
3
Changing the Terms: Data System Transformation in Progress
INTRODUCTION
Compared to even just a few years ago, today’s research questions are often dauntingly complex, a characteristic reflected in the data required for such research. Data are often needed from multiple data sources, including laboratory values, unstructured text records of clinical findings, cost and quality information, and genetic data. In addition, research on less common clinical conditions—those with low incidence or prevalence—inherently demand larger data sets with greater geographic and demographic diversity. Data from a single organization are generally insufficient for many research questions aimed at gaining the depth of understanding required to support evidence-based practices tailored to individuals. Thus there is a growing need for data sharing across research entities and collaborators. Approaches will need to be fast, inexpensive, sustainable, secure, and customized to meet the differing needs of both patients and researchers.
With significant volumes of clinical data housed in public and private repositories across the nation, pioneers are seeking opportunities to use these data to gain powerful insights by synthesizing elements of multiple data sources. Portions of the data stored by healthcare organizations are undergoing transformation—linking large datasets, aggregating health databases, networking for standardized reporting, and developing and interpreting registries. The growth in number and scope of large, linked datasets, aggregated data, and registries will likely benefit care delivery and research. However, different approaches to organizing and aggregating data
generate a unique set of limitations and challenges—all of which seem to be responsive to unique incentives and drivers.
This chapter highlights some notable existing and emerging efforts to coordinate clinical data into more readily available and usable resources; describes incentives for these activities; examines the shortfalls, limitations, and challenges related to various approaches to organizing and aggregating data; and looks at the dynamics pushing integration.
The National Cancer Institute (NCI), for example, has determined that the scale of its enterprise has reached a level that demands new, more highly coordinated approaches to informatics resource development and management. As discussed by Peter Covitz, chief operating officer of NCI, at NCI’s Center for Bioinformatics, the Cancer Biomedical Informatics Grid (caBIG) program was launched to meet this challenge. The caBIG infrastructure is a voluntary network that facilitates data sharing and interpretation with aims to translate knowledge from the laboratory bench to patient bedside. As a tool designed to link resources within the cancer research community, caBIG would ultimately function as a template for sharing and communicating in a common language as well as a platform for building tools to collect and analyze information. The caBIG project is an essential resource to complement other cancer research projects. Moreover, Covitz suggests, caBIG might serve as a possible model for engaging the broader challenge of developing nationwide, interoperable health information networks.
Translational health research draws information from institutional entities as the primary source of analysis. Such an approach has historically enabled researchers to compare outcomes and differences in practice patterns within organizations. Pierre-André La Chance, chief information officer and research privacy officer at the Kaiser Permanente Center for Health Research, offers strategies on cross-institution data sharing through local, interoperable data warehouses and data networks. With an interconnected approach to data, researchers can access data resources more efficiently; the data have higher quality and reliability for generating analyses and decisions that affect both treatment and policy. At Kaiser Permanente, work is underway to develop sharable administrative, disease registry, and clinical data resources as well as a biolibrary to increase access to Kaiser Permanente tumor registries and histology data.
One attainable goal of health information technology (HIT) is the ability to continuously enhance quality and safety in the delivery of health care. Current healthcare financial incentives, which encourage high-cost, high-volume care, steer clinicians away from fully achievable low-cost, high-quality care. Steven Waldren, director of the Center for Health Information Technology at the American Academy of Family Physicians (AAFP), notes that the AAFP highlights the principle that data aggregation can drive and support multiple aspects of healthcare delivery, including quality initiatives, health services and
clinical research, public health, and transparency in reporting practices. As an advocate for the broader use of electronic health records (EHRs), a tool central to data aggregation and sharing, the AAFP encourages members to understand the power of EHRs as more than tools for administrative data. Confidentiality, standardization, and system use can be barriers to data aggregation and must be addressed. Several potential avenues for such improvements were described, including work in support of the American Society for Testing and Materials (ASTM) Continuity of Care Record (CCR) standard and work with the AQA Alliance to articulate the concept of a National Health Data Stewardship Entity.
Offered as a promising model for measuring impact on outcomes, the Society of Thoracic Surgeons’ (STS) Adult Cardiac Surgery Database (ASCD) is highlighted by Peter Smith, a professor and the chief of thoracic surgery at Duke University. The ASCD, the largest of three distinct databases in the STS National Database, is a clinical registry aimed at continuous quality improvements in cardiac surgery. In an effort to push information to the bedside, the STS makes an individual risk calculator, including current risk adjustment information, available to the public. Smith highlighted multiple studies indicating that feedback from repository data can change physician behavior. In addition, ASCD data, in combination with administrative data, have been employed to illustrate the cost-effectiveness of continuous improvement initiatives, which could be shared with, and possibly replicated by, other medical specialties.
EMERGING LARGE-SCALE LINKED DATA SYSTEMS AND TOOLS
Peter Covitz, Ph.D.
Chief Operating Officer, National Cancer Institute
The mission of the National Cancer Institute is to reduce suffering and death from cancer. NCI leadership has determined that the scale of its enterprise has reached a level that demands new, more highly coordinated approaches to informatics resource development and management. The caBIG program was launched to meet this challenge. Its participants are organized into work spaces that tackle the various dimensions of the program. Two cross-cutting work spaces—one for Architecture and the other for Vocabularies and Common Data Elements—govern syntactic and semantic interoperability requirements. These work spaces provide best practices guidance for technology developers and for conducting reviews of system designs and data standards. Four domain work spaces build and test applications for Clinical Trials, Integrative Cancer Research, Imaging, and Tissue Banks and Pathology Tools, representing the highest priority areas defined by the
caBIG program members. Strategic-level work spaces govern caBIG requirements for Strategic Planning, Data Sharing, Documentation, and Training & Intellectual Capital.
In its first year, caBIG defined high-level interoperability and compatibility requirements for information models, common data elements, vocabularies, and programming interfaces. These categories were grouped into degrees of stringency, labeled as caBIG Bronze, Silver, and Gold levels of compatibility. The Silver level is quite stringent, and demands that systems adopt and implement standards for model-driven and service-oriented architecture, meta-data registration, controlled terminology, and application programming interfaces. The Gold level architecture consists of a data and analysis grid, named “caGrid.” caBIG systems register with and plug into caGrid, which is based on the Globus Toolkit and a number of additional technologies, such as caCORE from the NCI and Mobius from Ohio State University.
Cancer: A Disease from Within
Cancer is a disease that comes from within, and researchers have to tease out the difference between cancer cells and normal cells. This task requires a molecular approach; in other words, we have to analyze things that are too small to see with light microscopes or the naked eye. Such an endeavor requires many specialties and subspecialties and areas of inquiry that cannot be practiced by any one individual, laboratory, or institution. In other words, this is not a local problem. This is not a regional problem. This is a problem for the entire cancer research community. It must be tackled on a national—and even an international—scale if it is going to be solved. This breadth of resources is needed because the disease (actually, many widely differing diseases that are categorized as “cancer”) is complex. The fact that any given institution hasn’t quite achieved what we would have liked is no one’s fault.
