the system more complex than one in which data loss can be tolerated. But the lesson of simplicity still applies, and a designer committed to simplicity would choose, for example, a standard replication scheme over a more complicated and ad hoc design that attempts to exploit the particular properties of the data.
The overriding importance of simplicity in software development has been championed for decades. Formal methods researchers, such as Hoare (quoted above), were among the first to stress its value because they discovered early that extra complexity rapidly destroys the ability to generate evidence for dependability. Many practitioners have argued that the complexity of software is inherent to the task at hand, but this position has eroded, and views such as those reflected in the dicta of agile methodologies—“you aren’t gonna need it” and “the simplest thing that works”—are gaining ground.
There is no alternative to simplicity. Advances in technology or development methods will not make simplicity redundant; on the contrary, they will give it greater leverage. To achieve high levels of dependability in the foreseeable future, striving for simplicity is likely to be by far the most cost-effective of all interventions. Simplicity is not easy or cheap, but its rewards far outweigh its costs.
Here are some examples of how a commitment to simplicity can be demonstrated throughout the stages of a development:
-
Requirements. A development should start with a carefully chosen, minimal set of requirements. Complex features often exact a cost that greatly exceeds the benefit they bring to users. The key to simplicity in requirements is the construction of abstractions and generalizations that allow simple, uniform functions to be used for multiple purposes. Overgeneralization, of course, can itself be a source of gratuitous complexity but can usually be recognized because it makes the requirements more, not less, complicated.
-
Architecture. Small and simple components are easier to reason about and less likely to harbor subtle bugs. Simple and clean interfaces reduce the risk of misunderstandings between members of the development team and reduce the incidence of complex interactions, which are the most common cause of bugs in large systems. It is a mistake to believe that richer interfaces with a larger array of more elaborate functions benefit the users of the interface; on the contrary, they tend to be less useful and perform more poorly.26 A dependence graph of the code showing which other modules each module depends on can reveal sources of architectural complexity, indicating where layering is violated, where low-level modules depend on high-level ones, where cycles prevent modular reasoning, or where simply a proliferation of dependences suggests a breakdown of the original design.
|
26 |
Butler Lampson, 1983, “Hints for computer system design,” ACM Operating Systems Review 17(5):33-48. (Reprinted in IEEE Software 1(1):11-28. Available online at <http://research.microsoft.com/lampson/33-Hints/WebPage.html>.) |
-
Trusted base. If the dependability properties of a system can be confined to a small trusted base consisting of only a few components so that the properties can be guaranteed without analyzing the rest of the system (except perhaps to establish certain noninterference properties), powerful techniques such as program verification, which would not be feasible for the system as a whole, can be applied locally to provide a level of confidence not attainable by any other means.
-
Languages. Complex development languages can undermine a development by making even a simple design appear complex and by introducing new opportunities for error. Developers should be wary of complex and poorly defined modeling languages27 and of programming languages with imprecise semantics, or semantics that are platform- or compiler-dependent. When other factors dictate the use of an overly complex language, simplicity can often be regained by restricting usage to a well-defined and robust subset (such as the SPARK subset of Ada).28
-
Tools. Developers should favor simple tools and should be especially wary of code generation tools whose behavior is poorly understood. Tools that perform elaborate functions may need to be complex, but understanding how to use them and assessing their output should not be complex. A code verification tool, for example, might have complex analysis functions, but it should report its results in an intelligible fashion and, ideally, produce a proof that can be independently checked by a simpler tool.
-
Process. A rigorous process is essential to constructing a dependability case, but an elaborate and complex process that places a heavy burden on developers can be worse than no process at all. Excessive documentation is particularly problematic; it diverts attention from more important matters and is usually write-only. A common tendency is to set elaborate standards in trivial areas: Some organizations, for example, have coding standards that specify meticulously how various constructs should be formatted (a task that should be carried out by an editing tool) but fail to address the major weaknesses of the programming language.
Best Practices
The following subsections describe some of today’s specific system-level, code- and module-level, and process-level best practices.
System-Level Practices
The committee offers a set of system-level best practices below.
-
Prioritization of requirements. Prioritize requirements and articulate them simply and directly in terms of key properties rather than as a long list of functions, features, or scenarios.
-
Requirements vs. specifications. The requirements of a software system should describe the intended effect of the system on its environment and not, more narrowly, the behavior of the system at its interface with the environment, which is the subject of the specification.
