
5
Model Selection and Use
The last and perhaps most important stage of the life cycle of a regulatory model is its application to an environmental regulatory issue. How a model arrives at the point of application and how much of its development is specific for a given application vary greatly. For example, modelers who develop a model for a specific application may also apply it, while others who develop a general model do not use it for a particular application. Box 5-1 describes one such model.
The objective of this chapter is to describe issues that arise in selecting models for their applications in regulatory activities. As done throughout this report, regulatory activities considered include any case for which EPA uses a model to aid in developing regulations, such as setting standards, or for which EPA or others develop plans to implement or enforce regulatory requirements. The ultimate goal for all applications is to use all available and appropriate information when selecting a model. In some cases, a model that gets updated on a regular (but not a frequent) schedule might be more appropriate to use, if the updates incorporate information important to the outcome, than to change for the sake of change. However, some degree of stability and predictability is of value to regulators and affected parties. In all cases, evaluation of the model-selection decision assesses the appropriateness of a model or group of models for a specific application. As described in the previous chapter, this assessment involves addressing whether the model is based on generally accepted science and computational methods, whether approximates the behavior observed in the system being modeled.
|
BOX 5-1 Example of a Generic Model for Application to Specific Settings A description of one example of model application information is found at EPA’s Support Center for Regulatory Atmospheric Modeling web site (EPA 2006l). One modeling system described on the site, AERMOD, was developed by the American Meteorological Society and the EPA Regulatory Model Improvement Committee. The AERMOD system is a steady-state plume model that simulates dispersion of air pollutants from point or area sources. It is a good example of an extensively documented model targeted at a broad range of users for regulatory purposes. The AERMOD modeling system includes extensive documentation, including model code, a user’s guide, supporting documents, and evaluating databases, all of which are available on the web site of the EPA Support Center for Regulatory Atmospheric Modeling. The supporting documents include details of the model formulation and evaluation, comparison of regulatory design concentrations, an implementation guide (information on recommended use of the model for particular applications), evaluation of model bias, sensitivity analysis, a parameterizations document and peer review document. The evaluation databases include input and output data for model evaluation. User’s manuals include instructions for novice and experienced users, decision makers, and programmers. The model code and supporting documents are not static but evolve to accommodate the best available science. |
ISSUES IN MODEL SELECTION AND APPLICATION
Model developers and regulators must evaluate how appropriate an existing model is for a specific setting and whether the assumptions and input data are relevant under the conditions of the application. Optimally, a model is applied to a problem within the model-specific application domain near the time of model development. However, frequently, this is not feasible. Thus, models need to be evaluated in context with each application, the degree of evaluation being commensurate with the case. A number of issues arise when selecting and applying a model or a set of models for environmental regulatory activities. These issues are discussed below and include the following: the selection of a model from multiple possibilities, the level of expertise, the assumptions and range of applicability, the cost and availability, the adaptability of the model; and the data availability.
Model Selection
The committee recognizes the wide variability in the availability of alternative modeling approaches for specific regulatory applications.
Thus, guidance on model selection varies. For example, EPA recognizes a single model, the MOBILE model, for developing motor-vehicle emissions inventories for state implementation plans and other air quality regulatory activities outside of California. Although EPA provides guidance for implementing this model, including a user’s guide (EPA 2003f) and policy guidance (EPA 2004f), no guidance is needed to select the model. For air quality models, several models, each with its own strengths and weaknesses, might be selected for regulatory activities (Russell and Dennis 2000). The community of air quality modelers is highly specialized and relatively small, and the selection of models is often based on familiarity. In contrast, there are many models from which to select for air dispersion modeling. EPA has developed a guidance document, called Appendix W, on selection of models and on models approved for use (70 Fed. Reg. 68218 [2005]). The guidance is described in more detail in Box 5-2. The EPA Center for Subsurface Modeling Support supports the identification and selection of appropriate subsurface models and supports the review of site-specific modeling efforts at Superfund sites and other large hazardous waste contamination sites (Burden 2004). As with air dispersion modeling, there are many models from which to select; the Center for Subsurface Modeling Support distributes public domain software for over 25 models. There is also a wide range of models possible for performing total maximum daily load (TMDL) analysis (Shoemaker 2004; Wool 2004). Furthermore, fundamentally different modeling approaches are called for, depending on whether the TMDL focuses on the runoff of a pollutant from the water-shed, on where a nonpoint source nutrient loading model would be needed, or on whether the TMDL focuses on the concentration of a pollutant in a body of water where a water quality model would be needed.
