
2
U.S. Healthcare Data Today: Current State of Play
INTRODUCTION
Clinical data hold the potential to help transform the U.S. healthcare system. By providing greater insight to patients, providers, and policy makers into the appropriate application of interventions, and quality and costs of care, these data offer the opportunity to accelerate progress on the six dimensions of quality care—safe, effective, patient centered, timely, efficient, and equitable (Chaudhry, 2006; IOM, 2001, 2009; Safran et al., 2007). Understanding the scale of this potential and of the missed opportunities to improve health and health care due to gaps in data collection or barriers to their use requires an overview of existing healthcare data—the sources, types, accessibility, and uses. Through examples of healthcare data used to manage and drive improvements in care and for healthcare marketing, this chapter explores important aspects of healthcare data in the United States—examines what drives the collection of these data and the accessibility of these data for new clinical insights; reflects on how well these data are used and key barriers to wider use; and focuses attention on how clinical data from all sources—both public and private—could be made more widely useful to monitor clinical effectiveness.
As reviewed in this chapter, data are collected on socioeconomic, environmental, biomedical, and genetic factors; individual health status and health behaviors; biomedical and genetic factors, as well as on resource use, outcomes, financing, and expenditures. These data are stored in a variety of electronic health records (EHRs), personal medical records, disease registries, and other databases. However, the distribution of clinical
data across the healthcare system is highly fragmented, presenting significant opportunity for those offering services that coordinate and aggregate data resources. To generate and organize data for evidence-based decision support, it will be important to explore technologies to enhance interoperability, data standardization, and compatibility for future data utilities. Leveraging access to both administrative and clinical data may require additional investments in developing linkages across the variety of healthcare data and data warehouses. Furthermore, emerging opportunities to deliver data at the point of care for healthcare decisions may enhance the public’s involvement in data-mining, data-sharing, and data-generating initiatives. Given the broad range of data sources and possible applications, a national strategy is needed to develop the requisite infrastructure and fill existing gaps in data collection and use.
Speaking from his experience at Kaiser Permanente and in his role as chair of the National Committee on Vital and Health Statistics (NCVHS), Simon Cohn offers an overview of current major activities in healthcare data collection and database capacity development, including those related to administrative and claims data, quality indicators, health status and outcomes data, clinical research data, industry-sponsored pre- and postmarket studies, regulatory studies, registries, and emerging datasets. To help frame the discussion, Cohn presents a taxonomy for health data, then reflects on key issues and barriers to address as we move to a learning health system. Cohn highlights the NCVHS recommendations for enhancing protections for secondary uses of data collected electronically as particularly informative for advancing the clinical data agenda. In the area of enhanced health data stewardship, NCVHS recommends that covered entities be more specific about what data will be used, how, and by whom; that notices of privacy practices need to be more meaningful; and that data stewardship needs to extend to personal health data held by noncovered entities in personal health records and similar instruments.
Massachusetts Health Quality Partners (MHQP) aggregates healthcare data to measure and report on physician performance in a more meaningful and transparent way—creating reports on performance at the physician network, medical group, practice site, and individual physician level, for both doctors and consumers. MHQP Executive Director Barbra Rabson shares aspects of this model, including its success in influencing investments in information systems to support quality and incentives for individual physicians and the challenges of engaging consumers. Overall, Rabson suggests, the MHQP experience and similar models hold promise for a world in which EHRs would be more fully and effectively integrated into medical practice, and clinical, claims, and personal data would be more fully integrated for quality improvement initiatives.
For decades, researchers and clinicians have taken advantage of sources
of rich clinical and population-based data to generate new insights, stimulate major research programs, and develop robust clinical guidelines. Michael Lauer, director of the Division of Prevention and Population Sciences at the National Heart, Lung, and Blood Institute (NHLBI), asserts that to achieve the goal of the IOM Roundtable, clinical data ultimately will need to be integrated across the research and care delivery continuum and be made available to patients, clinicians, and researchers. Examples from abroad and within U.S. health systems, such as the Health Maintenance Organization Research Network (HMORN) and the Department of Veterans Affairs, demonstrate that rigorous and prospective data collection can be incorporated into routine clinical care. Still, most clinical data are not collected at the point of care, and most are organized in isolated silos that are difficult to access. As data are increasingly integrated within the care continuum, Lauer cautions against using inherently biased observational data in lieu of well-designed experimental data for synthesizing evidence-based policy recommendations. Although confounders in observational data can be statistically controlled to reduce biases somewhat, an ongoing national need remains for enhancing, networking, and analyzing existing data.
Three major types of data are used by public and private entities to market healthcare products and services: health survey data, information about general consumption patterns, and administrative data generated by the healthcare delivery system. William Marder, senior vice president of the research and pharmaceutical units of Thomson Healthcare, reports on the use of data assets by providers and pharmaceutical companies, describing business models for the collection and analysis of these data.
CURRENT HEALTHCARE DATA PROFILE
Simon P. Cohn, M.D., M.P.H.
Chair, National Committee on Vital and Health Statistics
Associate Executive Director, The Permanente Federation, Kaiser Permanente
This section aims to provide a brief overview of major current activities in healthcare data development and collection—including administrative and claims data, quality indicators, health status and outcomes data, clinical research data, industry-sponsored pre- and postmarket studies, regulatory studies, registries, and emerging datasets. The goal is to lay the groundwork and provide a context for addressing a variety of salient issues surrounding these data sources. Included are general comments about U.S. healthcare data today, with a view toward the future and a framework and taxonomy for health data, followed by reflections on key issues and barriers
that must be addressed before successfully moving forward. The conclusion contains an overview of a recent report from the NCVHS (or “the Committee”) that was requested by the Department of Health and Human Services (HHS) to further investigate and consider “secondary uses” of electronically collected and transmitted healthcare data as we move into the world of the Nationwide Health Information Network (NHIN).
Background on the NCVHS
The NCVHS is a statutory public advisory committee to the HHS. It has a 59-year history of advising on national health information policy, including health data, standards, statistics, privacy, and issues related to developing the National Health Information Infrastructure (NHII). It has 18 members—16 appointed by the HHS Secretary and 2 by Congress. Members are leaders and experts in their field (e.g., public health, healthcare informatics, data standards, population health, privacy, and confidentiality). The NCVHS has a well-deserved reputation for open collaborative processes and the ability to deliver timely and thoughtful recommendations. These attributes allow it to work closely and effectively with HHS organizational entities such as the Office of the National Coordinator (ONC), with a particular focus on challenging and difficult crosscutting issues.
The NCVHS has a congressionally mandated role in relation to the Health Insurance Portability and Accountability Act (HIPAA), advising the HHS Secretary on HIPAA regulations and standards related to healthcare data, privacy and security, administrative and financial transactions, and healthcare identifiers. HIPAA code sets, including International Classification of Diseases (ICD), Current Procedural Terminology (CPT), and HIPAA Identifiers (including the National Provider Identifier), are key parts of the data infrastructure, and the NCVHS advises about the need for changes to those standards. Finally, the Committee monitors HIPAA implementation and advises Congress and the HHS Secretary with yearly status reports.
In 2000, as part of its charge under HIPAA, the NCVHS set forth a strategy, a framework, and selection criteria for interoperable clinical data standards.1 This work provided the foundation for the selection of clinical message format standards and clinical terminology standards in 2002 and 2003, which became the core of Consolidated Health Informatics standards. Many of the standards were accepted by then-HHS Secretary Thompson and subsequently became key inputs to the Healthcare Information Technology Standards Panel (HITSP) process. Also, as part of the Medicare Modernization Act (MMA), the NCVHS was asked to investigate and advise the Centers for Medicare & Medicaid Services (CMS) and HHS
on standards for e-prescribing—standards that have been accepted as part of federal rule making.
In 2001, after several years of investigation and hearings, the NCVHS published a strategic vision and strategy for building the NHII. The heart of the vision for the NHII is sharing information and knowledge appropriately so it is available to people when they need it to make the best possible health decisions. The NHIN is only one part of the larger vision: the NHII includes not only technologies, but more importantly, values, practices, relationships, laws, standards, systems, and applications to support all facets of individual health, health care, and public health (NCVHS, 2001). One important part of this report was an early recognition of the importance of HHS leadership, and a call for an office within the HHS reporting to the HHS Secretary, to coordinate and move this effort forward. Subsequently, the Office of the National Coordinator was created within the HHS.
Since the development of that office, the NCVHS has been tasked with working with the HHS and the ONC to deal with the more challenging cross-cutting issues—such as privacy and the implications for the NHIN. While not answering all questions, because it is unclear how the NHIN will develop and evolve, the NCVHS is beginning to pose the important questions and to start public discussions. The NCVHS has also recommended initial functional requirements for the NHIN and recently produced a report on enhanced protections for uses of health data in the context of NHIN. The NCVHS also investigates and makes recommendations to the HHS Secretary on healthcare quality measurement and data and on population health issues in general. Much of the following is based on the groundbreaking work of the NCVHS.
Health and Healthcare Data: Framework and Taxonomy
When thinking about evidence-based medicine and about the data or taxonomies needed to support that work, it is important to take a broad view of all possible factors that impact (or are impacted by) health and health care. Figure 2-1 was developed by the Committee in conjunction with the National Center for Health Statistics and the HHS Data Council and published in 2002 (NCVHS, 2002). This graphic provides a reminder of the many influences on the health of the nation. In the context of this discussion of more traditional health and healthcare data, as well as of issues and barriers, it is important to recognize how much information we do not routinely collect, or if we do, we do not normally integrate it into our vision of health and health improvement.
This NCVHS work was an important input to subsequent efforts to develop simpler, more approachable health and healthcare conceptual frameworks internationally. Figure 2-2, for example, shows a conceptual frame-
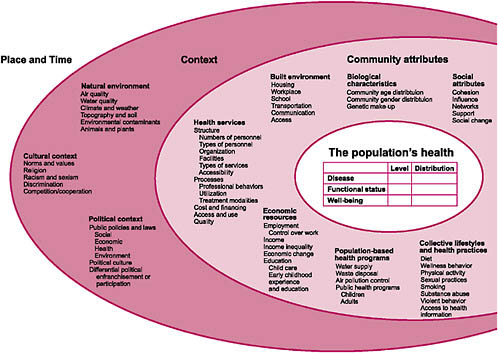
work, initially developed by the Australian Institute of Health and Welfare, for health system planning. It was subsequently published by the World Health Organization—which has used the diagram as a tool for healthcare terminology and classification planning (Madden et al., 2007).