The vision for caBIG arises from such considerations. The caBIG vision is to connect the cancer research community through a sharable, interoperable structure to employ and extend standard rules, in a common language, to more easily share information and to build or adapt tools for collecting, analyzing, integrating, and disseminating data and knowledge.
The challenges faced by caBIG are quite substantial, but are similar to those faced by those addressing the broader agenda of trying to share health information to improve patient care. caBIG is focused on the immediate problem of cancer. However, because cancer is so complex, it forces one to confront many general problems of biology and medicine. We therefore believe that caBIG is breaking ground and creating a path forward for many biomedical and healthcare disciplines. At the least, we
believe we are creating a possible model or prototype for the broader challenge of creating an interoperable health information network across the nation.
When we launched the caBIG program, we knew there would be tremendous technical challenges, but we were not, in the immediate sense, most concerned with those issues. Rather, we were more concerned about whether the organizational structure was going to be able to scale to the national level. We were keenly aware of failed attempts to consolidate the biomedical information technology market in the past, and of the challenges in deploying technology in the biomedical setting.
From Feudalism to Democracy
In our preliminary thinking, we looked at large conglomerations of people who have tried to organize themselves before. We hoped we could learn something from their models and their experiments, even if they were unrelated to health care, cancer research, or technology. So we looked at national governance models—starting with feudalism.
Feudalism is the prevailing model under which the National Institutes of Health (NIH) operates when it allocates grant-funded research money. Basically, the idea is to have a relatively limited monarchy of sorts, which the NIH represents, that is mostly engaged in the activity of finding and supporting the most capable members of the nobility out in the national terrain. Right now, of course, those lords are getting older and older, and the younger ones are not really able to access the monarch, so we have this problem of the aging research force in America.
Nonetheless, this system has some good qualities. It has been a great system for fostering the creativity of investigator-initiated research. That is why it grew the way it did and why the system has produced such notable successes. But remember, we are trying to build a national network for sharing data, which is not a research program; it’s a technology implementation program. So we believed this model, although it is prevalent at the NIH, would not be appropriate for this particular activity, even though we are at the NIH and the NCI. The problem is that feudalism creates a warlord culture that simply offers too little incentive to cooperate. Regional medical networks share data, but there is no national-scale example that you can point to that has been successful, and this is because most of those programs operate under a feudal structure. The reason feudalism fell to the wayside in the course of human events was because it was inadequate for dealing with national levels of organization.
Today, many programs are in place that say, in effect, let’s just get all the data in one place, then we will appoint one group as the coordinating center. Such efforts always seem to have a nice collegial name, such as the
coordinating center or central database. The idea is that these are the data experts and they will take care of all our data needs. We’ll give them the money, and somehow or other, everything will just work itself out. But of course in practice this does not work. It’s not that it never works, but that it only works for a small number of data types that have wide utility across the community.
This model does have some success stories, such as Genbank, a database of genetic sequences and DNA codes that researchers like to access. The codes are the same for all organisms, using the same four letters as part of the code, so it does make sense for that all to be centralized. Genbank has been a very successful, centralized database. People send in their DNA sequences when they sequence genes, and no one feels forced because it is just the norm, although during its inception there was a big debate over whether this should be a central database. There are several other examples of successful central national databases in biomedicine, but you can count them on the fingers of your two hands.
In cancer research, we deal with thousands of data types across a huge variety of studies; much of those data are subject to privacy restrictions. Thus, a collectivized, centralized database on a national level will not work. So we rejected that approach, and looked for another model—this time considering the notion of federal democracy. Why? In part because it strikes a balance between centralized management and local control. It’s the best fit for what we were trying to achieve. It has worked pretty well in the United States and in other nations, and it’s really the way to go if you want to get community participation and ownership but retain a mechanism for central leadership.
The Federalist Papers are a series of essays in which some of the founding fathers debated the pros and cons of overly centralized control versus overly dispersed and delegated authority. These were the beginnings of the debates about states’ rights versus federal control. Those debates raged for 100 years and, in fact, you still see cases about states’ rights. So it is an ongoing debate and there is no perfect comfort point. But in that tension, in that pull and that tug between centralized authority and local control, you actually wind up moving an entire field forward. This is not as comfortable a model as saying that we’ll give the money out and the lords will take care of it. It’s not nearly as comfortable as saying we’ll just create the central database and then they’ll take care of it. This model forces everybody to participate. This model is the most successful model in our view, not just because it’s cancer research, but because it applies to biomedical data exchange in general.
From such deliberations, we created an organization that elaborates on this notion of control and oversight at the center, but nonetheless
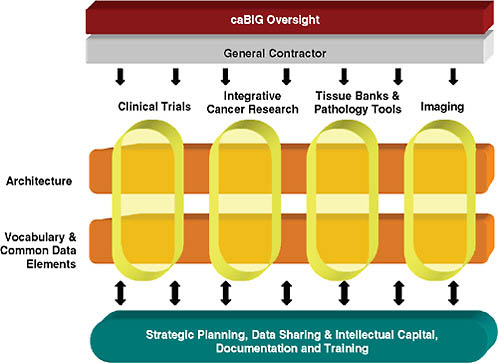
FIGURE 3-1 caBIG organizational model.
includes ample local participation and inclusion in decision making (see Figure 3-1).
caBIG Today
Our design currently includes four domains in cancer research. We can add more if necessary, but the ones in place now are based on a national discussion of priorities—they include clinical trials; a category of all-inclusive integrated cancer research that includes genomics, proteomics, and other molecular-level dimensions; tissue banking and pathology; and imaging.
We could have stopped there. We could have said we were going to get everyone in the nation who cares about clinical trials and then deal with technology issues for trials. But we decided we needed additional elements that could in essence hold the model together—hence, we created an architecture group, which deals with issues related to system architecture and technology choices and, importantly, a group devoted to vocabulary and common data elements, which deals with data standards and semantics. The idea was not for us just to build a closed system where everything works
internally. Rather, we wanted to specify the data and the semantics so that they could be exchanged with other such programs and systems, such as a National Medical Records System. If you specify the data independently of the system architecture, you get to do that. If you tie it all together, then you have created an internally closed system that isn’t going to work well with others. We did not want to make that mistake.
We also have several groups focused on strategic planning. We realized we are not just a technology program; we also have to deal with issues of privacy, licensing, and public–private partnership. CaBIG is not just an academic, federally funded program—it involves and includes the private sector, and has from the start. We are actually beginning to see even greater interest in uptake by the private sector in caBIG program activities and technologies.