For all cases that have multiple models available, users must consider many factors when deciding on the most appropriate model to use. These factors include complexity of the problem setting, types of pollutants, spatial and temporal scales, data availability, costs of controls, and an array of practical considerations (for example, available expertise and familiarity) Although no single method for developing a model selection tool would be applicable for the range of conditions faced by regulatory modelers, the recently completed Science Advisory Board’s review of the EPA Council on Regulatory Environmental Models (CREM) recommends that the CREM database present competing models in a comparative matrix in the form of a side-by-side comparison table, such as seen in the vehicle sales industry (EPA 2006d).
|
BOX 5-2 Appendix W: EPA’s Guidelines on Air Quality Models The guidelines, first published in April 1978, was developed to ensure consistency and standardization of model applications for air quality regulations. The guidelines was written in an effort to balance consistency and accuracy in selecting appropriate models. This document, available via the web (70 Fed. Reg. 68218 [2005]; http://www.epa.gov/scram001/guidance/guide/appw_05.pdf), is intended for use by all parties (for example, EPA, state, and local agencies and industry) for calculating the concentration of criteria air pollutants. The guidelines attempts to provide some guidance to model selection while maintaining enough flexibility to account for the complexity and individuality of sources. This document is continuously developed to include new models and updated information on existing or older models and to respond to public comments. Recommendations concern preferred models, databases, requirements for concentration estimates, use of measured data instead of model estimates, and model evaluation procedures. In some cases, specific models are prescribed for a particular application; in other cases, a type of model is specified. Deviation from the guidelines must be fully supported and documented. |
Model selection issues can be further illustrated by considering the use of statistical models for assessing dose-response relationships. The case of EPA’s selection of a model for arsenic in drinking water, which is discussed in Chapter 1, provides a good example. In that case, when empirical statistical models in a suite were applied to the data, they differed substantially in their fitted values, especially in the critical low-dose area, which is so important for establishing the benchmark dose used to set a reference dose (see Figure 1-3). This problem highlights the dilemma of model selection in the face of different models with different results. One solution is the use of Bayesian model averaging (BMA) as a tool that avoids having to pick one particular model by combining a class of suitable models. This option, discussed in Box 5-3, is preferable to forcing the choice of a model that may have the best “fit” but that may sacrifice parsimony or that may not account for uncertainty in this case. However, Finkel (2004) described problems with model averaging, and the use of such an approach must be considered on a case-specific basis.
Another approach is to use multiple models of varying complexities to simulate the same phenomena. Using multiple models in such a manner might allow insights into how sensitive results are to different modeling choices and how much trust to put in results from any one model. Box 5-4 shows an example of this approach.
|
BOX 5-3 Arsenic in Drinking Water: Model Selection Morales et al. (2000) analyzed the Taiwanese data using a suite of relatively simple empirical models that differed according to how age and exposure were incorporated. All the models assumed that the number of cancers observed in a specific age group of a particular village followed a Poisson model with parameters, depending on the age and village exposure level. Linear, log, polynomial, and spline models for age and exposure were considered. These various models differed substantially in their fitted values, especially in the critical low-dose area; which is so important for establishing the benchmark dose (BMD) used to set a reference dose (RfD). The fitted-dose response model was also strongly affected by whether Taiwanese population data were included as a baseline comparison group. The estimates of the BMD and associated lower limit (BMDL) varied by over an order of magnitude, depending on the particular modeling assumptions used. This highlights a major challenge for regulatory purposes, namely, which model to base decisions on. One strategy would be to pick the “best” model—for example, use one of the popular statistical goodness of fit, such as the Akieke information criterion (AIC) or the Bayesian information criterion (BIC). These approaches correspond to picking the model that maximizes log-likelihood, subject to a penalty function reflecting the number of model parameters, thus effectively forcing a trade-off between improving model fit by adding addition model parameters versus having a parsimonious description. In the case of the arsenic risk assessment, however, the noisiness of the data meant that many of the models explored by Morales et al. (2000) were relatively similar in terms of statistical goodness-of-fit criteria. In a follow-up paper, Morales et al. (2006) argued that it was important to address and account for the model uncertainty, because ignoring it will underestimate the true variability of the estimated model fit and, in turn, overestimate confidence in the resulting BMD and lead to “risky decisions” (Volinsky et al. 1997). Morales et al. suggest the use of Bayesian model averaging (BMA) as a tool that avoids the need to pick one particular model by combining over a class of suitable models. In practice, estimates based on a BMA approach tend to approximate a weighted average