This useful tool frames thinking about the data needed for a learning healthcare system as well as the development of sound health policy. In the center are the key concerns we need to monitor and focus on: health and well-being, including key aspects such as life expectancy, mortality, our own sense of well-being, state of functioning and disability, and, of course, illness, disease, and injury. Impacting these are health system interventions, including prevention and health promotion, and the major activity of the healthcare system—treatment, care, and rehabilitation. Determinants are important inputs into health and well-being such as biomedical and genetic factors, health behaviors, socioeconomic factors, and environmental factors. Impacting our ability to make interventions are resources and systems—human, economic, and others. This particular graphic begins to frame the discussion as we think about evidence-based medicine and data needs going forward.
The taxonomy represented in Box 2-1 provides more specifics. Used by
FIGURE 2-2 A conceptual framework for health.
SOURCE: Madden et al. (2007). Reprinted with permission from the World Health Organization © 2007.
the HHS Data Council for health data and health statistics planning, this taxonomy is focused on what we would traditionally describe as healthcare data and represents data that are central to a learning health system. One notable component of this taxonomy is its explicit recognition of the importance of longitudinal data. Unless we can understand the key factors that influence outcomes (including underlying health status and socioeconomic data) and connect them with the interventions and outcomes, it becomes difficult to have a learning health system.
|
BOX 2-1 Taxonomy Used by HHS Data Crucial for Health Data and Statistics Planning
SOURCE: Adapted from HHS Data Council (2007). |
Key Infrastructure Barriers, Issues, and Suggested Next Steps
A number of infrastructure issues must be resolved to move to a true learning health system. The good news is that work is under way on some identified issues and others may be relatively inexpensive to resolve. Later chapters will address the political and competitive barriers and issues regarding a learning health system.
A barrier in the current healthcare data environment to implementation of the frameworks and taxonomy discussed is the wide distribution of data across the system and significant fragmentation of the data. Given the fact that the national healthcare enterprise consumes 16 percent of the gross national product and given the complexity of the human organism, it is not surprising that the system would be complex and the data systems complex. Currently, data are collected and held in many places—by the patient, provider(s), payers, and government repositories for public health and planning purposes, to name a few. Some of the data held are discrete and unique, and in other cases an extract or copy of data produced as a result of a healthcare interaction or event is stored. Few places, however, have comprehensive, longitudinal views about individuals. The inability to connect data that may include risk factors, medical history, and interventions in a comprehensive way is a fundamental flaw in moving forward. The hopeful news is that the vision of the NHIN is intended to help consolidate the data, but we are rife with fragmentation of health and healthcare data at this point.
In addition to the fragmentation of data, the data itself represented in the framework and taxonomy are heterogeneous. Some of the data—such as diagnosis (ICD), procedure (CPT), medication (National Drug Code or NDC), and other administrative data as required in HIPAA administrative and financial transactions—are usually of relatively high quality, coded, and computerized. Laboratory data are becoming increasingly standardized and codified; however, most other data are not available in a computerized form, or are generally in free text even if computerized. EHRs offer the opportunity for computerization and codification of additional key data elements; however, there is limited penetration of EHRs and thus “incomplete” computerization of data in health care.
Another issue of concern is variation in the timeliness of data. Timing ranges from clinical data (coded or not) being almost immediately available, at least for caregiving, to coded administrative data, which may take days or weeks to become available, to health statistics in government repositories used for planning purposes or research databases, which may lag by 1, 2, or more years.
Lest readers react in despair about the widely distributed nature of the data, uneven data quality, and time delays, previous testimony has
highlighted what we have learned from the current distributed environment. In particular, institutions such as Mayo, Kaiser Permanente (KP), the Veterans Administration (VA), and the Department of Defense (DoD) have longitudinal stores of relatively comprehensive, high-quality information on their patients. This is infrastructure that can be leveraged now to help identify evidence-based best practices. Certainly, the work of the ONC and HHS toward the vision and instantiation of the NHIN needs our support. Various initiatives that are also under way to help consolidate healthcare data for important purposes such as quality measurement deserve ongoing support and encouragement.
Considerations During the National Transition to EHR
To achieve the goal of having most decisions based on evidence as we move toward widespread EHR implementation, two focuses are needed. First, we need to be able to identify those evidence-based best practices, then we need ways to communicate those best practices to the clinician in a way that supports work overflow and high-quality clinical care.
The first focus, which is extensively discussed in this roundtable report, relies heavily on access to comparable and standardized data. Such data standardization and comparability, as we move towards fuller use of EHRs, requires uniform healthcare messaging standards (e.g., HL7 messages), an area that has received significant national attention, and robust healthcare terminologies and classifications, an equally important requirement that has, until recently, received much less attention As EHRs are being implemented, they are increasingly using clinical terminologies to codify their data, such as the Systemized Nomenclature of Medicine (SNOMED) and Logical Observation Identifiers Names and Codes (LOINC). Thus, for some time to come, we will need to consider strategies that can leverage claims, administrative health data, and the more specific, clinically rich information that is expected to come from EHRs.
In 2003–2004, the NCVHS looked at this transition issue and recommended a set of clinically rich terminologies to form a core for EHRs, calling for an aggressive mapping strategy between these and the HIPAA-mandated terminologies and classifications. The National Library of Medicine was asked to take the lead on this, but the mappings have been notoriously difficult (especially trying to map an archaic ICD classification to more modern clinical terminologies). Another problem is that both sides of the mapping have ongoing changes, so the mapping requires significant upkeep and runs the risk of being inaccurate.
We are encouraged by the current discussions about harmonization between SNOMED and ICD and plans to develop ICD-11—building off of an ICD-10 base, which includes plans to develop the clinical richness
of SNOMED with the classification discipline and international use of ICD. Linking administrative classifications and clinical terminologies could become an important tool and part of a transition strategy to help maximize the use of computerized data through both the transition to EHRs and the newer versions of ICD. Issues of concern remain, however. These include lack of adequate funding—the ICD-11 classification development work, for example, is currently funded mostly by the Japan Hospital Association. It is in our own national self-interest to get behind this as a way to ensure maintenance of the value of our data as we continue the transition to more current classifications and EHRs. A second issue is that U.S. representation needs to be further strengthened. We need to have a strong voice in how this goes forward because it will be an important piece of the infrastructure.
Other data terminology issues remain as we move forward with clinical interoperability and the implementation of standards and clinical terminologies to support MMA e-prescribing and the transition to EHRs and the NHIN. Clinically rich data, all standardized and interoperable, will provide a fertile environment for the learning health system, but many of these terminologies will be stretched to their limits. Unforeseen problems will need to be remedied. The bottom line is that federal terminology development and improvement initiatives are extremely underfunded. Furthermore, we will need adequate funding to fix problems and fill gaps as these standards and terminologies go into wider use.
Lack of quick action to fix problems will slow widespread adoption of EHRs and may undermine the NHIN. We are not talking about a huge amount of money: Funding in the range of $10 million per year may be sufficient to deal with both U.S. contributions and these real-world data issues.
The second critical issue is communicating evidence-based best practices to the clinicians in a way that supports workflow and high-quality clinician care—in other words, optimizing clinical decision support (CDS). Determination of best practices is critical, but the rate is limiting step may be getting that information to the busy care provider at the point of care in a way that is useful and actionable, and will impact decision making. These practices range from flu shot reminders to warnings about potential medication complications, and the number of evidence-based guidelines and recommendations continues to explode. There is no lack of evidence-based practices. (Most physicians have binders full of them written by their own organizations, by specialty societies, by accrediting organizations, by governmental organizations, etc.) For example, the Agency of Healthcare Research and Quality has 342 guidelines in its national clearinghouse on cardiovascular disease alone.
Unfortunately, although CDS exists in many healthcare organizations that have EHRs, it is generally proprietary and nonstandardized, and there
is no widespread agreement on how to share CDS information among organizations in an automated fashion. Furthermore, rules themselves are frequently not developed in a way that encourages computerization. Although CDS seems to work well with data entered within an EHR by an individual organization, the ability to merge and leverage data coming from elsewhere, especially administrative data, remains an issue (including trust issues). Work is being done in this arena, but significant efforts will be needed to address this important barrier to the vision of a learning healthcare system.
Enhanced Protections for Secondary Uses of Health Data
A transformation in health and health care is being enabled by health information technology (HIT): electronically available health data are no longer just claims data, but include more clinically rich data and can be linked more readily with other databases. This affords an opportunity to assess clinical outcomes over time, but also creates the risk of data being linked to databases that might jeopardize privacy, employment, or insurance eligibility. Sources and holders of electronic health information are expanding beyond HIPAA protections for personal health records (PHRs). Additionally, in areas such as personal EHRs, electronic solutions to protect and secure data continue to evolve, including the emergence of approaches to allow individual consent to follow data.
Against this backdrop, the NCVHS was asked last year by the ONC to look at issues and opportunities related to expanded uses of health data as we move from paper to electronic and from point-to-point data exchange to the vision of a nationwide health information network. The NCVHS was asked to develop an overall conceptual and policy framework to balance risk, benefits, obligations, and protections of various uses of health data. The Committee was also asked to develop recommendations for the HHS on possible next steps, including recommendations on data stewardship principles and approaches and other measures to enable optimal uses of health data while respecting individual privacy (NCVHS, 2007). The NCVHS was asked to pay particular attention to health data used for quality measurement, both for reporting and quality improvement—fundamental to a learning health system.
