
3
Technical Issues for the
Digital Health Infrastructure
INTRODUCTION
Information technology drives the digital learning health system, and technological innovation in several key areas will be crucial in meeting future needs for security, healthcare quality, and clinical and public health applications. These issues include building off of the foundation laid by the implementation of the American Recovery and Reinvestment Act initiatives, working toward systems interoperability, ensuring secure data liquidity, maximizing computing potential, and finding strategies to harmonize data from diverse sources. This chapter explores these issues with a vision for leveraging current technologies and identifying priorities for innovation in order to ensure that data collected in one system can be utilized across many others for a variety of different uses—for example, quality, research, public health—all of which will improve health and health care.
Douglas Fridsma from the Office of the National Coordinator for Health IT provides an update on the current standards and interoperability framework being developed. He reviews several lessons learned by past standards development efforts currently informing their approach, such as the notion that standards must be adopted not imposed, and not to let perfection be the enemy of the good. Dr. Fridsma describes the priorities shaping the work of the Office of Standards and Interoperability, highlighting the need to manage the life cycle of standards and interoperability activities by providing mechanisms for continuous refinement. He details the model being used in the development of the standards and interoperability framework which consists of interplay between community engagement,
harmonization of core concepts with other exchange models, development of implementation specifications, reference implementation, and incorporation into certification and testing initiatives. Dr. Fridsma emphasizes the need to leverage existing work, coordinate capacity, and integrate successful initiatives into the framework.
Rebecca Kush from the Clinical Data Interchange Standards Consortium shared the Institute of Electrical and Electronics Engineers’ definition of interoperability—“the ability of two or more systems or components to exchange information and to use the information that has been exchanged” (IEEE, 1990). Building on this, she suggests that one approach to defining interoperability within the digital infrastructure of the learning health system might be the exchange and aggregation of information upon which trustworthy healthcare decisions can be made. Dr. Kush cites existing enablers that will contribute to this goal, including the Coalition Against Major Diseases’s Alzheimer’s initiative to share and pool clinical trial data across pharmaceutical companies. Furthermore, she posits that a standardized core dataset of electronic health record information that could be repurposed for research, safety monitoring, quality reporting, and population health would help facilitate an interoperable digital health infrastructure. Dr. Kush shares several examples of existing standards initiatives that could be leveraged as a foundation for the learning health system, for example, increasing adverse drug event (ADE) reporting through the implementation of the ADE Spontaneous Triggered Events Recording trial.
Echoing the notion of health care as a complex adaptive system, Jonathan Silverstein, formerly of the University of Chicago (now at NorthShore University Health System), asserts that current technological failures of the healthcare system are a result of incompatibility between the technology employed and the nature of the system. He suggests that what is needed is secure data liquidity supported by a functional architecture that enables ever-expanding secure uses of health data. Dr. Silverstein proposes that this can be achieved by employing provable electronic policy enforcement in regard to access, provenance, and logging, as well through scalable data transport mechanisms and transformations that make data unambiguous and computable. He predicts that the increasing scale and complexity of medicine and biology will lead to more collaborative endeavors and sharing of resources—both data and technical. Consequently, approaches to sharing technical resources through federated hosted services such as grids and clouds—which provide scalable ways to leverage existing distributed data, transport standards, and individual expertise—promise to be a crucial part of the digital infrastructure.
Drawing on his experiences with the Indiana Network for Patient Care, Shaun Grannis of the Regenstrief Institute shares his thoughts on what will be needed to mitigate data heterogeneity in a learning health system.
Because information needed to support the functions of a learning health system must be compiled from a number of diverse data sources, integration of these data is a major barrier to learning. Dr. Grannis suggests that efforts to specify standards for vocabularies, messaging, and data transactions through interoperability specifications, standards, and use cases have not been sufficient to address this issue and new approaches are needed. He suggests that new strategies to deal with patient and provider identity management, vocabulary standardization, and value set maintenance by addressing elements including patient- and provider-level aggregation, and health system metadata, and value set maintenance should be prioritized.
BUILDING A STANDARDS AND
INTEROPERABILITY FRAMEWORK
Douglas Fridsma, M.D., Ph.D.
Office of the National Coordinator for Health Information Technology
The Office of Interoperability and Standards, a division within the Office of the National Coordinator for Health Information Technology (ONC), provides leadership and direction to support the secure and seamless exchange of health information in alignment with the national health information technology (HIT) agenda. Responsibilities of the office include advancing the development, adoption, and implementation of HIT standards; promoting the development of performance measures related to the adoption of these standards; and working with various federal agencies to evaluate mechanisms for harmonizing security and privacy practices in an interoperable HIT architecture. One of the office’s principal projects is the development of a standards and interoperability (S&I) framework—an open government initiative that uses integrated processes, tools, and resources with the goal of developing and supporting specifications guided by the healthcare and technology industry. This paper presents some background on the project and proposes a preliminary version of the framework.1
Lessons from Previous Efforts
There is a large body of existing work that can be used to inform ONC’s development of the S&I framework. Specifically, the Healthcare Information Technology Standards Panel (HITSP)—a cooperative partnership between public and private sectors—has already worked on several
___________________
1 The S&I framework was officially launched on January 7, 2011. More information can be found at http://jira.siframework.org/wiki/pages/viewpage.action?pageId=4194700 (accessed March 8, 2011).
of the key issues surrounding HIT standards and interoperability, and has accumulated important lessons and best practices that can be applied to the S&I Framework:
- Standards are not imposed, they are adopted. Widespread adoption of standards will be more effective if individuals are drawn in because of their utility, not because they are forced to by the federal government. In order to be useful, standards must address real problems, not abstract ones. This is where learning from problems encountered in previous efforts can be extremely helpful. Furthermore, engaging the community in the development of standards fosters a feeling of ownership. When stakeholders have a sense that they contributed to the development of standards they are more likely to adopt them.