of estimates based on individual models, the weights reflecting how well each individual model fits the observed data. More precisely, these weights can be interpreted as the probability that a particular model is the true model, given the observed data. The figures below show the results of applying a BMA procedure to the arsenic data. Figure 5-1a plots individual fitted models, the width of each plotted line reflecting the weights. Figure 5-1b shows the estimated overall dose-response curve (solid line) fitted via BMA. The shaded area shows the upper and lower limits (2.5% and 97.5% tiles) based on the BMA procedure. The dotted lines show upper and lower limits based on the best fitting models. Figure 5-1b (L30) effectively illustrates the inadequacy of standard statistical confidence intervals in characterizing uncertainty in settings where there is substantial model uncertainty. The BMA limits coincide closely with the individual curves at the upper level of the dose-response curve where all the individual models tend to give similar results. |
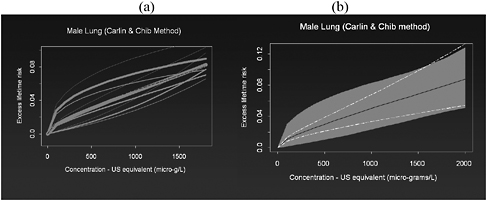
FIGURE 5-1 (a) Individual dose-response models, and (b) overall dose-response model fitted using the Bayesian model averaging approach. Source: Morales et al. 2000.
Model Expertise
Problems can arise if a model is applied incorrectly by an inexperienced user who does not understand how the model operates or who uses the model outside its range of applicability. Such model use would result in potentially erroneous conclusions. Models for regulatory applications will inevitably be used by individuals and groups who are not modelers and who might not be sufficiently trained to catch subtle or even obvious errors. This observation emphasizes the need for training. Box 5-5 mentions two of many ways EPA attempts to improve modeling expertise inside and outside the agency.
Model Documentation and Transparency
For an appropriate model to be selected, both by those assessing whether it would be appropriate for a given case and by those reviewing that decision, it must have adequate documentation for both potential users and those that might scrutinized the model selection decision. Documentation needs, including those related to accepted uses and model origin and history, have been discussed in Chapters 3 and 4. Documenting models for examination by stakeholders and the public provides transparency to build confidence in modeling results (see Box 5-6).
|
BOX 5-4 Use of Multiple Models of Varying Complexity for Estimating Mercury in Fish A potential benefit of the clean-air mercury rule, which requires reductions in mercury emissions from coal-fired power plants, is the reduction of human exposure and related health impacts from methylmercury by reducing concentrations of this toxin in fish. There are many challenges and uncertainties in understanding the impact of reductions in atmospheric mercury emissions on human health. In its assessment of the benefits and costs of this rule, EPA used multiple models to look at one particular issue—how changes in atmospheric deposition would affect mercury concentrations in fish—and applied the models to assess some of the uncertainties in this impact (EPA 2005e). EPA based its national-scale benefits assessment on results from the mercury maps (MMaps) model. This model assumes that there is a linear, steady-state relationship between atmospheric deposition of mercury and mercury concentrations in fish and thus assumes that a 50% reduction in mercury deposition rates results in a 50% decrease in fish mercury concentrations. In addition, MMaps assumes instantaneous adjustment of aquatic systems and their ecosystems to changes in deposition. Thus, there is no time lag in the conversion of mercury to methylmercury and its bioaccumulation in fish. MMaps also does not deal with sources of mercury other than those from atmospheric deposition. Despite those limitations, the agency concluded that no other available model was capable of performing a national-scale assessment. To further investigate fish mercury concentrations and assess the effects of MMaps assumptions, EPA applied more detailed models, including the spreadsheet-based ecological risk assessment for the fate of mercury (SERAFM) model, to five well-characterized ecosystems. As opposed to the steady-state MMaps model, SERAFM is a dynamic model that calculates the temporal response of mercury concentrations in fish tissues to changes in mercury loading. It includes multiple land-use types for representing watershed loadings of mercury through soil erosion and runoff. SERAFM partitions mercury among multiple compartments and phases, including aqueous phase, abiotic participles (for example, silts), and biotic particles (for example, phytoplankton). Comparisons of SERAFM’s predictions with observed fish mercury concentrations for a single fish species in four ecosystems showed that the model underpredicted mean concentrations for one water body, overpredicted mean concentrations for a second water body, and accurately predicted mean concentrations for the other two. The error bars for the observed fish mercury concentrations in these four ecosystems were large, making it difficult to assess the accuracy of the models. Modeling of the four ecosystems also showed how assumed physical and chemical characteristics of the specific ecosystem affected absolute fish mercury concentrations and the length of time before fish mercury concentrations reached steady state. Although EPA concluded that the best available science supports the assumption of a linear relationship between atmospheric deposition and fish mercury concentrations for broad-scale use, the more detailed ecosystem modeling demonstrated that individual ecosystems were highly sensitive to uncertainties in model parameters. The agency also noted that there were many model uncertainties that could not be quantified. Finally, although the case studies cover the bulk of the key environmental characteristics, extrapolating the individual ecosys |