The committee held 8 days of hearings and heard from more than 60 people in person, with additional input received electronically. Two major themes emerged from the testimony. The first theme was the acknowledgment of the great benefit that can be achieved using electronic health data, including: improvements in care and care coordination; improved, more streamlined, and less burdensome quality measurement and reporting; automated monitoring for complications of drugs and devices; and
improved public health surveillance. Benefits from health data enabled by HIT/HIE (health information exchange) include timely access to information with relevant decision support, coordination of care across providers, automated and structured data collection for quality measurement and reporting, expedited accrual of cases for timely identification of complications from drugs and devices, and timely public health surveillance and responsiveness.
The second theme was a concern about the potential for harm, including the possible erosion of trust with potential compromise in health care when there is a divergence between expected and actual use of health data. Discrimination or confidentiality concerns may be amplified with increased ability to collect longitudinal data, coupled with sophisticated means to reidentify data.
To guide the development of recommendations and maintain consistency with other NCVHS work, the committee developed guiding principles for evaluating each recommendation. These principles include precepts that healthcare data protections should: maintain or strengthen an individual’s health information privacy; enable improvements in the health of Americans and the healthcare delivery system of the nation; facilitate appropriate uses of electronic health information; increase the clarity and understanding of laws and regulations pertaining to privacy and the security of health information; and build on existing legislation and regulations whenever they are appropriate and do not result in undue administrative burden. The purpose was not to recreate HIPAA or create new regulatory or legislative burdens—in fact, many of the recommendations fall into best practices, guidance from the HHS, model forms and contracts, and similar approaches.
The recommendations fell into several categories. First, in the area of enhanced health data stewardship, it was recommended that covered entities strengthen the terms of their business associate contracts to be more specific about what data will be used, how, and by whom. Included is the recommendation that covered entities and their business associates confirm on a regular basis that practices are in compliance with the business associate contract. Second, recognizing the importance of guaranteeing transparency to the patient when data are applied for research, also a Roundtable goal, another recommendation was that the notice of privacy practices needs to be more meaningful, and individuals should be able to request and be supplied with additional information about what specific uses and users there are of their data—drawn from greater specificity in the business associate contracts. Third, data stewardship also needs to extend to personal health data held by noncovered entities in personal health records and similar instruments. The HHS and its offices have roles in this regard to monitor adherence to posted privacy policies, and this may be an area for legislative assistance (NCVHS, 2007).
The Committee paid special attention to uses of health data that are most immediately enhanced through HIT and HIE—quality measurement, reporting and improvement, and research—all fundamental to a learning health system. For example, the Committee reaffirmed that uses of health data for quality measurement, reporting, and improvement are within the scope of HIPAA Treatment, Payment, and Operations when conducted by covered entities. It was suggested that, as the industry begins the transition to HIE and an NHIN, there needs to be evaluation of new tools and technologies—which could include tools to help individuals manage their authorizations and new methods and techniques to deidentify health data. (This is an area for HHS and ONC leadership.) Finally, the NCVHS recognized that HIPAA has limits. Other protections beyond data stewardship may be needed, and certainly HIPAA protections only apply to covered entities. The NCVHS has long supported more inclusive federal privacy legislation to cover all organizations that have access to personal health data. At a minimum, expanding HIPAA coverage to new entities that are holding personal health information (PHI)—such as personal health record vendors, data banks, and similar entities—makes sense.
As next steps, the NCVHS plans to further investigate uses of deidentified data and how data stewardship might apply. The Committee is also monitoring work of both the Office for Health Research Protections and the Office of Civil Rights and may have further hearings related to the issues of overlap of quality and research.
In conclusion, the challenges are many. The good news is that significant initiatives are underway. However, many key issues identified continue to need national attention and focus to create a true learning health system.
DATA USED AS INDICATORS FOR ASSESSING, MANAGING, AND IMPROVING HEALTH CARE
Barbra G. Rabson, M.P.H.
Executive Director, Massachusetts Health Quality Partners
Background
Massachusetts Health Quality Partners is a multistakeholder coalition established in 1995 by a group of healthcare leaders who recognized the importance of having valid, comparable measures to drive quality improvement. The partnership includes physician, hospital, and health plan representatives, as well as representatives of government, consumer organizations, academic institutions, and employers. A guiding philosophy of
MHQP is that those being measured should be involved in the measurement process. Another is that through a collaborative process (e.g., aggregating data across health plans), we can improve care better together than any one plan or stakeholder group can do alone. This collaborative process philosophy falls in line with the Roundtable’s theme of developing the business case for expanded data sharing in a distributed network.
MHQP reports trusted, reliable information to physicians to help them improve the quality of care they give their patients, and to consumers to help them take an active role in making informed decisions about their health care. This dual commitment to both physicians and consumers creates a healthy tension for MHQP. Ultimately, we believe consumers will have greater confidence in healthcare quality data if the data are trusted by their physicians.
This paper will discuss the work MHQP has done over the past several years to measure and report on physician performance, both privately and publicly, using health plan and Medicare claims data. It will focus on the benefits and challenges of using large aggregated databases for performance measurement, including MHQP’s experience as one of six Better Quality Information (BQI) pilot sites involved in aggregating Medicare and commercial data. It will also reflect on recent efforts to capture electronic clinical data to measure and report on physician performance in partnership with the Massachusetts eHealth Collaborative. Finally, it will discuss the impact of MHQP’s performance reporting to date and identify opportunities to create more meaningful quality measures from existing and future data sources.
MHQP’s clinical measurement reporting has evolved since the organization began to report on the performance of Massachusetts physicians in 2004. We currently engage in four clinical reporting initiatives:
-
Aggregation of Healthcare Effectiveness Data and Information Set (HEDIS) data across health plans;
-
Aggregation of commercial health plan claims data and Medicare Fee-for-Service (FFS) claims data as a BQI pilot;
-
Capture and aggregation of electronic clinical data in a quality data warehouse with the Massachusetts eHealth Collaborative; and
-
Aggregation of health plan HEDIS data.
MHQP aggregates HEDIS data already calculated by health plans (numerators and denominators for individual physicians) across five of our member health plans: Blue Cross Blue Shield of Massachusetts, Fallon Community Health Plan, Harvard Pilgrim Health Care, Health New England, and Tufts Health Plan. Since 2004, MHQP has been issuing reports to primary care physicians in Massachusetts about how well
they perform on clinical HEDIS measures focused on the management of patients with chronic disease and the management of preventive care services. MHQP’s Statewide Comparative Clinical Quality Reports address physicians’ performance at multiple levels: individual physician, practice site, medical group, and network. For example, MHQP issues reports that compare (1) how the nine physician networks in Massachusetts perform compared to each other; (2) how the different medical groups within those networks perform; (3) how practice sites within the medical groups per-
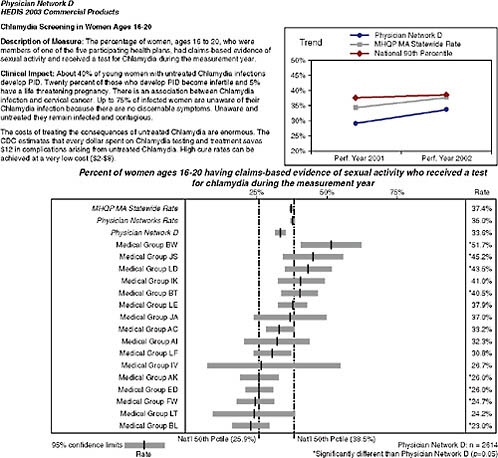
FIGURE 2-3 Snapshot of Massachusetts Health Quality Partners Statewide Comparative Clinical Quality Reports.
SOURCE: MHQP (2008). Reprinted with the permission of the Massachusetts Health Quality Partners.
form; and (4) how individual physicians within the practice site perform (Figure 2-3). This requires us to accurately map Massachusetts physicians to the sites and groups with whom they practice. To do this, MHQP has developed a process to gather and validate physician grouping information in collaboration with the physician offices.
MHQP first released physician quality data publicly on its website in 2005 and has publicly reported this information every year since, comparing the performance of 150 medical groups across MHQP. MHQP has a policy to issue private reports to physicians prior to the public release of the information.
On the MHQP website,2 consumers can compare how well medical groups in Massachusetts provide preventive care services and manage chronic diseases in MHQP’s Quality Insights: Clinical Quality in Primary Care report (Figure 2-4). The MHQP website also includes information about the conditions being measured, including information about what consumers can do to help manage their medical conditions and what they can expect their physicians to do to manage their care.
Aggregation of Commercial Health Plan Claims Data and Medicare FFS Claims
In 2006 MHQP was one of six organizations across the country to be designated as a Better Quality Information to Improve Care for Medicare Beneficiaries pilot. BQI is a CMS initiative to combine public and private information to measure and report on physician performance. One of the BQI project’s major goals is to provide recommendations on the most effective methods to aggregate Medicare claims data with data from other payers in order to produce the most accurate, comprehensive measures of the quality of services being provided by physicians to Medicare beneficiaries. MHQP contracts with ViPS as a data aggregator to support MHQP’s analysis of the claims data. The reports from MHQP’s BQI project represent both primary care physicians and select specialists who participate in the Medicare FFS program and in four commercial health plan health maintenance organizations (HMOs) and preferred provider organizations (PPOs).
The key challenges in the BQI pilot have been as follows:
-
Linking physician data across plans/payers: Requires the creation of a master physician directory because the National Provider Identifier is not broadly available.
-
Attributing patient’s care to appropriate physician(s) for non-managed–care patients: Requires the development of methodology
|
2 |
See http://www.mhqp.org. |
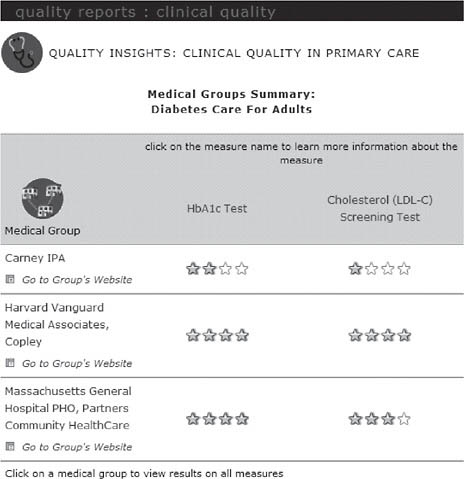
FIGURE 2-4 Quality insights: Clinical quality in primary care report.