For the first 3 years, from 2004 to 2007, the program was a pilot managed by a general contractor, Booz Allen Hamilton. A report is available that summarizes the results of the pilot.1 We attracted the interest of about 190 organizations. There were approximately 300 software projects and subprojects; 40 actual end-user applications were developed for those different domains referred to above. In a real technical tour de force, we built on a number of existing projects that were dealing with the issue of interoperability to create a semantic data grid called caGrid.2 caGrid connects the disparate caBIG community systems.
Some caBIG applications are in the area of clinical trials and have been deployed in a variety of cancer centers. For these software projects, a very modular approach was taken. We tried not to create the massive, central, one-size-does-it-all for everybody. We broke the clinical trials problem down to a number of components: adverse events, data exchange, study participation, and a number of others. That gives a site flexibility to pick which components are going to be necessary for their operation and allows the use of different components. That’s an important feature of the program. It means “rip and replace” is not a requirement, but adhering to standards is. At the same time, the user has multiple ways to access systems that adhere to the standards, including adapting existing systems. For the more basic life sciences, we have solutions for biobanking, for genomewide association study data management, imaging, and microarrays. The overall idea is to address a wide range of different disciplines and tie them together. Finally, we have a major activity in data-sharing security, with policy documents, templates, licenses, and other features that people in the program can use to wrap around and include in their own project.
A Changing Landscape and New Momentum
The landscape is changing and there is new momentum for creating publicly accessible registries of clinical trials. We are working closely with other groups who have been chosen to conduct this activity. In particular, the National Library of Medicine has a key role. There is also a role for different communities with additional requirements beyond the minimum standards needed for a national trial registry. Our plan is to implement cancer trial registries that are completely in conformance with, and contribute to, national and even international trial registries.
Having successfully completed the pilot, the caBIG management is now focused on expansion, roll-out, and deployment. Ultimately we’d like to connect all biomedical researchers, not just cancer researchers. In the development of caBIG, we heard loud and clear that people are at institutions that conduct research in many areas, not just cancer. Thus the overarching goals are to increase the speed and volume of data aggregation and dissemination; broaden the community; and really serve as a model for a scalable national infrastructure for molecular medicine.
caBIG enjoys support from key NIH leaders. Dr. John Niederhuber has been extremely supportive of the program, which was created prior to his taking up the leadership of the institute by the previous NCI director, Andrew von Eschenbach. The director of the entire NIH, Dr. Elias Zerhouni, has suggested that caBIG can serve as a model for other areas.
The NCI is rising to the challenge of cancer by recognizing it cannot just do business as usual; it must change the game. The NIH is often criticized for being conservative and safe, but I would submit that is an overgeneralization, and the spark of leadership and creativity can be found in programs such as caBIG.
NETWORKED DATA-SHARING AND STANDARDIZED REPORTING INITIATIVES
Pierre-André La Chance, B.S.
Chief Information Officer, Kaiser Permanente
The need for sharing data across research entities and among collaborators continues to grow at an astonishing pace. To meet these needs, data sharing solutions must be fast, cheap, sustainable, high quality—with understood meanings—and safe. Current work with the Center for Health Research (CHR) at Kaiser Permanente Northwest and its research collaborators successfully meets these criteria. This work also provides data sharing across entities that compose the NIH’s Clinical and Translational
Science Award (CTSA) program, a consortium of academic health centers that is transforming the discipline of clinical and translational science. This paper will discuss these successes and how they can be extended to support data sharing across the CTSA program, even as many entities create their own clinical data repositories.
Data sharing has changed substantially over the past two decades at Kaiser Permanente. Research questions and data are far more complex. Today we are discovering the increased necessity of data sharing.
Data sharing is essential when identifying potential participants or related issues that might be available to researchers once a study has been approved. It is vital when information from one entity does not meet the researchers’ needs. For example, we know that low-frequency events are important to study, but these demand larger pools of data. We also have strong needs for geographic and demographic diversity. In Portland, Oregon, for instance, we don’t have a great deal of demographic diversity, so we are strongly motivated to find collaborators who can inject diversity into our research data.
Data sharing is required when studying varying practices and outcomes using entities as the unit of analysis. Translational research, for example, uses institutional entities as the unit of analysis so researchers can compare outcome differences and patterns of practice.
My point is that one entity simply does not have enough data to fulfill our research needs. This is just on the data side, of course; in today’s global society, more and more researchers want to work with fellow scientists of experience and renown, who are spread across a number of different entities. We are always seeking additional ways to share and pool data. Therefore, out of necessity and over the years, we have been crafting a vision for data sharing.
CHR’s Vision for Data Sharing
It Must Be Fast
The first requirement for any data-sharing solution is that it must be fast; it must be able to move data quickly. In past research projects, we may have taken up to 2 years to develop sharable data standards. Now we cannot afford such luxuries.
It Must Be Cheap
Data sharing must be done cost-effectively. Fifteen years ago we had a large vaccine safety datalink study that required us to share data among a number of institutions. When we first started the project, we found that
we used 90 percent of the research dollars just to create the poolable data. That left only 10 percent of the funding to pursue the science and the knowledge that the data produced. Clearly something had to change.
It Must Be Sustainable
We have to conduct data sharing in a sustainable manner. As CHR’s chief information officer, I have viewed countless initiatives toward data warehousing and data sharing. Typically, they get about 2 or 3 years out then fail because the person who championed the project leaves the organization or because the effort became so grand and expensive that it simply collapsed.
It Must Be High Quality—with Understood Meanings
If our findings are used to make decisions that affect treatment and policy, we must be certain that our data are correct and of the highest quality. We also have to present the data in a way that is understandable. In other fields, we have seen extraordinary advancements in data warehousing and shared data, but often they have relatively simple operational data that are well understood. Health data can be very complex, so our bar is set even higher. The onus is on us to find methods and processes to inject higher quality into our data; furthermore, this involves providing metadata for a fuller understanding of the data’s meanings and limits.
It Must Be Safe
Because we are largely a collaborative research entity, nearly all of our research projects rely on sharing or pooling data across institutions. However essential, we also acknowledge that sharing data can be dangerous. Therefore, tight controls are imperative. Out of respect for study participants—and this is largely a compliance issue—we can no longer proceed as some did in the 1960s, 1970s, 1980s, and early 1990s, sharing data without restriction, sometimes even recklessly.
We need to be able to share data with specific use guidelines. We know that some of the regulatory restrictions placed on us (for good reasons) have made performing preparatory research difficult. Our data sharing solutions must allow for such preparatory work, largely in the area of compliance. Once we have the appropriate Institutional Review Board (IRB) approvals and participant authorizations, we need assurances that we have reasonable ways of sharing data—even fully identified data, not just limited data sets.