|
tem case studies to account for the variability in ecosystems across the country indicated that they might not represent extreme conditions that could affect how atmospheric deposition of mercury would affect fish mercury concentrations in a water body. This example illustrates the usefulness of investigating a variety of models at varying levels of complexity. A hierarchical modeling approach, such as that used in the mercury analysis, can provide justification for simplified model assumptions or can potentially provide evidence for a consistent bias that would negate the assumption that a simple model is appropriate for broad-scale application. |
Resource Requirements and Availability
Model selection must consider whether a model is economically feasible or readily available to potential users. Very complex, detailed models may be expensive to develop and execute. A National Research Council report (NRC 2001c) on the TMDL program urged modelers and decision makers to recognize that simpler analysis can support informed decision making and that complex modeling studies should be pursued only if necessary based on the complexity of the problem. This report recognized that the cost of maintaining and updating a complex model should be considered in model selection, as these costs become cumbersome over time. A possible solution noted by the NRC report is to develop simpler models with existing data that can be iteratively expanded as more data become available.
|
BOX 5-5 Model Training and Support EPA has created support networks for aiding in the application of some environmental regulatory models. One of the networks is the Center for Subsurface Modeling Support located within EPA’s National Risk Management Research Laboratory. This center provides public domain groundwater and vadose zone modeling software and guidance documents to a variety of users, including universities, state and federal governments, and the private sector (Burden 2004). It also provides training and education. For regional air quality modeling, EPA has created the Community Modeling and Analysis System (CMAS) Center at the University of North Carolina at Chapel Hill. This center is intended to help to promote the use and understanding of the Models-3 air quality modeling suite, including through training courses. The courses are open to everybody (including federal and state employees and scientists from the private sector and academia), although they do assume some prior modeling and computing proficiency. The CMAS center also offers online tutorials. |
|
BOX 5-6 Confidence Building in Models Through Transparency Placing data sources, software, and the exact list of commands used to produce the model output, along with a good amount of documentation, on a public web site can help build confidence in the specific use of a model. iHAPSS, the internet-based Health and Air Pollution Surveillance System, developed at the Johns Hopkins University, provides an example of this kind of resource. Even if stakeholders choose not to replicate analyses, which will generally be the case, the presence of such documentation of model use will help to convince stakeholders that the analysts are not trying to hide anything. In some circumstances, some input data may be proprietary or involve privacy concerns or the data set may be too large, thus making this approach unworkable; otherwise, such a public web site should be the norm in high-stakes settings. A possible concern about making data and code so readily available is that it will make it easier for stakeholders to slow up the decision-making process by raising narrow objections to the large number of choices that are inevitably made in using complex models. Although the committee would still support a high level of openness even if that concern were valid, it is not clear that it is valid. For example, making all data available in readily usable form makes it much easier for others to do their own analyses. As a consequence, criticisms of the form “You should have tried this” or “You need to account for the effect of that” become less cogent because the availability of the data allows the reply, “If you think that matters so much, why not do the analysis yourself?” Making the code available further lowers the barrier to others’ modifying an analysis. Thus, greater availability of data and code may help discussions about the appropriateness of a model application to focus on the issues that do matter as opposed to laundry lists of issues that might be conceived to matter. |
Assumptions and Specified Range of Use
Understanding the major assumptions and the range of applicability of a model is critical for selection because the assumptions and applicability define an application niche for a model. For example, atmospheric dispersion models typically assume steady, horizontally homogeneous wind fields instantaneously over a given spatial area and are usually limited to 50 km from the source. The use of such a model would not be appropriate for an application at hundreds of kilometers from the source. For the nonsteady-state dispersion model CALPUFF, which allows the model documentation to include information on modeling domains, meteorological data, terrain and land use data, sources, receptors, and modeling options used to develop the model (EPA 2006m). To further demonstrate its application niche to potential users, this model documentation includes a comparison of the modeling results to observations for long-range transport field experiments. All models come with such assump-
tions and application limitations. Although modelers often have no choice but to use a model for an application in which a major assumption within the model is directly violated or is close to being violated, such an application must be made clear to those who might use or review model results.