SOURCE: MHQP (2008). Reprinted with the permission of the Massachusetts Health Quality Partners.
-
to assign patient to physicians and to test whether these attribution methods reflect actual doctor/patient relationships.
-
Validating data while maintaining privacy of PHI: Encrypted patient identifiers make it difficult to provide patient-specific feedback to physicians. This makes validation of the data very challenging.
-
Reporting reliably at a level other than individual physician: Requires the mapping of physicians to the appropriate medical group. Tax ID numbers do not necessarily mirror practice affiliations.
Attributing Patient’s Care to Appropriate Physician
Prior to working with FFS Medicare claims and commercial PPO claims, MHQP did not have to attribute patient care to a physician because MHQP used commercial managed-care data where patients are assigned to primary care physicians. For the BQI pilot, MHQP developed rules to attribute care of Medicare beneficiaries and the PPO population to a relevant physician based on the claims data. The BQI pilots developed and tested different attribution methodologies. There is an inherent trade-off between attributing as many patients as possible to physicians (e.g., there is a “one-touch rule” where a patient is attributed to all providers who have had any “Evaluation and Management” [E&M] visits with that patient) versus trying to assign care in a way that more accurately reflects actual accountabilities given the true relationships between clinicians and their patients. For example, is it reasonable to attribute a patient to a physician who saw a Medicare patient for a single visit and to hold the physician responsible for making sure that patient has had a mammogram, hemoglobin test, and so forth? It is important that we develop attribution methodology that allows for meaningful measurement of physicians.
The six BQI pilots are all in different markets and use different measurement models and data sources. Each BQI pilot health delivery market brings many unique characteristics. For example, the Indiana Health Information Exchange has access to a rich clinical data source because of the work the Regenstrief Institute has accomplished over the years, and the Wisconsin Collaborative for Health Care Quality does not use health plan claims data, but rather uses source data provided from the large physician groups. These models all provide a rich opportunity to learn a great deal about data aggregation.
Capture and Aggregation of Electronic Clinical Data
In 2006, MHQP was selected to work with the Massachusetts eHealth Collaborative (MAeHC) to build a Quality Data Warehouse (QDW), and to create quality metrics from electronic clinical data. The MAeHC is a multistakeholder organization funded by Blue Cross Blue Shield of Massachusetts with $50 million to encourage implementation of EHRs and HIE in Massachusetts. Three Massachusetts communities were selected by MAeHC to receive EHR systems in physician offices and a community-wide HIE. Working with MAeHC and our technology partner, Computer Sciences Corporation, MHQP is creating a QDW that holds data from the HIEs in the three pilot communities. The QDW is designed to collect clinical-quality data and report on quality measures for use by physicians, researchers, and others in the MAeHC communities. The QDW extracts
predefined, deidentified clinical data from the HIEs in the three pilot communities. MHQP is working to create quality metrics from these clinical data, then will provide performance feedback reports to the pilot communities at the physician, practice, and community levels.
Capturing clinical data and deriving quality measures from the EHRs and HIEs has been quite challenging. The technical specifications for measure creation have been based historically on data elements available in claims data, not electronic clinical data. Another challenge is that clinical information needs to be entered into the EHR in a standard format to easily capture the data for creating quality measures. There is an inherent trade-off between offering physicians flexibility in how they enter their information into the EHR (sometimes necessary to ease physicians into participation) versus the ability to capture useful information for quality metrics.
Lack of standards regarding data definitions and terms among EHR vendors, hospitals, labs, and radiology centers requires mapping data elements across sites, and can slow down the process of creating quality measures. A variety of codes are being used by different sites (e.g., NDC versus Multum codes), requiring time-intensive individualized crosswalks to be developed to bridge these coding systems. Finally, data from physician office EHRs only capture activity in the physician office. Many measures define their eligible population by an event that takes place in a hospital (e.g., a heart attack or heart surgery for patients with coronary artery disease [CAD]). To look at care across the continuum, a mechanism is needed to capture clinical information about patients from other locations of care, including hospitals, labs, and other entities.
Challenges with creating quality measures from electronic clinical information include:
-
Difficult trade-off between offering physicians flexibility to enter data and standardization of data for easier data capture;
-
Lack of standards in data definitions and terms;
-
Lack of standardization across vendors;
-
Measures not limited to physician office activity—for example, CAD measure requires hospital documentation (e.g., date) of an acute myocardial infarction (AMI); and
-
Required elements (e.g., ICD-9, E&M, and NDC codes) to establish measure numerators and denominators are not always available in EHR data.
Impact of MHQP’s Public Reporting
To date, MHQP’s public reporting has had a greater impact on physician behavior than on consumer behavior. Knowing that your physician organization is going to be listed on a public website or appear on the front page of the Boston Globe in comparison with your competitors is a strong motivator for improving performance. MHQP has been told by physician organizations that our public reports have influenced physician organization investments in infrastructure to support quality. They have influenced decisions to accelerate implementation of electronic health record systems, and decisions about how standardized individual EHR systems should be within a physician organization given budget considerations. Physician organizations are also using MHQP’s private reports within their organizations to focus improvement efforts and to reward individual physician performance. This means MHQP’s reports have already become integral to the operations in some physician offices; they have become a tool for improvement and their impact will continue to grow as more physician organizations discover their utility and value.
Of the measures where MHQP has reported comparative physician performance publicly and privately, primary care physicians in Massachusetts have improved on eight of nine measures over the past 4 years. Although MHQP cannot claim that its reporting is responsible for the improvement, we do know that MHQP’s reporting provides the yardstick that allows the tracking of physician performance over time.
On the consumer side, we know consumers go to MHQP’s website, especially to find a new doctor, but we do not have a good sense about the overall impact the website is having on consumer behavior. From focus groups with consumers, we know they highly value MHQP’s information about patient experience because it gives them information that resonates with them. Consumers would prefer all information about physician performance at the individual physician level.
MHQP has anecdotal information that indicates consumers do not always value the clinical information available. For example, in a recent focus group with consumers, one woman’s reaction to MHQP’s report about how well physicians provided breast cancer screening to women was to ask why she should care about results for a medical group that showed 95 percentage of the women who should be screened for breast cancer receive a mammogram. She noted that she gets her mammogram and wasn’t concerned if other women get theirs. This consumer wanted data that would tell her that a physician would be more likely to cure breast cancer in a patient-centered and respectful way. MHQP wants to engage consumers, but clearly new types of measures and data sources need to be developed
to provide more meaningful information for consumers. We also believe a “quality framework” should be developed so consumers can increase their understanding and evaluation of quality measurement data.
Opportunities to Create More Meaningful Quality Measures
The best way for MHQP to create more meaningful quality measures is to be able to capture clinical outcome data from EHRs and other electronic data sources. Experts in the HIT world are beginning to pay attention to the need to capture healthcare quality information for measurement purposes, and on the national level, the health information community and the quality community are beginning to work with a broad-based set of stakeholders to define how HIT can effectively support quality improvement. Some progress has been made on this front, but we need to continue to push it forward. From MHQP’s perspective, “nirvana” would be the integration of clinical and claims data, and, ultimately, the incorporation of personal health information as well.
In Massachusetts it is exciting that MHQP, in partnership with the MAeHC, has been officially designated as the Massachusetts Chartered Value Exchange with a goal of integrating quality and HIT. This will allow better access to electronic data sources that will enable reporting of outcome measures to help everybody improve care.
DATA PRIMARILY COLLECTED FOR NEW INSIGHTS
Michael S. Lauer, M.D., F.A.C.C., F.A.H.A.
Director, Division of Prevention and Population Sciences, National Heart, Lung, and Blood Institute
Well over 100 years ago, Lord Kelvin identified numerical data as the cornerstone of successful science when he stated, “If you can not measure it, you can not improve it…. When you measure it and express it in numbers, you know something about it” (Kelvin, 1883). Modern clinical researchers and epidemiologists owe much of their success to their ability to collect, sort, and analyze increasingly vast amounts of numerical data. The Institute of Medicine’s goal of making evidence-based medicine the norm depends on the use of data as a staple for developing scientifically sound guidelines. In fact, one of the Roundtables themes is to ensure that publicly funded data are used for the public benefit.
TABLE 2-1 Examples of Available Clinical Data Used for Generating New Insights
Sources of Data
At least three major types of data are available to clinical and public health scientists (Table 2-1). Data based on clinical care come from electronic health records, clinic-based administrative datasets, and government payer datasets. Large-scale registries are generated and maintained by counties, state health authorities, professional societies, pharmaceutical and device companies, and the federal government. Clinical trials, whether publicly or privately funded, can function as rich sources of observational data, useful for exploring questions that go beyond their original hypotheses. Common features of all these types of data include an electronic format, predefined fields, and for most, large numbers that enable robust analyses.
Site-Based Electronic Health Records
The purest type of electronic clinical data is that which is obtained prospectively at the point of care and which is based on clearly defined objective quantitative variables. For example, in the early 1990s, physicians and exercise physiologists at the Cleveland Clinic assembled a computerized database within the exercise stress laboratory (Cole et al., 1999). For
all patients referred to the laboratory, providers directly entered into a computer server data on demographics, test indications, medical history, standard cardiovascular risk factors, medications, resting electrocardiogram findings, and exercise-test findings. This database was used initially to generate rapid, legible, and easily retrievable clinical reports. Clinical researchers later realized that the database could be combined with other sources of data, such as death registries or databases of other commonly obtained diagnostic tests, to study a variety of hypotheses. Published reports from these data demonstrated the prognostic value of simple measures such as functional capacity (Snader et al., 1997), chronotropic response (Lauer et al., 1999), heart rate recovery (Cole et al., 1999), and exercise-related ventricular ectopy (Frolkis et al., 2003). When researchers from the Cleveland Clinic collaborated with researchers at Kaiser Colorado, they were able to use their database to develop and validate a prognostic model for patients with suspected coronary disease and a normal resting electrocardiogram (Lauer et al., 2007).