CHR’s Strategy: Virtual Data Warehousing
As stated earlier, our vision was to make data sharing fast, cheap, sustainable, high quality—with understood meanings—and safe. We needed to create a strategy to support that vision—and that was virtual data warehousing. The goal was to construct research-friendly, locally controlled data warehouses and associated data marts, without becoming prisoner to data warehousing methodologies. We also wanted to create networks of local interoperable data warehouses across collaborators to provide virtual data warehouses that would be well defined, at the byte level, the format level, and the standards and coding level.
How did we do that? At Kaiser Permanente, one of our largest areas and sources for data is our electronic health record. Unfortunately, at the operational level those data are in a hierarchical structure—MUMPS (Massachusetts General Hospital Utility Multi-Programming System), to be precise, which is virtually useless for querying and reporting. Initially, the MUMPS-based system was created to make things go fast so that the clinician wouldn’t have to wait up to 3 seconds for a computer response.
We needed to fix this problem. To draw the value we need from hierarchical data, we must have some version of those data in a relational state that is optimized for querying and reporting. Operational data, while necessary, do not sufficiently meet our needs. Relational data are sufficient, but not efficient; that is, they support payment, treatment, and operations, but they do not support research. Relational data, for example, tend to be departmental, designed to clarify what is happening in the inpatient or outpatient setting.
By contrast, what we need for research to be thoroughly optimized are data stores that focus on participants, patients, or disease areas. Therefore, we must take those data and create a second-level, locally controlled data warehouse that is optimized and research friendly. Without this step, we would have to go back to the relational data structure for payment, treatment, and operations, and do the acquisition, transformation, and publishing to derive research-friendly data—for every research study. This would be like going back in time to the vaccine study we did 15 years ago, when 90 percent of the research dollars went to answering the research question—and we know we don’t want to repeat that.
With research-based, locally controlled data warehouses, we are able internally to use those data quickly, cheaply, and expertly. Our ultimate goal is to include data pooling with partners who share our methods, so that when we have the appropriate approvals, we can pool those data and use them across entities. In fact, we have done this successfully within the Health Maintenance Organization Research Network (HMORN), which has 15 members. Not all of those members have committed to this practice,
but many have. The important thing is that we can collaboratively show data quickly, successfully, for more than 10 million patients per month.
We have also shared data successfully within the Oregon Clinical and Translational Research Institute and between a health maintenance organization and a university medical setting. A key question for us now is this: Do we want to take the HMORN methodologies and use them within and across CTSAs to find out which data are most useful and how we can advance data-sharing methodologies?
Creating Sharable Versions of Data
CHR is working with Oregon Health & Science University (OHSU) to recreate sharable versions of data that include enrollment, demographics, a tumor registry, a pharmacy, vital signs, procedures, diagnosis, and laboratories. These will be locally constructed and protected by governance rules and honest brokers to ensure that they are not shared without the appropriate approvals in place.
At the same time, we are building a biolibrary that allows researchers from both institutions to go across Kaiser Permanente tumor registries and histology data. They are able to access electronic inventories of slides and blocks in a way that quickly and easily helps scientists identify patients with specific diagnoses and stages of cancer—and then connect to those patients’ respective tissues. We believe this will save time dramatically; when we supplied similar requests in the past without such streamlining, the process took twice as long.
We also have set up the ability to work with OHSU scientists so they can find those retrospective fixed-formalin samples and identify participants of interest. This information will facilitate the acquisition of fresh tissue, appropriate authorization and consent from the patient, and successful collection and delivery to the research scientist.
Deidentified Data Marts, Counters, or Cubes
CHR is also focused on a specific aspect of data warehousing that involves counters or specific data marts. These can be shared across entities because the resulting data are deidentified, even for preparatory research purposes. The most important thing about counters or data marts, especially for preparatory research, is the speed with which these data can be shared. Data may be shared within an hour or, in most cases, in less than a day. This time line is crucial in meeting the lifecycle of a proposal that cannot wait 2 or 3 months to determine whether there are enough participants and appropriate tissue samples to move forward. Our cancer counter is an excellent example: We have a deidentified cancer cube that researchers can
use to see which participants might be usable within a study in response to a proposal.
This strategy has been practically tested within HMORN and the cancer research network. Simply put, it works—in terms of speed, quality, and especially compliance. With data pooling, compliance is a key issue and is vital to the process. The other key issue is defining and getting agreement on data ownership. We must contractually define how data are used and whether additional disclosures are required; then we must enact data use agreements, use agreements (if not limited data), IRB approvals, or some other sort of agreement. This is as vital as the technology; sometimes the political and social issues are more of a roadblock than the technical issues.
There is a fierce urgency now to advance on these ideas—especially among those who are ill. I have experienced years of discussions on the need to share data, and I look forward to the blossoming of some of the tools we have today. At this moment we have patients, citizens, and research participants who are depending on us to deliver information to them right now to improve or extend their lives. We cannot wait any longer to develop and roll out these tools. As we wait for this strategic unfolding, let’s not lose track of the tactical tools we already have today to move this work forward.
LARGE HEALTH DATABASE AGGREGATION
Steven Waldren, M.D., M.S.
Director of the Center for Health Information Technology, American Academy of Family Physicians
The holy grail of health information technology is its ability to drive rapid improvement in the quality and safety of healthcare delivery. To reach this goal, data must be correctly entered into applications in a structured and coded form. From there, data can be analyzed locally and aggregated into large health databases for further analysis at the population level. Given the current healthcare system, including rapidly growing health spending and increasing chronic disease burden, why has the industry not adopted and used this technology? The reason, like nearly any application of information technology, is not with the technology, but rather the business model.
The current financing of health care rewards high-cost, high-volume care—not low-cost, high-quality care. This produces a disconnect between those that need to invest in the technology and those that will financially benefit from the technology. Despite this misalignment, physicians are adopting health information technology to improve the efficiency in their offices and to improve the quality of care delivery. Physicians see the value of adopt-
ing EHRs to help them with documentation and managing complex patients, although this vision is tempered by the misalignment of payment. To realize this value, physicians are not required to highly structure and code clinical information, which is a prerequisite to data analysis and aggregation. As an industry, we need to produce products and services that allow physicians to value entry of highly structured and coded clinical information. Increasing this value can be through providing a means to manage and effectively document patient care or by lowering the financial barriers to entry of coded clinical information (e.g., increased payment for quality).