Another difficult issue is whether to use a model developed for a different purpose with different specifications. As discussed in Chapter 3, it is often desirable from the standpoint of time and resource investment to use or modify an existing model for a new setting than to develop a new model. However, at what point do the differences make the model inadequate? Professional judgment is required in such cases, and such judgments should differentiate clearly between scientific considerations and other considerations. From an evaluation standpoint, it is critical to make such a decision transparent so it can be commented on and potentially challenged.
Data Availability and Interpretation
A final issue relevant for model selection is the availability and interpretation of data. As discussed in Chapter 3, the mismatch between data needs and availability can result in failure of the model exercise even when the model itself may be a good fit for an individual application. Issues concerning data that come up at model application that are not faced during model development include the need to set boundary and initial conditions, develop site-specific input data, and have access to local monitoring data to test model estimates against observations. Data collection can also aid in reducing uncertainty, improving existing models, and informing developers on when a monitoring program might be useful in reducing uncertainty and simplifying the model. However, models typically can use more data than are available for developing input or for corroborating results with observations. The lack of data requires the use of parameter defaults that are not based on site-specific data.
One approach to lessen the concerns over relying on default parameters in regulatory modeling is to use a tiered approach in which conservative defaults are initially used, possibly with conservative screening models. If a potential problem is detected with conservative defaults, analysis with site-specific data might then be used, possibly with a more refined model, for more refined analysis. Data collection takes time,
which may conflict with regulatory time lines, and resources, which may conflict with other priorities. Such conflicts should be explicitly dealt with rather than used as a broad excuse not to collect data. As discussed in Chapter 3, adaptive approaches with iterations among model development and applications and with data-collection efforts are key to improving overall model quality.
Model Extrapolation
Model use in the environmental regulatory process may involve applying a model to extrapolate from conditions that have corroborating information to conditions that have little or no corroborating information available. For example, it might be necessary to extrapolate laboratory animal data to assessments of possible human effects or to extrapolate the recent history of global environmental conditions to future conditions. In these circumstances, uncertainties about the form of a model and of the parameters in any specific model may yield large uncertainties in model outputs.
In some cases, it is clear when application of a model involves extrapolation beyond the data or assumptions used to construct or fit the model. For example, one of the major sources of controversy in the EPA’s arsenic risk assessment was the use of a model based on Taiwanese data to estimate risk for the U.S. population (see Box 2-1 in Chapter 2). In this case, model results from one population are extrapolated to another population with differences in genetics, diet, health status, and other factors that could affect the risk relationship (NRC 1999a). In such cases, it is helpful to be as transparent as possible with respect to implicit assumptions that might have an impact on the appropriateness of the extrapolation. In the case of arsenic, for example, extrapolating the Taiwanese results to the U.S. setting involved decisions on whether to use a multiplicative or an additive risk model, as well as assumptions on the typical amount of daily water consumption by individuals in the two countries. Making such assumptions explicit opens the way to sensitivity and uncertainty analyses that can provide a realistic assessment of the impact of applying models to settings outside the context within which they were developed. Extrapolating far beyond available data used to develop the model also puts a particular premium on ensuring that the model’s theoretical basis, the processes included in the model, and the selected parameter values within the model are as sound as possible.
Another example in which the use of a model involves extrapolation beyond data or assumptions occurs when EPA forecasts the results of policy decisions into the future. Under such circumstances, EPA often applies models to forecast the impact of regulations over time horizons of years to decades, sometimes incorporating demographic forecasts and forecasts of economic activities (usually from other agencies) as well as assuming that other conditions, such as regulatory and legislative mandates, do not change in the future. Once again, careful sensitivity analyses are needed to assess the impact of various implicit and explicit modeling assumptions to provide a realistic assessment of the uncertainty associated with extrapolating results into the future. This type of approach has been quite effectively applied in the climate change arena where graphs are shown that predict possible future scenarios under a variety of different modeling assumptions. In this sense, the problem of extrapolation beyond the setting in which a model has been developed can be mapped into the broader issue of assessing model adequacy and sensitivity.