Hospitals and insurance systems maintain administrative data for billing and quality monitoring purposes. Some investigators have employed administrative data to generate clinical insights, such as the potential value of beta-blockers for preventing perioperative deaths in high-risk patients (Lindenauer et al., 2005). Despite concern that administrative databases inherently yield biased estimates, some investigators have found that predictions based on administrative data closely approximate those based on rigorously obtained clinical data (Krumholz et al., 2006).
Registries
Large-scale registries are supported by counties, states, industry, professional societies, and the federal government. Counties have long maintained data on birth and death rates. Combining county and Census data, University of Washington researchers have shown marked inequalities of health according to demographics (Murray et al., 2006). A particularly alarming report focused on worsening life expectancy in some regions of the United States (Ezzati et al., 2008).
One of the best known state registries comes from New York, where data are routinely collected on all patients undergoing revascularization. These data have been used to produce “scorecards” specific to hospitals and providers (Topol and Califf, 1994). Patients or referring physicians can use these data to make better informed decisions. The data have also been used for observational comparative effectiveness studies of commonly available treatments. For example, Hannan and colleagues recently published analyses demonstrating probable superiority of coronary artery bypass grafting
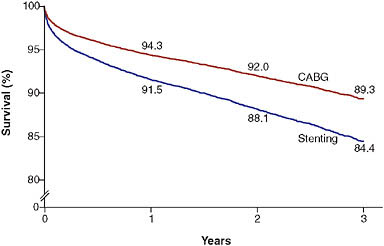
FIGURE 2-5 Three-vessel disease with disease of proximal LAD artery.
NOTE: Example of observations derived from the New York State revascularization registry. Patients who underwent coronary artery bypass grafting (CABG) had better outcomes than those who had stenting. Values are percentages at 1, 2, and 3 years; they were adjusted for the ejection fraction; the presence or absence of diabetes, congestive heart failure, chronic obstructive pulmonary disease, carotidartery disease, aortoiliac disease, shock, renal failure, femoral or popliteal disease, and stroke; age; and sex.
SOURCE: Hannan et al. (2005).
over percutaneous coronary intervention among patients with severe multi-vessel coronary artery disease (Figure 2-5) (Hannan et al., 2005, 2008).
Pharmaceutical and device companies have funded multicenter registries that collate data on common clinical problems. For example, the National Registries of Myocardial Infarction (NRMI) have recorded baseline characteristics and short-term outcomes of literally millions of patients with acute coronary syndromes admitted to hospitals. One valuable report demonstrated the strong association between rapidity of percutaneous revascularization, commonly known as “door-to-balloon time,” and mortality (Cannon et al., 2000) (Figure 2-6); these and similar observations were the basis for major national efforts to research and improve care (Nallamothu et al., 2007). In the past few years, the NRMI and similar registries have been taken over by a major specialty society, the American College of Cardiology.
The federal government has long supported population-based cohorts that were instrumental in discovering public health risks that are now common knowledge, including the dangers of smoking, diabetes, hypercholesterolemia, and hypertension (Executive summary, 2001). The best
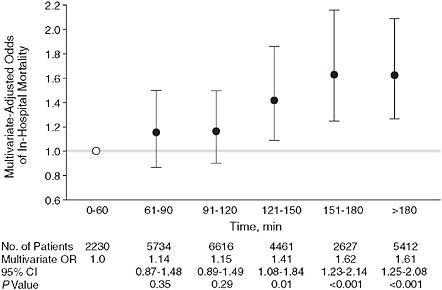
FIGURE 2-6 Door-to-balloon time.
NOTE: Example of observations derived from an industry-supported myocardial infarction registry. Patients who had a longer door-to-balloon time had a higher risk-adjusted hospital mortality. The graph depicts multivariate-adjusted relationship between door-to-balloon time and mortality (χ2 trend = 99.5; P < 0.001). Error bars indicate 95% confidence intervals (CIs); OR, odds ratio; open circle, the reference value. Door time refers to time of arrival at hospital and balloon time, time of first balloon inflation of the primary angioplasty procedure.
SOURCE: Adapted figure from Cannon et al. (2000).
known may be the Framingham Heart Study (D’Agostino et al., 2001), though a number of other cohort studies have yielded important findings on racial (Hozawa et al., 2007), socioeconomic (Diez Roux et al., 2001), genetic (McPherson et al., 2007), and subclinical (Detrano et al., 2008) aspects of common cardiovascular diseases. The Framingham Heart Study cohort is the basis for one of the most commonly accepted means of global risk assessment of patients at risk for coronary heart disease (Executive summary, 2001).
Other federal agencies support a number of registries and surveys that are commonly used by research epidemiologists. The Centers for Disease Control and Prevention (CDC), in conjunction with other federal agencies such as the National Institutes of Health (NIH), supports the National Health and Nutrition Examination Surveys (NHANES), which attempt to generate nationally representative estimates of risk and disease distributions. Combining NHANES data with federal national death registries, researchers have been able to show, for example, that women with diabetes
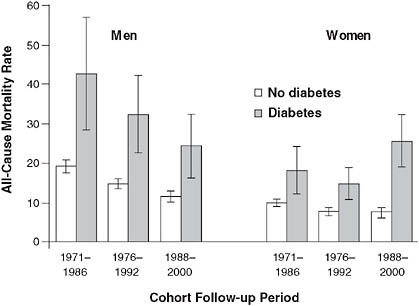
FIGURE 2-7 Mortality rate trends for men and women with diabetes.
NOTE: Example of observations derived from the CDC’s NHANES surveys. Over a 30-year period, mortality rates decreased for men with diabetes, but actually increased among women. Age-adjusted all-cause mortality rates among the U.S. population aged 35 to 74 years with and without diabetes, by cohort and sex.
SOURCE: Gregg et al. (2007). Reprinted with permission of the Annals of Internal Medicine.
have seen worsening survival over the past 30 years, while men’s outcomes have improved (Gregg et al., 2007) (Figure 2-7).
The CDC also supports the Behavioral Risk Factor Surveillance System (BRFSS), a large telephone survey that tracks health-related behaviors and self-reported risk factors. A recent report based on the BRFSS demonstrated marked geographical variability in blood pressure control and an association between this and variability in cardiovascular outcomes (Ezzati et al., 2008). Medicare supports the Medicare Provider Analysis and Review File (MEDPAR) that has been used, for example, to generate robust prediction models for outcomes of patients hospitalized for acute myocardial infarction or decompensated heart failure (Krumholz et al., 2006).
Limitations of Available Clinical and Population-Based Data
Despite the wealth of data available to researchers and policy makers, a number of major limitations must be realized. Relatively few American clinicians use computers to document care (Jha et al., 2006), and even
when they do, much of the imported data are free text that are inherently difficult to analyze. Most data are based on nonrandomized observations. With a few notable exceptions, most clinical data are not integrated across clinical practices and sites. Access to data varies, with some datasets widely available (like NHANES), whereas others are only available to personnel working at specific clinical sites or for specific sponsors.
Observational Data
Nearly all data derived from electronic health records and public or private registries are observational, that is, not based on randomized experiments. Although some have found that in general observational and randomized observations correlate well (Benson and Hartz, 2000; Concato et al., 2000), modern medical history is replete with examples of major discrepancies between observational findings and results of randomized trials (Pocock and Elbourne, 2000). Examples include hormone replacement therapy for prevention of chronic disease in postmenopausal women (Rossouw et al., 2002) and vitamin E for prevention of coronary disease events (Lee et al., 2005). A major problem with nearly all observational data is an inherent inability to correct for unmeasured confounders. Analysts have attempted to use modern statistical methods, such as propensity score or instrumental variable corrections (Stukel et al., 2007), but they have met variable levels of acceptance (D’Agostino and D’Agostino, 2007). Randomized trials have been criticized for being expensive and difficult to generalize, yet they remain the only method by which unmeasured sources of confounding and bias can be reliably considered.
Observational data still have value (Radford and Foody, 2001). In some cases, hypotheses are based on exposures that cannot be randomized based on natural or socioeconomic factors. Examples include biomarker levels, smoking, and small-particulate-matter air pollution (Miller et al., 2007). Observational analyses based on such exposures can be used to stimulate development of new treatments, but even so, randomized trials are eventually needed for evidence on which robust guidelines are based. For example, extensive epidemiological evidence has linked low-density lipoprotein (LDL) and high-density lipoprotein (HDL) levels to cardiovascular risk (Kannel, 1995). Some drugs that reduce LDL levels, such as statins, have been clearly shown to improve outcomes (Baigent et al., 2005), whereas others, such as torcetrapib (Barter et al., 2007), have not. Observational data are also useful for confirming results of randomized trials in groups of patients who were excluded from trials (Radford and Foody, 2001) and also for identifying rare safety signals (Graham et al., 2004) that even large trials are not powered to detect.
Data Integration
In the United States, most clinical data are not integrated across sites and practices. In contrast, other countries, such as the United Kingdom and Finland, have well-integrated databases that make it possible to follow patients easily regardless of where care is obtained. These integrated databases facilitated discoveries such as the high risks of angina in women (Hemingway et al., 2006) and the association of psoriasis with coronary disease events (Gelfand et al., 2006).
There are some notable American exceptions in which data have been successfully integrated. These include Medicare, the Department of Veterans Affairs, and HMO networks. Analyses of Medicare data have been used to define the potential benefits of aggressive management of patients with myocardial infarction (Stukel et al., 2007). Recently, integrated HMORNs have supported research programs focused on cancer and cardiovascular care (National cardiovascular data, 2008).
Data Access
In 1989, Claude L’Enfant, then NHLBI director, sent a memo to division directors, calling attention to a policy for widespread data release of Institute-supported, multicenter clinical trials and epidemiological studies (Figure 2-8). The Institute’s policy has been to see data as a valuable resource paid for by taxpayers, and hence a resource that should be made available to the general scientific community, allowing for appropriate research subject protections. A number of researchers have successfully taken advantage of publicly available data, demonstrating, for example, the dangers of digoxin use in women with heart failure (Rathore et al., 2002), the epidemiology of valvular heart disease (Nkomo et al., 2006), and the public health threats posed by obesity in adults (Peeters et al., 2003).