-
Realistic demands. Do not include requirements that are unrealistic or that cannot be realistically assessed. In particular, vague numerical measures are not a substitute for precise requirements: The requirement of “six 9s availability,” for example, makes little sense without a clear articulation of which service is being provided and what constitutes availability or lack thereof.
-
Environmental assumptions. In the requirements document, clearly separate the demands on the software system being constructed from the demands on the environment or its operators. Include an explicit description of the environment, with a glossary that covers the domain-specific terms used throughout the document. Articulate precisely and fully any environmental assumptions and have them reviewed by domain experts.
-
Hazard analysis. For a critical application, perform a hazard analysis that identifies the most likely hazards and checks that they have been mitigated appropriately. Address security risks by building and evaluating explicit threat models.
-
Dependability case. For a critical application, construct a dependability case that explains why the system executing in context is likely to satisfy the prioritized requirements.
-
Usability testing. Apply usability testing to user interfaces in the early phases of development and periodically from then on.
-
Formal modeling and analysis. Express requirements and specifications precisely and unambiguously. An effective way to do this is to use a formal notation. For a noncritical system, a complete formal model will not generally be cost-effective, but it will usually be feasible and desirable to express at least the most important elements formally.
-
Analysis tools. Exploit automatic analysis tools to find defects in requirements and specifications documents and to increase confidence in
-
their correctness. In noncritical developments this may involve little more than using tools that check for consistent use of names. In critical developments, use tools that offer deeper analysis, such as model checkers and simulators.
-
Standard solutions. Adopt standard solutions for algorithms and protocols unless a strong case has been made for deviating from standard practice. Avoid inventing algorithms in areas that are known to be extremely hard to design correctly (for example, distributed consensus, authentication, fault tolerance). If the standard solution seems not to apply, consult an expert.
Code- and Module-Level Practices
Other best practices would apply at the code and module levels:
-
Interfaces. Design interfaces between modules that are small and well-defined. Exploit programming language mechanisms to express the module structure and check it at compile time. Specify all public interfaces fully and integrate the specifications with the code, using, for example, a tool such as Javadoc.29
-
Data abstraction. Minimize the scope and accessibility of all program components. Hide the representation of data using data abstraction, and use programming language mechanisms to enforce it. Make data types immutable whenever possible.
-
Inheritance. Inheritance is a powerful but dangerous programming feature. Use it sparingly, and whenever possible favor composition (adding functionality by embedding one object explicitly in another) over inheritance. Design for inheritance or prohibit it, and do not extend classes that were not designed with extension in mind. In critical applications, avoid inheritance or ensure that adequate time has been allowed for the extensive additional verification activity that will be required.
-
Module dependences. Evaluate the code structure by constructing a module dependence diagram (preferably with an automated tool), and modify the code to eliminate complex or troublesome dependences (especially those violating layering, and those forming cycles).
-
Standard libraries. Use standard libraries unless (1) sufficiently robust libraries are not available for the functionality desired or (2) a much smaller and simpler library can be constructed for the problem at hand using published and peer-reviewed algorithms.
|
29 |
For more information about the Javadoc tool, see <http://java.sun.com/j2se/javadoc/>. |
-
Safe language. Use a safe programming language where feasible and exploit the features that amplify static type checking (such as generics). Avoid extralinguistic or borderline features (such as native methods, reflection, and serialization). Know and avoid the traps and pitfalls of the platform. For a critical application, consider using a robust subset of the language (e.g., MISRA-C and SPARK); using an unsafe language (such as C) is unacceptable unless extraordinary measures (such as proof of type correctness) have been taken to mitigate the risks.30
-
Coding standards. Establish clear and simple coding standards to enforce good practices in the use of programming language features.31 Conventions for naming and layout are useful, especially because they amplify the power of simple lexical tools, but they are secondary to standards that have a direct impact on dependability. Appropriate coding standards are especially effective at eliminating security vulnerabilities.
-
Defensive programming. Make liberal use of runtime assertions to detect flaws in the code and incorrect environmental assumptions, and disable them in the deployed code only after careful consideration. Assertions that embody preconditions, postconditions, and representation invariants are especially effective.
-
Logging failures. Generate a log of messages that record in detail the circumstances of any detected failure that occurs at runtime. The message log should be examined frequently even if there are no serious failures and should be archived for later analysis.
-
Testing. Automate testing, especially for regressions. Use tools to measure test coverage and aim to achieve full coverage of all statements.
-
Every method of an exported application programming interface (API) should be tested. Do not regard testing as a tool to eliminate errors; instead, regard it as a quality control tool, and discard software that contains significant numbers of errors. Change the design if necessary to make thorough testing feasible.