If a quantitative structure activity relationship (QSAR) model, which is used to predict physical-chemical properties and environmental fate and transport properties from the chemical structure of a new compound, is being used, the term inside or outside the “domain” is used to indicate whether a model is extrapolated beyond conditions for which the model was constructed or calibrated. The concept of a domain of applicability was one of the six principles developed at a conference of modelers in Setubal, Portugal for use in determining whether a QSAR model is acceptable for chemical management, such as for priority setting, risk assessment, and classification and labeling (Jaworska et al. 2003).
In many applications, extrapolating “far” from known data and conditions is clearly being done. For example, when models are used to predict along a continuum of time, space, or dose, it is clear when the model has moved beyond a point where information is available. In other applications, the model produces output that is not easily placed along a continuum, so it is not clear how much of an extrapolation is being performed. For example, if the model output is the total cost of a regulation and the data are numbers of deaths and pollution levels in cities across the country as well as the per person value of life, the model output can be thought to depend on many unverifiable assumptions. It is in some sense an extrapolation, but it is hard to measure how “far” the output is from the data. Again, this problem puts a premium on ensuring that the model and input parameters are developed on a sound theoretical basis
and that the impacts of important assumptions can be assessed through sensitivity and uncertainty analysis.
Specifying Uncertainty
At the model application stage, it is important to have effective strategies for representing and communicating uncertainties. For many regulatory models, credibility is enhanced by acknowledging and characterizing important sources of uncertainty and by acknowledging how uncertainty limits the value of a model as a “truth generator.” Modelers should take care to estimate, quantify, and communicate uncertainties accurately to users and regulators. Any limitations in temporal or spatial scales should be stated clearly. The quality of the input data and the resulting limitations on the range of use for the model should be explained in terms of the intended use of the model. Sensitivity to alternative inputs or assumptions should be documented.
As discussed in Chapter 4, interactive graphics would allow the policy maker to choose values of one or more key parameters and then view the conditional distribution of the net benefit, given these parameters. However, interactive computer programs are no substitute for human interaction, and the committee strongly encourages extensive interaction between scientists and policy makers when policy makers can ask various “what-if”-type questions to help them think through their decisions. Policy makers need to be informed explicitly of the impacts of changing assumptions about highly uncertain parameters in a technical analysis; these impacts should not be buried in the analysis.
Communication of Models to Decision Makers
As discussed earlier in this report, models can be best viewed as tools providing input into decisions rather than as truth-generating machines that make decisions. The implications of this finding are clear. Although policy makers may desire an answer from a model, a bright line per se, models are best considered to be one source of input into the regulatory process. The challenge then is to communicate model results and improve the education of policy makers about the capabilities and limitations of the models.
The focus of this effort is typically the EPA policy makers, but it can also include stakeholders who use a model to provide information to EPA, stakeholders who want independent evaluation of the utility of a regulatory model, or even members of the public who must decide whether to change behaviors or to take other actions based on model results. Most of these individuals have one thing in common—they are not technically expert modelers. However, most expert modelers are not expert in issues surrounding decision making. How then can this gap be bridged? One method is to continue to improve model accessibility. Accessibility motivates the committee’s recommendation regarding the maintenance of a model’s history, including a “plain English” guide to the model. It also motivates the committee’s recommendation to continue to improve the transparency of modeling for regulatory decision making, including through web-based tools.
Decision makers should be involved in each stage of model development and use. Their involvement in all aspects of model use, from problem formulation and development of the model’s conceptual basis to its application, is fundamental to the appropriate use of models. Such involvement requires successful communication between modelers and decision makers, with emphasis on “between” rather than on “from” one to the other. Both parties have responsibilities to teach and to learn. For major decisions, these responsibilities often must be carried out under tight time constraints in a controversial atmosphere. The modelers need to do more than describe the processes used (for example, peer and stakeholder reviews). They need to describe the modeling elements in an understandable way to a nonexpert. For such communications, it is more about the elements of the model than the precise algorithm used. As described by Voltaggio (2004) when discussing the role of an EPA deputy regional administrator in understanding modeling analysis, the typical questions asked by such decision-makers are related to the assumptions in the model, the quality of the inputs, and the sensitivities of the model results to uncertainties in inputs and other factors. In such cases, decision makers may be relatively ignorant of the model’s inner workings.