The genomic revolution has led to a new level of data sharing, whereby highly detailed genotypic and phenotypic data are made available to qualified researchers. In October 2007, the NHLBI launched the Framingham SNP (single nucleotide polymorphism) Health Association Resource. Genotype data on more than 550,000 SNPs have been combined with data on hundreds of phenotypes among nearly 10,000 Framingham Heart Study subjects and stored in the NIH database on Genotype and Phenotype (dbGaP). Sharing genetic data on such a high level has been termed by some as a “bold experiment,” in that it allows for a wealth of discovery, but it also raises questions about what levels of informed consent and privacy and confidentiality protection are appropriate (Caulfield et al., 2008; Psaty et al., 2007). For nongenetic data registries and cohort studies, standard models have been applied to require or waive written informed consent

FIGURE 2-8 Memorandum dated December 8, 1989, from Claude Lenfant, Director of the National Heart, Lung, and Blood Institute (NHLBI), to division directors regarding public release of data generated by large institute-supported studies.
requirements according to the Common Rule, as outlined in 45 C.F.R. 46 (NIH public access, 2008). Plans to share widely complex genetic data have raised new concerns about the level of consent needed, as reflected in the NIH’s recently released Genome-Wide Association Studies policy (National Heart, 2007). In one program, the Personal Genome Project, an “open consent” model is being proposed by which adults volunteer to give DNA samples along with health information with the understanding that their data will be widely available and that there are no guarantees of anonymity, confidentiality, and privacy (Lunshof et al., 2008).
Many clinical data are produced as part of industry-supported clinical trials. These data are typically not made available to the public or even the general scientific community. Failure to share data exists on several levels.
Results of many trials are never published, leading to a biased impression about the efficacy or effectiveness of some treatments, such as antidepressants (Turner et al., 2008). In other cases, trial data that are not published can be obtained in incomplete format by researchers with affiliations with the Food and Drug Administration (FDA); these have been used, for example, to generate suspicions of the safety of commonly used drugs, such as rofecoxib (Vioxx) (Mukherjee et al., 2001) and rosiglatizone (Avandia) (Nissen and Wolski, 2007). On a more fundamental level, data may be published in aggregate form, yet access to raw data may be limited or delayed to academic researchers, as recently occurred in a multicenter trial of the cholesterol-lowering drug ezetimibe (Berenson, 2007).
Some sectors have taken steps to maximize access to clinical trial data, at least for academic researchers. A coalition of journal editors have required authors to attest to having access to all data (Davidoff et al., 2001), to having had clinical trials registered on a public forum (e.g., www.clinicaltrials.gov) (Laine et al., 2007), and, for some journals, to having obtained independent statistical analyses (DeAngelis and Fontanarosa, 2008). Recent federal legislation requires publicly funded research publications to be posted on a government website (National cardiovascular data, 2007) and requires results for many clinical trials, whether publicly funded or publicly noted, to be made publicly available.
Summary and Closing Thoughts
For many decades, researchers and clinicians have taken advantage of many sources of rich clinical and population-based data to generate new insights, stimulate major research programs, and develop robust clinical guidelines. The story of the cholesterol hypothesis is an excellent example of the power and limitations of clinical and population-based data. Epidemiological cohort studies established and described the strong link between blood cholesterol levels and cardiovascular risk (Kannel, 1995). These observational findings led to a reasonable, but unproven (Moore, 1989), hypothesis that lowering cholesterol could improve health. Drugs were developed that could reduce cholesterol levels, with some (Baigent et al., 2005), but not all (Barter et al., 2007), eventually shown in randomized trials to yield substantial improvements in patient outcomes. Postmarketing surveillance studies demonstrated the safety of statins; however, one exception, cerivastatin, was found to have an unacceptably high risk of a rare side effect, rhabdomyolysis, leading to withdrawal of that drug from the market (Graham et al., 2004). The cholesterol story illustrates the value of observational data for generating hypotheses and detecting safety signals, while also illustrating the critical role of randomized trials to generate robust evidence in support of specific therapies.
If the Institute of Medicine’s evidence-based medicine goal is to be realized, clinical data must be recognized as a staple that should be widely available and integrated. Examples from abroad and from some U.S. health systems, such as HMORN and the VA, demonstrate that it is possible to incorporate rigorous and prospective data collection into routine clinical care. Still, most clinical data are not collected at the point of care in an easily retrievable manner and most are organized in isolated silos that are difficult for many analysts to access.
Even if a “data paradise” could be achieved with universally obtained and available clinical data, there is concern that policy leaders may place too much reliability on these largely observational datasets for generating evidence-based recommendations. Observational analyses of treatments must be recognized as inherently biased because of failure to take into account selection biases and unmeasured confounders. Modern statistical techniques and collection of more data elements may reduce these biases, but even with large numbers of observations, biases are still biases. I do accept the notion that a national priority for growing, sharing, and analyzing vast quantities of observational, clinical, and population data is an essential element toward reaching a vision of routinely practiced evidence-based medicine. This will only be true, though, if accompanied by a healthy dose of skepticism and recognition that, just as in Lord Kelvin’s day, well-designed experiments are also critical for building a scientific evidence base.
HEALTH PRODUCT MARKETING DATA
William D. Marder, Ph.D.
Senior Vice President and General Manager, Thomson Healthcare
Three major types of data are used by public and private entities to market healthcare products and services: health survey data, information about general consumption patterns, and administrative data generated by the healthcare delivery system. Private health survey data are patterned after government-sponsored surveys such as the National Health Interview Survey (NHIS) or the Hospital Consumer Assessment of Healthcare Providers and Systems Survey (HCAHPS). Analyses drawn from general consumption patterns and market segmentation data keyed to census tract data can guide modeling behavior and messaging strategies. Much of the information about patient/consumer attitudes comes from this source. The administrative data include retail store sales data, patient eligibility and medical claims data, and a growing availability of short- and long-term disability claims data as well as health risk appraisal data. This paper describes
use of these data assets by providers and pharmaceutical companies and the business models that support collection of the data. The administrative data assets are often used in retrospective database studies to examine the cost effectiveness of interventions in the general population (outside the context of clinical trials, where both providers and patients are strongly encouraged to be on their best behavior). The interaction of private data assets and academic research will be discussed, including how access to data can be provided for replication of results.
The fundamentals of marketing are often described as a mix of “four Ps”: Product, Price, Place/Positioning, and Promotion. In health care, many entities conduct marketing efforts that blend these factors to strategic advantage. Healthcare entities that engage in marketing include physicians, hospitals, pharmaceutical companies, device suppliers, and government agencies. The range of marketing activities in which these entities engage can be vast and varied. Examples might include planning for a new ambulatory surgery center, gaining acceptance for a new antidepressant, introducing a generic version of an established drug, raising mammography rates, or increasing enrollment in Medicaid or the State Children’s Health Insurance Program.
Historically, health surveys have relied on government-collected data, long considered the reliable gold standard. Such data are not particularly helpful as marketing data, however, in that they tend to be fairly old and not easily linkable to general marketing tools. Those circumstances create an opportunity for the private sector to develop marketing data that are more current and linkable to marketing tools.
The marketing of health products is a thriving industry. Marketing to the public draws on lessons learned and information gained in the work of specific, targeted marketing such as the examples just cited, and also relies on information from additional sources, such as census data on population characteristics in small areas and customer buying habits. Increasingly, data compiled in support of the marketing of health products are being linked to health behaviors.
Within the private sector, many such marketing surveys exist. One example is the Thomson PULSE Survey, a questionnaire modeled on the NHIS. Based on a random telephone survey of 100,000 households per year, with replicates of 10,000 per month, 10 months per year, the survey offers results that are available 3 weeks after the close of each month in the field, identifiable by the census tract of the respondent. The survey is linkable to other census tract data, including socioeconomic characteristics of a particular census area and lifestyle modeling done by general marketing firms. In addition to this type of survey, there are provider-funded customer satisfaction surveys modeled on or incorporating HCAHPS. The Thomson PULSE Survey models healthcare use as a function of household and neigh-
borhood characteristics. Such models can then be integrated into software products that can help drive marketing and planning decisions of entities such as hospitals, government agencies, contract research organizations, and pharmaceutical companies.
As an example, assume that we want to find the best groups for clinical trial participation in “anytown,” “anystate,” ranked by clinical trial participation. The popular PRIZM (Potential Rating Index for ZIP Markets) system provides a standardized set of characteristics, known as clusters, for each U.S. ZIP Code. PRIZM is the nation’s leading marketing segmentation system. (See www.claritas.com for more details, which are on a PRIZM poster available from Medstat.) Medstat licenses the system from Claritas and puts its unique health information into the system, especially disease prevalence information. Claritas assigns each block group to a PRIZM lifestyle segmentation cluster based on numerous demographic and socioeconomic variables, including age, income, population density, education, occupation, homeownership, and household composition. Media data come from Simmons Media Research Bureau, which conducted a separate survey of 50,000 households by PRIZM cluster. Answers to the PULSE Survey also help create the clusters. The objective of the clusters is to separate the population into groups that have strong differences in purchasing and health behaviors.
Using such an approach, we can, for example, pinpoint a target demographic group of blue-collar or farm couples, aged 35–54, who are high school graduates and owners of single-family dwelling units (our sample turns out to include a notable number of mobile homes). In terms of income, our group ranks at 45 out of 66 clusters. Mining the available data, we can determine that our group might be more likely than others to do crafts and needle work, go freshwater fishing, read Flower & Garden magazine, listen to country music, and own a Chevrolet Silverado. We can also differentiate that this given group has 7,069 patients who participated or seriously considered participating in a clinical trial, in contrast to a similar but slightly different group that has just 75 patients who were inclined to take part in a clinical trial.