The American Academy of Family Physicians has been working to move the industry forward on these fronts: providing valued services, lowering technology costs, and advocating for quality-based payment. Standardization is an important tool to lower the costs of these systems and to provide a platform to build value. AAFP has worked to establish and promote HIT standards that are focused on clinical data, such as the ASTM Continuity of Care Record standard. The CCR has become the first widely available HIT content standard for core clinical patient data. The AAFP is now exploring the next step in establishing a clinical data repository for its members. The purpose of the CDR would be to promote three areas: quality improvement, pay for performance, and patient-centered medical home transformation. This repository would give physicians a set of services so they appreciate the value in entering highly structured, coded data. These services will likely borrow from the success of our medical association colleagues such as the American College of Cardiology and the Society of Thoracic Surgeons.
The first obstacle for data aggregation in the ambulatory environment is the adoption of standards-based HIT in the practice. The AAFP has spent 4 years to bring our members to the point that we can start aggregating data. Our work has been facilitating adoption of HIT in our membership and driving data standards. Membership EHR adoption is now between 40 and 50 percent. A member survey in late 2007 found that approximately 37 percent have a fully (by their definition) implemented electronic medical record system. Another 13 percent said they had purchased one or were in the process of implementation. When we examined the survey results more closely regarding individual functionalities used, the results were not particularly surprising. The functionalities adopted were in large part to help physicians with documentation, billing, and remote access to the EHR. Functionalities adopted did not focus on quality improvement, e-prescribing, or population management. In short, physicians in the field are adopting the EHR and other technologies, not in the interest of data aggregation but because they are under business constraints to obtain complete and accurate documentation and to maintain productivity. Additional functionalities must be adopted to achieve data aggregation at any level other than administrative data.
Data Collection Lifecycle
Obviously, if you do not have the data you cannot aggregate them. The data collection process has its own lifecycle. Today, for many healthcare organizations, the lifecycle does not include the entry of structured and coded data. Some organizations are still dictating all clinical documents. One can aggregate those documents, but that will not produce meaningful data aggregation or analysis.
Once data are coded, structured, and entered into an information system, the data needs to be in some type of standardized format so they can be aggregated across multiple systems and organizations. We found there is no good set of standards to do that. Many standards apply to health care, yet they are all about messages and documents; they are not about datasets and aggregating data. However, the ASTM CCR is an exception as it represents a patient-centric dataset that can be aggregated from multiple sources.
Another question is about policies relating to data aggregation, where privacy and confidentiality are concerns not only for the patient, but also the provider. Privacy and confidentiality, as well as security, issues can be a real impediment to data aggregation. If data privacy is not ensured, patients, clinicians, and healthcare organizations will not share their data. A national entity is needed to address these issues by establishing best practice standards for data aggregation. We have been working in the AQA Alliance to articulate the concept of a National Health Data Stewardship Entity. Two documents at http://www.aqaalliance.org describe the concept of the Entity, which is intended to define operating rules for data aggregation to ensure quality. We are finding that many of our members and hospitals say they cannot share data with aggregators because it would be a violation of the Health Insurance Portability and Accountability Act, but this is not always the case. We must get rid of the myths about privacy and security concerns and establish best practices for these issues to get buy-in from all stakeholders.
After Data Are Aggregated
Another issue is what happens to aggregated data. You have to do something with the data—you may have created and shared them, but they have no value until you start to use them; one of the Roundtable themes is to ensure that publicly funded data are used for the public benefit. A fundamental question is, why aggregate these data? Reasons include:
-
Quality improvement
-
Public reporting
-
Health services research
-
Clinical research
-
Healthcare value analysis
-
Biosurveillance
-
Population management
-
Public health
This is just a small list of some of the factors that AAFP members value. One of their top priorities is quality improvement, yet business constraints make it difficult for them to implement new technologies and develop new ways to improve quality.
Another priority of data aggregation is clinical research. We have established a practiced-based research network with thousands of physicians. We have a subnetwork of those with EHRs, and we are starting to aggregate those data. This does present challenges; for example, different electronic medical record systems codify data in different ways. The data models of the EHR differ not only across vendors but also across practices using the same EHR product. To deal with this diversity, we must either define a standard dataset for the vendor to produce or map each EHR database to a standard dataset. For now, at least, the decision is to map each EHR database. We have been working with a company to actually map the individual data structures to a common data structure based on the ASTM CCR.
Healthcare data aggregation and analysis is in the best interest of the U.S. healthcare system. In the short term, the potential financial and privacy risks to individual stakeholders must be managed appropriately. Without access to data and their analysis, one cannot improve quality, increase safety, or appropriately provide incentives for cost-effective care.
REGISTRIES AND CARE WITH EVIDENCE DEVELOPMENT
Peter Smith, Ph.D.
Professor and Chief of Thoracic Surgery, Duke University
Background
Cardiac surgery procedures are the most well-studied, evidence-based procedures performed today. Because of the high-risk, high-benefit, high-cost nature of the procedures, especially coronary artery bypass grafting (CABG), considerable research effort has been expended to ensure appropriateness of use. The Department of Veterans Affairs Cardiac Surgery Advisory Group was formed in 1972, creating the first multi-institutional database monitoring cardiac surgery outcomes; it monitored volume and unadjusted operative mortality. Seminal randomized clinical trials first dem-
onstrated life prolongation in patients with left main coronary disease. Subsequently, this benefit was demonstrated in patients with disease in two or more vessels when there was involvement of the left anterior descending coronary artery. Furthermore, CABG was shown to provide more benefit to patients with impaired ventricular function and to those with diabetes mellitus. These findings highlight the key principle that increased prospective risk of surgical mortality in CABG goes hand in hand with increased, demonstrated longevity benefit compared to medical therapy for all patients, and compared to percutaneous intervention for patients with multivessel disease (Smith et al., 2006).
In 1986 the Health Care Financing Administration (now the Centers for Medicare & Medicaid Services, or CMS) released a list of hospitals that had high risk-adjusted mortality rates for Medicare patients. This list received a great deal of notice because the risk-adjustment algorithm employed was, of necessity, based on administrative rather than clinical data, and was likely to be relatively ineffective. The potential for the unintended consequence of reducing the overall benefit of cardiac surgery through individual avoidance of risk by surgeons was viewed as a serious problem (DeLong et al., 2005). Accordingly, this initiative by the federal government stimulated the establishment of The Northern New England Consortium and the Society of Thoracic Surgeons’ Adult Cardiac Surgery Database to ensure that our profession had accurate risk-adjusted information on surgical performance.
The characteristics of the STS ASCD, a clinical database, was a response to the weaknesses inherent in administrative databases that should be clearly understood. In general, administrative databases contain prospectively collected demographic and financial information and retrospectively collected diagnostic and therapeutic information developed by professional hospital coders from chart review. Because of the way in which diagnoses are encoded, it cannot be determined if they were preexisting (and therefore are risk factors) or occurred as a result of the encounter (and therefore are complications). Additionally, there are financial incentives to “upcode” diagnoses, a process that will degrade their utility in risk adjustment. The coding process is designed to detect all possible diagnoses, which are then frequently sorted by financial importance and truncated in transmission, further reducing the applicability of the risk profile created for the encounter. Because the coding process is not specific to an encounter or disease, the absence of a diagnosis does not definitively mean that it was not present, a distinct liability. Finally, many diagnoses used for risk adjustment are “synthesized” from financial events occurring in the encounter, through questionable methodologies.