It also is important for modelers to involve decision makers in the development of uncertainty analysis to ensure that decision makers incorporate their policy expertise and preferences into such assessments. Visualization techniques can be very useful to communicate with decision makers and others, especially when probabilistic approaches are used. However, as noted by Morgenstern (2005), a large body of research on decision makers shows that the manner in which uncertainty informa-
tion is presented can affect its interpretation. One conclusion that came from interviews with EPA decision makers was the need for more contextual information to accompany any graphic or tabular representations of model uncertainties (Krupnik et al. 2006).
Communication between modelers and a single decision maker can be valuable for all who participate in the regulatory process. The translation of a model from highly technical to more common usage language for an EPA official, for example, can be used by all interested parties. An accessible model evaluation plan helps all.
PROPRIETARY MODELS
At the point of model selection, a regulatory agency may decide to use a proprietary model. A model is proprietary if any component that is a fundamental part of the model’s structure or functionality is not available for free to the general public. Components include source code, mathematical equations, input data, user interfaces, or supplemental third-party software (excluding operating systems or development software). Components may also include assumptions or computational methods. A model under copyright is not necessarily proprietary if the model is freely available in its entirety.
The argument for using proprietary models is that, without meaningful intellectual property protections, modelers in the private sector would not have incentives to develop sophisticated models. The arguments against using proprietary models in the regulatory arena have been articulated by environmental groups and industry groups (Sass 2004; Slaughter 2004). Proprietary models to these stakeholders are directly at odds with the goals of open government and transparency.
Motivations for Keeping Information Proprietary
In some cases, proprietary models are used because one might happen to provide the most reliable and dependable output for a specific application. Efforts should be taken to use an open-source model when available; however, model developers might be motivated to maintain the proprietary nature of the models that they develop. These motivations include profit from selling, updating and maintaining the model, training users on the model, and protecting trade secrets.
The best way for a modeler to protect his intellectual investment in a model is to claim trade-secret protection. Protection is immediate and is accomplished by insisting that the model and its contents are secret. There are two main difficulties in evaluating the legitimacy of a tradesecret claim on proprietary models in terms of whether it ultimately serves the public interest. First, the owner of the proprietary information has the best information concerning whether there is a legitimate competitive advantage to keeping the information secret, thus, making it hard for outsiders to evaluate, especially if the owner has other, overlapping reasons to insist on confidentiality (such as to avoid controversy over assumptions and to retain control over the running of the model). Second, it is difficult to evaluate empirically whether providing secrecy to model developers will spur innovation. In other words, would modelers still develop models for the marketplace with private dollars, even without trade-secret protections?
Proprietary Aspects of Environmental Models
The CREM guidance defines a proprietary model as one in which the source code is not universally shared (EPA 2003d). However, a model can also be classified as proprietary if any component of the model is proprietary, including the source code, the input data, or third-party software. These three components are explained in Box 5-7.
The committee heard presentations on three case histories of proprietary models. The Integrated Planning Model (IPM) is a long-term capacity expansion and production costing model for analyzing the electric power sector. It was developed by ICF International and is used by EPA and a wide variety of other groups to assess environmental regulatory activities that affect this sector (Napolitano and Lieberman 2004). The model is used because of its detailed representation of the system, including rich representations of dispatch decisions, capacity expansion, and emission-control options. A key element of the proprietary nature of this model is the thorough representation of the electricity sector. The DEEM-CALANDEX models are used widely to estimate multiple-pathway human exposure models for pesticides. These models were developed by Exponent Inc. The key proprietary feature of these models is their user-friendly interface and ability to do multiple
|
BOX 5-7 Proprietary Components of Environmental Models
The line is gray between third-party software for development versus use, since a model can be developed in a specific application with the end use of that application in mind (for example, a GIS model). |
analyses quickly (Petersen 2004). The TRANSIMS model predicts vehicle travel on highways and then that information is used as input into mobile-source emissions models. Currently, TRANSIMS is a research model developed by Los Alamos National Laboratory for the U.S.