Marketing data analyses draw on a rich abundance of administrative data that offer both advantages and shortfalls. Retail store sales data, for example, can include information on pharmaceutical use; available quickly, such data can sometimes identify the prescribing physician. There are billing service or product-switch data. Although these data are quickly accessible, they can sometimes be incomplete; such data can provide information on medical and pharmaceutical claims. There are health plan data, which have information on eligibility and claims for covered services, but may miss carved-out services. Finally, there are employer-based data, which can include eligibility and claims for covered services, sometimes include health
risk assessment data, and offer information on short- and long-term disability and worker’s compensation claims.
Claims data offer significant marketing uses. Such data can be applied tactically—retail and product-switch data can be used, for example, to identify the effect of marketing campaigns and for measuring sales force effectiveness. At a perhaps more strategic level, claims data can offer insights for evaluating unmet medical needs, understanding the cost of acquiring a drug in a broader context, pricing new products, gaining favorable formulary position, and convincing prescribers about the value of a drug.
The development of healthcare marketing data is also informed by the FDA’s encouragement of peer review. Strategic marketing goals can be accomplished by publishing material that meets peer-review standards. A substantial group of researchers address this need. The International Society for Pharmacoeconomics and Outcomes Research (www.ispor.org), for example, promotes the science of pharmacoeconomics (health economics) and outcomes research (the scientific discipline that evaluates the effect of healthcare interventions on patient well-being, including clinical outcomes, economic outcomes, and patient-reported outcomes) and facilitates the translation of this research into useful information for healthcare decision makers to ensure that society allocates scarce healthcare resources wisely, fairly, and efficiently. A combination of private/public, not-for-profit/for-profit entities contribute to this literature. Overall, the process means that for-profit entities that contribute data and research must develop strategies that are consistent with academic standards.
Given that the collection of such data can be expensive, there must be a revenue stream to offset data collection costs. In the case of the Thomson PULSE Survey, for example, the revenue stream comes from the use of the data in marketing and planning tools sold to providers and suppliers. Revenue also covers licensing of general marketing information. As for the funding of administrative data, the costs of retail and product-switch data are largely covered by pharma. Health plan and employer data are largely covered by the operations of payer organizations, with additional support from consultants serving many organizations, including pharma, government, benefits consultants, and reinsurance companies.
Licensing data in a for-profit setting has considerable benefits. Licensing helps customers achieve their goals by making data easy to use and to be sorted based on their interests in particular aspects of marketing’s “four Ps.” For license holders, the process of licensing offers the capability to market assets developed at considerable expense, and to recoup some of the costs of developing the data. This area raises considerations about how to best manage the intersection and interaction of private data assets and academic research. Although there is an inherent challenge in balancing the costs and benefits of making data available to students and researchers,
it is important that channels be maintained to make data available at no charge to academic audiences and to ensure access to data for replication of results.
In terms of applications of clinical data for marketing, not many such data are now available. The best of what are currently available are lab-result data linked to claims. Health plans are in the best position to acquire data from national labs. The comprehensiveness of such data can be checked relative to claims. At the same time, however, population-based comprehensive clinical data are not “right around the corner,” as sometimes suggested, but are likely to be realized only at some point in the future. Registry data are not generally available for marketing purposes.
In sum, marketing data can be seen as a synergy of inputs and interests from a variety of entities. The public sector provides raw material and models of data collection, at minimal cost. The private sector builds databases with clear commercial value that fill needs suggested by, but not covered by, public sources. As electronic medical record systems become more common, one can envision a blend of databases that draws on both public and private data sources—the mix will depend on government willingness to fund aggregation.
REFERENCES
Baigent, C., A. Keech, P. M. Kearney, L. Blackwell, G. Buck, C. Pollicino, A. Kirby, T. Sourjina, R. Peto, R. Collins, and R. Simes. 2005. Efficacy and safety of cholesterol-lowering treatment: Prospective meta-analysis of data from 90,056 participants in 14 randomized trials of statins. Lancet 366(9493):1267–1278.
Barter, P. J., M. Caulfield, M. Eriksson, S. M. Grundy, J. J. Kastelein, M. Komajda, J. Lopez-Sendon, L. Mosca, J. C. Tardif, D. D. Waters, C. L. Shear, J. H. Revkin, K. A. Buhr, M. R. Fisher, A. R. Tall, and B. Brewer. 2007. Effects of torcetrapib in patients at high risk for coronary events. New England Journal of Medicine 357(21):2109–2122.
Benson, K., and A. J. Hartz. 2000. A comparison of observational studies and randomized, controlled trials. New England Journal of Medicine 342(25):1878–1886.
Berenson, A. 2007. Cardiologists question delay of data on two drugs. New York Times. 2007. http://www.nytimes.com/2007/11/21/business/21drug.html# (accessed August 10, 2008).
Cannon, C. P., C. M. Gibson, C. T. Lambrew, D. A. Shoultz, D. Levy, W. J. French, J. M. Gore, W. D. Weaver, W. J. Rogers, and A. J. Tiefenbrunn. 2000. Relationship of symptom-onset-to-balloon time and door-to-balloon time with mortality in patients undergoing angioplasty for acute myocardial infarction. Journal of the American Medical Association 283(22):2941–2947.
Caulfield, T., A. L. McGuire, M. Cho, J. A. Buchanan, M. M. Burgess, U. Danilczyk, C. M. Diaz, K. Fryer-Edwards, S. K. Green, M. A. Hodosh, E. T. Juengst, J. Kaye, L. Kedes, B. M. Knoppers, T. Lemmens, E. M. Meslin, J. Murphy, R. L. Nussbaum, M. Otlowski, D. Pullman, P. N. Ray, J. Sugarman, and M. Timmons. 2008. Research ethics recommendations for whole-genome research: Consensus statement. PLoS Biology 6(3):e73.
Chaudhry, B., J. Wang, M. Maglrare, W. Mojica, E. Roth, S. C. Marten, and P. G. Shekelle. 2006. Systematic Review: Impact of Health Information Technology on Quality, Efficiency, and Costs of Medical Care. Annals of Internal Medicine 144(10):742–572.
Cole, C. R., E. H. Blackstone, F. J. Pashkow, C. E. Snader, and M. S. Lauer. 1999. Heart-rate recovery immediately after exercise as a predictor of mortality. New England Journal of Medicine 341(18):1351–1357.
Concato, J., N. Shah, and R. I. Horwitz. 2000. Randomized, controlled trials, observational studies, and the hierarchy of research designs. New England Journal of Medicine 342(25):1887–1892.
D’Agostino, R. B., Jr., and R. B. D’Agostino, Sr. 2007. Estimating treatment effects using observational data. Journal of the American Medical Association 297(3):314–316.
D’Agostino, R. B., Sr., S. Grundy, L. M. Sullivan, and P. Wilson. 2001. Validation of the Framingham coronary heart disease prediction scores: Results of a multiple ethnic groups investigation. Journal of the American Medical Association 286(2):180–187.
Davidoff, F., C. D. DeAngelis, J. M. Drazen, M. G. Nicholls, J. Hoey, L. Hojgaard, R. Horton, S. Kotzin, M. Nylenna, A. J. Overbeke, H. C. Sox, M. B. Van Der Weyden, and M. S. Wilkes. 2001. Sponsorship, authorship, and accountability. New England Journal of Medicine 345(11):825–826; discussion 826–827.
DeAngelis, C. D., and P. B. Fontanarosa. 2008. Impugning the integrity of medical science: The adverse effects of industry influence. Journal of the American Medical Association 299(15):1833–1835.
Detrano, R., A. D. Guerci, J. J. Carr, D. E. Bild, G. Burke, A. R. Folsom, K. Liu, S. Shea, M. Szklo, D. A. Bluemke, D. H. O’Leary, R. Tracy, K. Watson, N. D. Wong, and R. A. Kronmal. 2008. Coronary calcium as a predictor of coronary events in four racial or ethnic groups. New England Journal of Medicine 358(13):1336–1345.
Diez Roux, A. V., S. S. Merkin, D. Arnett, L. Chambless, M. Massing, F. J. Nieto, P. Sorlie, M. Szklo, H. A. Tyroler, and R. L. Watson. 2001. Neighborhood of residence and incidence of coronary heart disease. New England Journal of Medicine 345(2):99–106.
Executive summary of the third report of the National Cholesterol Education Program (NCEP) expert panel on detection, evaluation, and treatment of high blood cholesterol in adults (adult treatment panel III). 2001. Journal of the American Medical Association 285(19):2486–2497.
Ezzati, M., A. B. Friedman, S. C. Kulkarni, and C. J. Murray. 2008. The reversal of fortunes: Trends in county mortality and cross-county mortality disparities in the United States. PLoS Medicine 5(4):e66.
Frolkis, J. P., C. E. Pothier, E. H. Blackstone, and M. S. Lauer. 2003. Frequent ventricular ectopy after exercise as a predictor of death. New England Journal of Medicine 348(9):781–790.
Gelfand, J. M., A. L. Neimann, D. B. Shin, X. Wang, D. J. Margolis, and A. B. Troxel. 2006. Risk of myocardial infarction in patients with psoriasis. Journal of the American Medical Association 296(14):1735–1741.
Graham, D. J., J. A. Staffa, D. Shatin, S. E. Andrade, S. D. Schech, L. La Grenade, J. H. Gurwitz, K. A. Chan, M. J. Goodman, and R. Platt. 2004. Incidence of hospitalized rhabdomyolysis in patients treated with lipid-lowering drugs. Journal of the American Medical Association 292(21):2585–2590.
Gregg, E. W., Q. Gu, Y. J. Cheng, K. M. Narayan, and C. C. Cowie. 2007. Mortality trends in men and women with diabetes, 1971 to 2000. Annals of Internal Medicine 147(3):149–155.
Hannan, E. L., M. J. Racz, G. Walford, R. H. Jones, T. J. Ryan, E. Bennett, A. T. Culliford, O. W. Isom, J. P. Gold, and E. A. Rose. 2005. Long-term outcomes of coronary-artery bypass grafting versus stent implantation. New England Journal of Medicine 352(21):2174–2183.