By contrast, a clinical database is designed to collect prespecified risk factors prospectively. Prespecification results in knowledge regarding the
definitive presence or absence of the most important risk-adjustment variables. Coupled with clinical definitions, the presence or absence of the specific diagnosis is free of bias. Complications and risk factors are separately recorded, assuring that the important distinction can be made. Finally, database entry is generally performed by clinical staff rather than professional coders, promoting accuracy of the data entered.
Database Description
The STS ACSD is the largest database of the three distinct databases that make up the STS National Database. The ACSD is a voluntary clinical registry developed for the purpose of continuous quality improvement in cardiac surgery. It contains more than 3 million surgical procedure records from 857 participant groups in 49 states, representing approximately 80 percent of adult cardiac surgical procedures performed nationally.
The database contains more than 250 data elements for each patient encounter. The data elements are prespecified and associated with clear definitions, particularly for medical conditions that affect surgical risk and for known complications of cardiac surgical procedures. The data dictionary has been modified extensively over the years as the nature of important risk factors has become clarified.
Data Entry and Verification
The current method of data entry is through certified software vendors, who must provide key-entry verification and real-time access to the field definitions. Several sites, including our own, have legacy systems for database predecessors to the STS ACSD. These system front-ends were unaffected by the creation of the STS ACSD, which harvests information from locally developed back-ends that are compliant with the STS data standards. Our system has been modified to a web-based application that can be pushed to a handheld PC. The web-based and handheld applications support patient lists for mid-level providers, who populate the local database as part of the care process. At the time of entry, most of the fields are thus capable of entry checking to increase data validity and reduce data entry error. STS is exploring the development of a web-based front-end for national use.
The STS data elements are important characteristics of each patient encounter, and are defined clinically for entry by care providers at the point of care. At Duke, interim reports are generated to become part of the ongoing patient medical record. The most important of these is the operative note, which is completely generated from the constructed database and provides a primary motivation for timeliness and accuracy.
Data are harvested quarterly and are subjected to extensive evaluation
against predefined norms to ensure accuracy. Risk adjustment algorithms have been created for mortality, morbidity, length of stay, prolonged ventilation, deep sternal wound infection, stroke, and renal failure. These are the most common serious complications patients encounter, and they contribute to both efficacy and expense of these procedures. The risk adjustment algorithms are updated with each data harvest and the included variables, coefficients, and algorithm intercepts are published for public scrutiny and use.
Sharing: Aggregate Data
The ACSD has been studied extensively using observational analytic methods, resulting in 69 publications and presentations. It has been shown to be more accurate than administrative databases and has been selectively audited and endorsed for public use in several states.
The ACSD was queried from 1995 to 1999 on the use of the internal mammary artery (IMA) as a conduit in bypass grafting. That has been well known to provide a survival advantage, but the penetration of its use has not been as great as it might be—only 60 percent in 1995. With publication of these observations (Ferguson et al., 2003), there was increasing prevalence of IMA use and improved outcome. These data have now been employed to support IMA use as a process measure in the CMS Physician Quality Reporting Initiative (PQRI).
In a similar project, supported by an Agency for Healthcare Research and Quality (AHRQ) grant, there was a focus on the use of beta blockers before cardiac surgery (Ferguson et al., 2002). In this study, we found that intervention (reporting actual use by the institution compared to national use, accompanied by evidence supporting use) caused an increase in beta blockade that was sustained through the 60 months of the study. This was also identified as a CMS PQRI measure, based on this evidence.
Several publications are available that are relevant to the concept of regionalization of surgery to promote high-quality outcomes (DiSesa et al., 2006; Peterson et al., 2004; Welke et al., 2007). Comparing coronary bypass grafting risk-adjusted mortality to annual hospital volume, for example, low-volume programs have a wide dispersion and high variance in risk-adjusted mortality compared to higher volume centers. The trend line is for higher volume centers to have better results. This has some important public policy implications in that evidence supporting expansion of primary percutaneous coronary intervention (PCI) sites for acute myocardial infarction is also promoting the fragmentation of cardiac surgery. The need for site-of-service cardiac surgery presence to promote better public access to primary PCI programs appears to be unsupported by evidence, yet it is commonly a regulatory requirement in many states.
ASCD data have been used to improve the accuracy of the Medicare
Physician Fee Schedule (Smith et al., 2007). A variety of inaccuracies had accrued in the Fee Schedule due to the survey methodology used to determine (estimate) physician procedure time. In the regular 5-year review, 600,000 cases from the STS database were analyzed to provide the actual times. Employing these times allowed these procedures to be accurately valued, removing many payment anomalies that resulted in inappropriate payment incentive, sometimes for inferior procedures! This use has engendered great discussion by all professional societies, and provided an important stimulus to develop similar clinical databases.
Finally, the ASCD has been employed to analyze the cost of complications, and resulted in the creation of the Virginia consortium through which a group of Virginia hospitals who participate in the STS database self-report results. By linking STS data to hospital cost systems, the institutional average cost per case has been compared to the observed/expected mortality ratio. This has shown that cost actually goes down as quality improves, principally due to the reduction of the cost of complications, which can be reduced by continuous quality improvement methods.
Sharing: Individual Surgeon and Program Data
The founding philosophy of the ACSD was to collect aggregate data, risk adjust nationally, and feed the information back to individual surgeons. Individual data are provided as well as deidentified group and regional and national data for benchmarking. As a result, over the past 7 years, STS/AHRQ grant programs have demonstrated that the use of a clinical data repository and feedback can rapidly change physician behavior on a national scale. This scientifically validated process cannot be accomplished using administrative data alone. The impact of this shared knowledge has been profound. Between 1994 and 2003, predicted coronary bypass grafting operative mortality has increased while observed mortality has declined (Figure 3-2) (Shroyer et al., 2003; Welke et al., 2004). In other words, there has been increased risk and improved performance. Its success is best demonstrated by a display of the “observed” divided by the “expected” ratio. The trend, using a constant model over time, has been downward, thus showing improvement in mortality outcome. Also, it is important to note that this constitutes professional self-regulation rather than mandatory external regulation (Figure 3-2).