-
Static analysis. The compiler should be used in its strictest mode, and all code should pass without warnings. Use a static analysis tool to detect anomalies in the code; several such tools are now readily available. Specialized static analyses can establish the absence of certain kinds of security vulnerabilities.
-
Code review. Conduct systematic reviews of all code as early as possible, before the code is placed in the project repository.
-
Incremental build. Integrate the code of a system early and often. Include all checking tools in the automatic build process, including static analyses, unit and regression tests, and dependency analyses.
Process-Level Practices
Best practices at the process level include the following:
-
Process. A robust and clear quality management system that is appropriate to the development organization and the character of the software being developed should be chosen, documented, and adhered to. Individuals should be trained in the aspects of the system that are relevant to their roles, and the process should encompass verification that its requirements are being adhered to and a systematic effort to review the costs and benefits of the process and improve it as appropriate.32
-
Risk management. Identify key risks (of failure in development or failures of the product), record them in a risk register (essentially a table of all known risks), and articulate a plan to mitigate them. An incremental approach is most likely to succeed, focusing on major risks early on, developing core features first (including those that will have a significant impact on product architecture), and minimizing complexity.
-
Project planning. The project should have an explicit plan with milestones against which progress is systematically evaluated. The plan should explicitly address the risks identified in the risk register.
-
Quality planning. The project should have an explicit quality plan that articulates the quality criteria and describes how the quality criteria will be achieved and how the product will be assessed against them.
-
Version control. All of the significant project documents (requirements, designs, code, plans, reports, and so on) should contain a date, version number, and change history and be kept under strict version control. In particular, a standard source code control system should be used that provides versioning, backup, and conflict detection.
-
Bug tracking. All reported bugs should be documented in a database and indexed against the location where they were discovered in the code, design, or other documentation. All bug fixes should be fully documented and indexed against the appropriate bug report, and should result in reverification, including reexecution of regression test suites and the creation of new regression test cases. In any important application, each bug should be traced to its origin in the development, and a review should ensue to determine whether there are other similar bugs and what modifications to the development process could reduce the likelihood of such bugs occurring in the future.
-
Phased delivery. Deliver a system in phases, with the most basic and important functions delivered in the first phase and additional functions delivered in later phases, in order to exploit feedback from users and reduce risk.
-
Independent review. In a critical application, reviews by the development team should be augmented by reviews by an independent party.
FEASIBILITY OF THE OVERALL APPROACH
The approach to justifiable confidence and dependable software proposed in this chapter and the technical practices it involves should be adoptable without significant risk, because the practices have already been successfully applied by a few companies, as illustrated by the four papers cited in the next three paragraphs.
The importance of taking a systems perspective and regarding the direct human users of the computer interface as part of the overall system is widely recognized—in the aviation industry, for example, the aircraft is seen as a single system and the likelihood of error by the pilot is a factor treated explicitly in the system design and in safety analysis and certification. The importance of simplicity, even in complex applications, has long been understood in high-security systems, where the software that protects data integrity and confidentiality is kept as simple as possible and often implemented as a “security kernel.” An example is described in a paper in IEEE Software.33
The benefits of exploiting analysis in addition to testing have been demonstrated on several projects reported in the literature. A good analy-
sis of a number of commercial projects is contained in a paper in IEEE Transactions on Software Engineering.34 The importance and effectiveness of capturing environmental assumptions is explained with reference to an e-commerce system, a safety protection system, and a railway signaling system in a 2001 conference report.35
Evidence-based dependability cases and explicit claims are widely used in safety-critical software development but have also been shown to be cost-effective when building commercial applications.36 The common experience, from these reports and others, is that these technical recommendations are practical to adopt and effective in use by experts. As with all engineering, cost-effectiveness is a primary objective; making dependability claims explicit allows developers to ensure that they achieve the necessary dependability without overengineering.
|
34 |
S. King, J. Hammond, R. Chapman, and A. Pryor, 2000, “Is proof more cost-effective than testing?” IEEE Transactions on Software Engineering 26(8):675-686. |
|
35 |
J. Hammond, R. Rawlings, and A. Hall, 2001, “Will it work?” Proceedings of the 5th IEEE International Symposium on Requirements Engineering, August. |
|
36 |
Adrian Hilton, 2003, “Engineering Software Systems for Customer Acceptance.” Available online at <http://www.praxis-his.co.uk/pdfs/customer_acceptance.pdf>. |






