Hannan, E. L., C. Wu, G. Walford, A. T. Culliford, J. P. Gold, C. R. Smith, R. S. Higgins, R. E. Carlson, and R. H. Jones. 2008. Drug-eluting stents vs. coronary-artery bypass grafting in multivessel coronary disease. New England Journal of Medicine 358(4):331–341.
Hemingway, H., A. McCallum, M. Shipley, K. Manderbacka, P. Martikainen, and I. Keskimaki. 2006. Incidence and prognostic implications of stable angina pectoris among women and men. Journal of the American Medical Association 295(12):1404–1411.
Hozawa, A., A. R. Folsom, A. R. Sharrett, and L. E. Chambless. 2007. Absolute and attributable risks of cardiovascular disease incidence in relation to optimal and borderline risk factors: Comparison of African American with white subjects—atherosclerosis risk in communities study. Archives of Internal Medicine 167(6):573–579.
IOM (Institute of Medicine). 2001. Crossing the quality chasm. Washington, DC: National Academy Press.
IOM. 2009. Beyond the HIPAA privacy rule: Enhancing privacy, improving health through research. Washington, DC: The National Academies Press.
Jha, A. K., T. G. Ferris, K. Donelan, C. DesRoches, A. Shields, S. Rosenbaum, and D. Blumenthal. 2006. How common are electronic health records in the United States? A summary of the evidence. Health Affairs (Millwood) 25(6):w496–w507.
Kannel, W. B. 1995. Clinical misconceptions dispelled by epidemiological research. Circulation 92(11):3350–3360.
Kelvin, W. T. 1883. Electrical units of measurement. Physics Letters A 1.
Krumholz, H. M., Y. Wang, J. A. Mattera, Y. Wang, L. F. Han, M. J. Ingber, S. Roman, and S. L. Normand. 2006. An administrative claims model suitable for profiling hospital performance based on 30-day mortality rates among patients with an acute myocardial infarction. Circulation 113(13):1683–1692.
Laine, C., R. Horton, C. D. DeAngelis, J. M. Drazen, F. A. Frizelle, F. Godlee, C. Haug, P. C. Hebert, S. Kotzin, A. Marusic, P. Sahni, T. V. Schroeder, H. C. Sox, M. B. Van der Weyden, and F. W. Verheugt. 2007. Clinical trial registration—looking back and moving ahead. New England Journal of Medicine 356(26):2734–2736.
Lauer, M. S., G. S. Francis, P. M. Okin, F. J. Pashkow, C. E. Snader, and T. H. Marwick. 1999. Impaired chronotropic response to exercise stress testing as a predictor of mortality. Journal of the American Medical Association 281(6):524–529.
Lauer, M. S., C. E. Pothier, D. J. Magid, S. S. Smith, and M. W. Kattan. 2007. An externally validated model for predicting long-term survival after exercise treadmill testing in patients with suspected coronary artery disease and a normal electrocardiogram. Annals of Internal Medicine 147(12):821–828.
Lee, I. M., N. R. Cook, J. M. Gaziano, D. Gordon, P. M. Ridker, J. E. Manson, C. H. Hennekens, and J. E. Buring. 2005. Vitamin E in the primary prevention of cardiovascular disease and cancer: The women’s health study: A randomized controlled trial. Journal of the American Medical Association 294(1):56–65.
Lindenauer, P. K., P. Pekow, K. Wang, D. K. Mamidi, B. Gutierrez, and E. M. Benjamin. 2005. Perioperative beta-blocker therapy and mortality after major noncardiac surgery. New England Journal of Medicine 353(4):349–361.
Lunshof, J. E., R. Chadwick, D. B. Vorhaus, and G. M. Church. 2008. From genetic privacy to open consent. Nature Reviews Genetics 9(5):406–411.
Madden, R., C. Sykes, and T. Ustun. 2007. World Health Organization family of international classifications: Definition, scope and purpose. http://www.who.int/classifications/en/FamilyDocument2007.pdf (accessed September 23, 2008).
McPherson, R., A. Pertsemlidis, N. Kavaslar, A. Stewart, R. Roberts, D. R. Cox, D. A. Hinds, L. A. Pennacchio, A. Tybjaerg-Hansen, A. R. Folsom, E. Boerwinkle, H. H. Hobbs, and J. C. Cohen. 2007. A common allele on chromosome 9 associated with coronary heart disease. Science 316(5830):1488–1491.
Miller, K. A., D. S. Siscovick, L. Sheppard, K. Shepherd, J. H. Sullivan, G. L. Anderson, and J. D. Kaufman. 2007. Long-term exposure to air pollution and incidence of cardiovascular events in women. New England Journal of Medicine 356(5):447–458.
Moore, T. J. 1989. The cholesterol myth. Atlantic Monthly 264:37.
Mukherjee, D., S. E. Nissen, and E. J. Topol. 2001. Risk of cardiovascular events associated with selective COX-2 inhibitors. Journal of the American Medical Association 286(8):954–959.
Murray, C. J., S. C. Kulkarni, C. Michaud, N. Tomijima, M. T. Bulzacchelli, T. J. Iandiorio, and M. Ezzati. 2006. Eight Americas: Investigating mortality disparities across races, counties, and race–counties in the United States. PLoS Medicine 3(9):e260.
Nallamothu, B. K., E. H. Bradley, and H. M. Krumholz. 2007. Time to treatment in primary percutaneous coronary intervention. New England Journal of Medicine 357(16):1631–1638.
National cardiovascular data registry home page. (2008). http://www.accncdr.com/WebNCDR/Common/ (accessed April 23, 2008).
National Heart, Lung, and Blood Institute creates national network to study cardiovascular disease. 2007. http://www.eurekalert.org/pub_releases/2007-11/kpdo-nhl112807.php (accessed April 23, 2008).
NCVHS (National Committee on Vital and Health Statistics). 2001. Information for health: A strategy for building the national health information infrastructure. http://www.ncvhs.hhs.gov/nhiilayo.pdf (accessed August 20, 2008).
NCVHS. 2002. Shaping a health statistics vision for the 21st century. http://www.ncvhs.hhs.gov/21st%20final%20report.pdf (accessed August 20, 2008).
NCVHS. 2007. Enhanced protections for uses of health data: A stewardship framework for “secondary uses” of electronically collected and transmitted health data. http://www.ncvhs.hhs.gov/071221lt.pdf (accessed August 20, 2008).
NIH public access policy details. 2008. http://publicaccess.nih.gov/policy.htm (accessed April 23, 2008).
Nissen, S. E., and K. Wolski. 2007. Effect of rosiglitazone on the risk of myocardial infarction and death from cardiovascular causes. New England Journal of Medicine 356(24):2457–2471.
Nkomo, V. T., J. M. Gardin, T. N. Skelton, J. S. Gottdiener, C. G. Scott, and M. Enriquez-Sarano. 2006. Burden of valvular heart diseases: A population-based study. Lancet 368(9540):1005–1011.
Peeters, A., J. J. Barendregt, F. Willekens, J. P. Mackenbach, A. Al Mamun, and L. Bonneux. 2003. Obesity in adulthood and its consequences for life expectancy: A life-table analysis. Annals of Internal Medicine 138(1):24–32.
Pocock, S. J., and D. R. Elbourne. 2000. Randomized trials or observational tribulations? England Journal of Medicine 342(25):1907–1909.
Psaty, B. M., D. Arnett, and G. Burke. 2007. A new era of cardiovascular disease epidemiology. Journal of the American Medical Association 298(17):2060–2062.
Radford, M. J., and J. M. Foody. 2001. How do observational studies expand the evidence base for therapy? Journal of the American Medical Association 286(10):1228–1230.
Rathore, S. S., Y. Wang, and H. M. Krumholz. 2002. Sex-based differences in the effect of digoxin for the treatment of heart failure. New England Journal of Medicine 347(18):1403–1411.
Rossouw, J. E., G. L. Anderson, R. L. Prentice, A. Z. LaCroix, C. Kooperberg, M. L. Stefanick, R. D. Jackson, S. A. Beresford, B. V. Howard, K. C. Johnson, J. M. Kotchen, and J. Ockene. 2002. Risks and benefits of estrogen plus progestin in healthy postmenopausal women: Principal results from the women’s health initiative randomized controlled trial. Journal of the American Medical Association 288(3):321–333.
Safran, C., M. Bloomrosen, W.E. Hammond, S. Labkoff, S. Markel-Fox, P. C. Tang, D. E. Detmer, with input from the expert panel. 2007. Toward a national framework for the secondary use of health data: An american medical informatics association white paper. Journal of the American Medical Informatics Association 14(1):1-9. http://www.healthlawyers.org/Members/PracticeGroups/HIT/Toolkits/Documents/5_Health_Data_AMIA_Summary.pdf (accessed August 18, 2008).
Snader, C. E., T. H. Marwick, F. J. Pashkow, S. A. Harvey, J. D. Thomas, and M. S. Lauer. 1997. Importance of estimated functional capacity as a predictor of all-cause mortality among patients referred for exercise thallium single-photon emission computed tomography: Report of 3,400 patients from a single center. Journal of the American College of Cardiology 30(3):641–648.
Stukel, T. A., E. S. Fisher, D. E. Wennberg, D. A. Alter, D. J. Gottlieb, and M. J. Vermeulen. 2007. Analysis of observational studies in the presence of treatment selection bias: Effects of invasive cardiac management on AMI survival using propensity score and instrumental variable methods. Journal of the American Medical Association 297(3):278–285.
Topol, E. J., and R. M. Califf. 1994. Scorecard cardiovascular medicine. Its impact and future directions. Annals of Internal Medicine 120(1):65–70.
Turner, E. H., A. M. Matthews, E. Linardatos, R. A. Tell, and R. Rosenthal. 2008. Selective publication of antidepressant trials and its influence on apparent efficacy. New England Journal of Medicine 358(3):252–260.








