STS currently has a set of 21 performance measures developed using the database and endorsed by the National Quality Forum (NQF). Compliance with this set of measures is specifically followed through a unique reporting mechanism to database participants. Recognizing the importance of composite measures, STS has developed a composite measure based on the NQF individual measure set. This hospital-level composite measure is
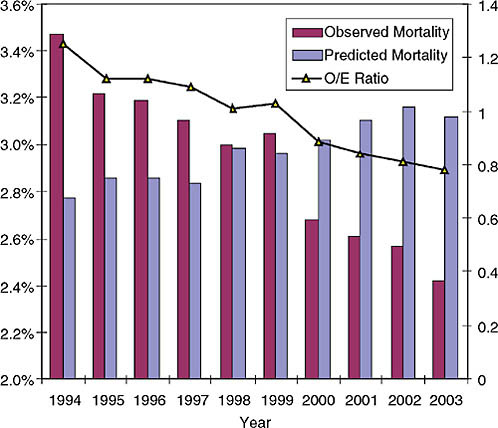
FIGURE 3-2 Observed and risk-adjusted coronary bypass grafting operative mortality trend between 1994 and 2003.
NOTE: O/E = observed/expected.
SOURCE: STS Adult Cardiac Database Isolated CABG Cases, 1994–2003.
reported as a one-, two-, or three-star rating system and is provided to all database participants.
Sharing: With Patients and Providers
The publicly available individual patient STS risk calculator,3 based on the most recent risk-adjustment algorithms, has been developed to rapidly disseminate knowledge to the bedside. This web-based online risk calculator can be employed to calculate prospective risk for a potential surgical patient with similar characteristics. Because it is publicly available, individual patients and their primary physicians can access the information
to improve their decision-making capability. This site, and other resources such as the risk algorithm coefficients and intercept, are examples of transparency, which is essential in evaluating all information sources that provide outcome corrected for inherent patient risk.
Sharing
With Other Databases
The value of linking this robust and accurate clinical database to other administrative and clinical databases is unlimited. The establishment of linkages can enhance the overall knowledge base, extend follow-up for adverse outcomes, and permit comparisons of providers, provider environments, and alternative therapies.
With Administrative Databases
The STS database currently follows patients only for 30 days or in-hospital, thus reporting short-term mortality and morbidity results. The relationship of long-term outcome to procedural intervention is of particular value in assessing chronic diseases. Therefore it is imperative that we expand the outcome horizon using the National Death Index or the Social Security Death Index. The expense of the National Death Index may be prohibitive unless a payment mechanism is found. At this time, only a few STS sites can afford to independently accrue long-term information.
Parallel linkage, adding new information by matching STS patient encounters to administrative databases, can also add tremendous value. An enormous amount of accurate, detailed information is available from hospital systems regarding drug use and other diagnoses and procedures that are not prespecified for inclusion in the STS database. These data can be matched directly, or through linkage to the secondary proprietary industry that has evolved to promote continuous improvement through benchmarking hospitals. The melding of these databases would vastly improve the ability to risk-adjust outcomes and to detect low-probability events that occur with too little frequency to justify prospective collection by STS. The recently announced Food and Drug Administration (FDA) Sentinel Initiative is likely to achieve this result through the Reagan-Udall Foundation, which will create public–private consortiums to share data, with the goal to provide postmarketing surveillance of drug safety.
The CMS longitudinal database for Medicare beneficiaries is perhaps the most critical linkage that has yet to be fully realized. Here, two-way interaction would provide the ability to more accurately risk-adjust outcome, provide access to all professional and hospital encounters following
a cardiac procedure, provide an unlimited outcome horizon, and provide an avenue for direct physician participation in CMS quality improvement initiatives such as the PQRI. Furthermore, this linkage would provide the ability to transform the PQRI from a process-oriented, budget-neutral (within Part B) program into an outcome-oriented, budget-neutral (within Parts A and B) program that would provide meaningful and appropriate incentives for physicians. Ensuring that publicly funded data are used for the public benefit is one of the themes of the Institute of Medicine’s Roundtable.
The critical importance of the role of CMS cannot be overemphasized. The powerful linkage of physician payment to the documentation of medical necessity remains essentially unexplored. CMS has the capability to develop beneficiary problem lists, and therefore national problem lists, through beneficiary-registering evaluation and management services. If the national will is to promote better payment for evaluation and management services, an initiative to pay for accurate clinical databasing would best serve the national interest and provide a better ability to assess the impact of fiscal interventions.
With Other Clinical Databases
Other existing clinical databases, administered by other professional societies or disciplines, have the potential to provide insight into other aspects of a patient’s health status.
An example of this potential has been realized at our Duke University STS site, where we have linked an enhanced STS dataset to the local Duke cardiology registry, which is a subset of the American College of Cardiology and its national registry, the National Cardiovascular Data Registry (NCDR). By adding longitudinal outcome data through locally supported patient contact and interaction with the National Death Index, we have been able to evaluate the three main treatment alternatives for patients with documented coronary artery disease (coronary artery bypass grafting, percutaneous coronary intervention such as stenting, or optimal medical therapy).
We published data on 26,000 patients with significant coronary disease (Smith et al., 2006). We looked at the percentage of patients treated with PCI, and found that it increased from 20 percent in 1986 to about 60 percent in 2005. The data show the introduction of the bare metal stent, and then the drug-eluting stent, were associated with these trends, and with the overall downward trend of coronary bypass grafting. In evaluating the outcome impact of these trends in treatment selection, we found that there was a longevity benefit with CABG compared to PCI (Figure 3-3) and that the CABG advantage was increasing despite theoretical advances in PCI (Figure 3-4) and PCI’s increasing application. These findings were replicated
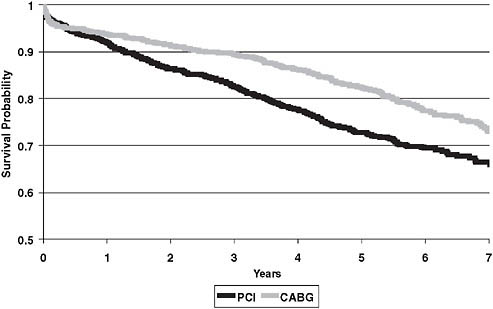
FIGURE 3-3 Trend comparison of CABG to PCI.
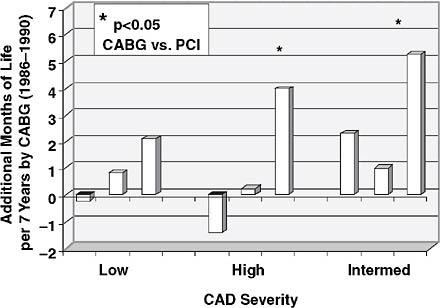
FIGURE 3-4 Increase in CABG advantage despite theoretical advances in PCI.
SOURCE: This article was published in the Annals of Thoracic Surgery, Vol. 82, Smith, PK et al., “Selection of Surgical or Percutaneous Coronary Intervention Provides Differential Longevity Benefit,” pp. 1420–1429, © Elsevier (2006).
in three other regions: northern New England (Malenka et al., 2005), the Midwest (Brener et al., 2004), and New York (Hannan et al., 2005)—made possible by clinical data sharing among specialties.