Department of Transportation. IBM has been hired to commercialize this model by developing user interfaces that will allow users to develop model input, run the model, and visualize the output (Ducca 2004).
Alternatives for Using Proprietary Models
It might be risky to ignore the purported benefits of proprietary models if they appear to be playing an important role in advancing the science of modeling. However, the committee notes that distrust of proprietary models was shared by both a representative of an environmental organization (Sass 2004) and a representative of a pro-business group advocating for regulatory reform (Slaughter 2004). Agencies such as EPA could use a range of alternatives to justify the use of proprietary models, to provide some oversight of these models’ reliability, and to limit the potential use of such models. The objective of these alternatives is to have the rigor applied to EPA-developed models also be applied to external models used by EPA in the regulatory process. Many of these issues were discussed by Napolitano and Lieberman (2004) and Petersen (2004).
-
An agency could bargain for the added right to disclose publicly the contents of the model. In this case, the agency would pay the model owner to give up his right to keep the information secret. The problem is that the model owner may charge a very large fee to transfer ownership of the model.
-
An agency could require the model owner to justify the claim that the model must be kept proprietary. The model owner would be expected to explain the competitive losses from divulging the model, and this justification would be publicly available.
-
If the model is ultimately kept confidential, the agency could require the owner to agree to a limited number of “confidentiality agreements” with an objective peer review panel (to be named later) that would evaluate the model and provide a public report on its findings without disclosing the trade-secret-protected information. This process ensures rigorous peer review without releasing protected information.
-
Before using a proprietary model, an agency should justify why it is superior to the alternatives. Under such a policy, proprietary models would be disfavored and used only when the agency can provide a compelling justification for doing so.
-
An agency could insist on an expiration date for the secrecy protections on the model.
-
An agency could insist that the modeler obtain a patent rather than protect its property interest through trade-secret protections (a patent requires the public dissemination of the contents of the model). The problem with obtaining a patent is that it can take years to obtain, and it is also uncertain that some models can be patented. Apparently, copyright protections will work as long as the model is embedded in software, but they will not apply to the underlying ideas in a model (like the algorithms), and thus copyrighting is not a viable means of protecting intellectual property in models.
RECOMMENDATIONS
Proprietary Models
A model is proprietary if any component that is a fundamental part of the model’s structure or functionality is not available for free to the general public. The use of proprietary models in the regulatory process can produce distrust among regulated parties and other interested individuals and groups because their use might prevent those affected by a regulatory decision from having access to a model that may have affected the decision. There are many ways in which a model can be proprietary, and some are more prone to engender distrust than others. For example, a model that uses proprietary algorithms may cause more concern than a model that uses publicly available algorithms but has a proprietary user interface.
Recommendations
The committee recommends that EPA adopt a preference for non-proprietary software for environmental modeling. When developing a model, EPA should establish and pursue a goal of not using proprietary elements. It should only adopt proprietary models when a clear and well-documented case has been made that the advantages of using such models outweigh the costs in lower credibility and transparency that accompanies reliance on proprietary models. Furthermore, proprietary models should be subject to rigorous quality requirements and to peer review
that is equivalent to peer review for public models. If necessary, nondisclosure agreements could be used for experts to perform a thorough review of the proprietary portions of the model. The review process and results could then be made public without compromising proprietary features. General-purpose proprietary software (for example, Excel, SAS, and MATLAB) usually will not require such scrutiny, although EPA should be cognizant of the costs that obtaining and using such software may impose on interested parties.
Extrapolation
Model use in the environmental regulatory process may involve using the model to extrapolate beyond conditions for which the model was constructed or calibrated or conditions for which the model outputs cannot be verified. For example, it might be necessary to extrapolate laboratory animal data to assessments of possible human effects or to extrapolate the recent history of global environmental conditions to future conditions. In these circumstances, uncertainties about the form of a model and the parameters in the model might yield large uncertainties in model outputs. This problem can be compounded by making a model more complex if the additional processes in the more complex model are unimportant; any extra parameters that need to be estimated could degrade the confidence in the estimates of all parameters.
Recommendations
Extrapolating far beyond the available data for the model draws particular attention in the evaluation process to the theoretical basis of the model, the processes represented in the model, and the parameter values. When critical model parameters are estimated largely on the basis of matching model output to historical data, care must be taken to provide uncertainty estimates for the extrapolations, especially for models with many uncertain parameters.




