The logical extension of this work is to develop a national partnership with the American College of Cardiology NCDR, so that all sites participating in both STS and NCDR could share data. If augmented, at a minimum, by the National Death Index, it would become possible to better evaluate competitive/complementary therapies for cardiovascular disease. In addition, this would enable protection of the public health via liaison with the FDA to follow postmarketing outcomes of a variety of devices being introduced as treatment options for cardiac patients (e.g., new coronary stents and percutaneous valve repair/replacement devices).
Challenges to Database Use for the Public Good
The first challenge to data sharing for the public good is the willingness of data owners to be transparent and enabling. In large part this is because of valid concerns about proper use of aggregate information, primarily because of the difficulties inherent in observational data analysis. National standards and consensus regarding reliable analytic methodology and publication requirements are lacking, and much of the public reporting relies on administrative data adjusted by proprietary methods that prevent verification. Standards and consensus are essential to achieve the stated goals.
The second challenge is to develop systems that collect data as coded clinical information as a natural component of the patient care process, along with the resources to make this cost neutral to care providers. This will require cooperation among professional societies to standardize medical language, and cooperation with payers to reward participation in this process because it is for the common good.
The Role of Payers and the Professions
We are entering an era when payers are leveraging their control of physician and hospital payments to promote improvement in the nation’s health. Their reliance on administrative data and process measures, and their reluctance to compensate for participation in the reporting of reliable clinical information and for outcome improvement, is concerning. The pathway to the least common denominator, which today is physicians and physician groups who lack access to reliable and pertinent aggregate patient information, will not suffice.
The development and utility of the STS database is hopefully an example of professional self-regulation that should be promoted. Only through transparency of information and self-reporting through databases will we
restore the public trust in physicians. Clinical databasing and data sharing, promoted by the health system, will empower the fulfillment of professional responsibility.
REFERENCES
Brener, S. J., B. W. Lytle, I. P. Casserly, J. P. Schneider, E. J. Topol, and M. S. Lauer. 2004. Propensity analysis of long-term survival after surgical or percutaneous revascularization in patients with multivessel coronary artery disease and high-risk features. Circulation 109(19):2290–2995.
DeLong, E. R., L. P. Coombs, T. B. Ferguson, Jr., and E. D. Peterson. 2005. The evaluation of treatment when center-specific selection criteria vary with respect to patient risk. Biometrics 61(4):942–949.
DiSesa, V. J., S. M. O’Brien, K. F. Welke, S. M. Beland, C. K. Haan, M. S. Vaughan-Sarrazin, and E. D. Peterson. 2006. Contemporary impact of state certificate-of-need regulations for cardiac surgery: An analysis using the Society of Thoracic Surgeons’ National Cardiac Surgery Database. Circulation 114(20):2122–2129.
Ferguson, T. B., Jr., L. P. Coombs, and E. D. Peterson. 2002. Preoperative beta-blocker use and mortality and morbidity following CABG surgery in North America. Journal of the American Medical Association 287(17):2221–2227.
Ferguson, T. B., Jr., E. D. Peterson, L. P. Coombs, M. C. Eiken, M. L. Carey, F. L. Grover, and E. R. DeLong. 2003. Use of continuous quality improvement to increase use of process measures in patients undergoing coronary artery bypass graft surgery: A randomized controlled trial. Journal of the American Medical Association 290(1):49–56.
Hannan, E. L., M. J. Racz, G. Walford, R. H. Jones, T. J. Ryan, E. Bennett, A. T. Culliford, O. W. Isom, J. P. Gold, and E. A. Rose. 2005. Long-term outcomes of coronary-artery bypass grafting versus stent implantation. New England Journal of Medicine 352(21):2174–2183.
Malenka, D. J., B. J. Leavitt, M. J. Hearne, J. F. Robb, Y. R. Baribeau, T. J. Ryan, R. E. Helm, M. A. Kellett, H. L. Dauerman, L. J. Dacey, M. T. Silver, P. N. VerLee, P. W. Weldner, B. D. Hettleman, E. M. Olmstead, W. D. Piper, and G. T. O’Connor. 2005. Comparing long-term survival of patients with multivessel coronary disease after CABG or PCI: Analysis of BARI-like patients in northern New England. Circulation 112(9 Suppl): I371–I376.
Peterson, E. D., L. P. Coombs, E. R. DeLong, C. K. Haan, and T. B. Ferguson. 2004. Procedural volume as a marker of quality for CABG surgery. Journal of the American Medical Association 291(2):195–201.
Shroyer, A. L., L. P. Coombs, E. D. Peterson, M. C. Eiken, E. R. DeLong, A. Chen, T. B. Ferguson, Jr., F. L. Grover, and F. H. Edwards. 2003. The Society of Thoracic Surgeons: 30-day operative mortality and morbidity risk models. Annals of Thoracic Surgery 75(6):1856–1864; discussion 1864–1865.
Smith, P. K., R. M. Califf, R. H. Tuttle, L. K. Shaw, K. L. Lee, E. R. DeLong, R. E. Lilly, M. H. Sketch, Jr., E. D. Peterson, and R. H. Jones. 2006. Selection of surgical or percutaneous coronary intervention provides differential longevity benefit. Annals of Thoracic Surgery 82(4):1420–1428; discussion 1428–1429.
Smith, P. K., J. E. Mayer, Jr., K. R. Kanter, V. J. DiSesa, J. M. Levett, C. D. Wright, F. C. Nichols, III, and K. S. Naunheim. 2007. Physician payment for 2007: A description of the process by which major changes in valuation of cardiothoracic surgical procedures occurred. Annals of Thoracic Surgery 83(1):12–20.
Surgeons, Society of Thoracic. 1994–2003. Adult Cardiac Database Isolated CABG Cases.
Welke, K. F., T. B. Ferguson, Jr., L. P. Coombs, R. S. Dokholyan, C. J. Murray, M. A. Schrader, and E. D. Peterson. 2004. Validity of the Society of Thoracic Surgeons National Adult Cardiac Surgery Database. Annals of Thoracic Surgery 77(4):1137–1139.
Welke, K. F. , E. D. Peterson, M. S. Vaughan-Sarrazin, S. M. O’Brien, G. E. Rosenthal, G. J. Shook, R. S. Dokholyan, C. K. Haan, and T.B. Ferguson. 2007. A comparison of cardiac surgical volumes and mortality rates between the Society of Thoracic Surgeons and Medicare datasets. Annals of Thoracic Surgery 84:1538–1546.




