- Standards should be harmonized and commissioned based on clearly articulated priorities. Without unlimited resources, there must be some degree of coordination in the development of standards. This will entail prioritizing what issues to work on and will require a governance strategy to oversee the coordination and prioritization process.
- Adoption of standards is accelerated by tools. Creating tools such as vocabulary and terminology registries will facilitate adoption. Furthermore, it is necessary to make implementation specifications easy to use. It must be clear to users that when they implement standards and engage with the system, the environment is in place so that an exchange of information is going to happen readily.
- Keep it as simple as possible but no simpler. This is the parsimony principle. Care must be taken not to “boil the ocean” but instead focus on the real problems that stand in the way of adoption.
- Perfection can be the enemy of the good. Developing standards that are perfect would take at least 5 or 10 years at which point they would no longer meet contemporary needs. It is far more useful to accelerate the development and implementation of standards so that they can be integrated into real-world settings. Once implemented, the standards can continue to be refined and improved in an iterative fashion.
Building on Existing Efforts
One of the responsibilities of the Office of Interoperability and Standards is to remain cognizant of these lessons when developing an S&I framework. Past experiences have indicated that the following priorities are crucial when moving forward:
- Move toward more “computational” implementation specifications. Developing implementation specifications that are explicit—and therefore less subject to interpretation—will increase the efficiency of development and maintenance. For example, rather than using a Word document that describes standards and how to implement them, producing an .xml file that can be implemented and customized will be much more useful and not as subject to interpretation by the user.
- Link use cases and standards from inception to certification. Certification needs to be tightly linked to the process of developing standards and implementation specifications. ONC is working to develop certification criteria and a certification process that makes it possible to test whether people are following suggested standards and specifications. Coming up with an implementation specification that cannot be tested or certified against will introduce enormous challenges down the road.
- Integrate multiple service delivery organizations with different expertise across the process. It is important that, when working to solve problems around meaningful use and other issues, ONC remain cognizant of the need to integrate across a whole host of organizations that have existing standards. For example, an electronic prescribing use case requires vocabularies and terminologies from different organizations, different transportation packages, and different standards.
- Managing the life cycle. There needs to be a controlled way to manage all of the activities within the standards and interoperability realm, from identification of a needed capability to implementation and operations. This will help to ensure that the standards developed are not static, but change as new technologies are developed and the practice of medicine evolves. A framework must serve as a mechanism for continuous refinement.
- Reuse. Standards development and harmonization efforts need to accommodate multiple stakeholders and business scenarios to ensure reuse across many communities. Within the federal government alone, there are a tremendous number of silos of excellence, all of which are creating wonderful standards but are not sharing. It will be necessary to leverage descriptions of standards and services that are being provided across different silos.
- Semantic discipline. Work products need to be developed in a way that ensures machine and human readability and traceability throughout the entire life cycle. This allows for the uniformity of concept definition that is needed to solve challenging healthcare problems where understanding of terms is critical.
- Human consensus. Achieving human consensus is a prerequisite
for computable interoperability. If stakeholders cannot agree on what a term or a concept is (or means), it will be impossible for a computer to do so.
Bottom-Up Innovation
The Office of Standards and Interoperability has in the past been perceived as employing a governance strategy that is both “command and control” as well as “1,000 flowers blooming.” The goal of the S&I framework is to find the “sweet spot” between the two—called focused collaboration (see Figure 3-1). Focused collaboration engages a broad array of stakeholders in the development process, but manages their work properly to ensure efficiency and efficacy. This avoids the pitfalls inherent in both a high degree of focus (top-down, heavy-handed, government-driven process) with little participation from outside stakeholders as well as a highly participatory
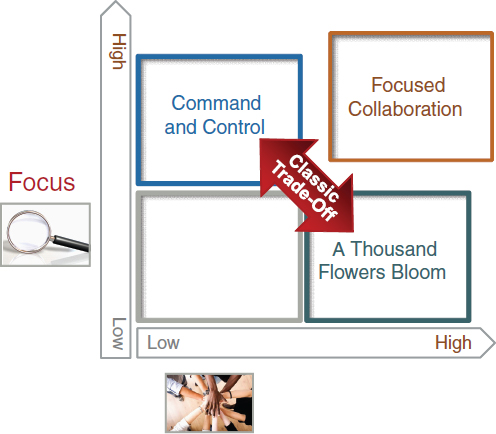
FIGURE 3-1 Focused collaboration balances high levels of focus with high levels of participation.
process with no strong focus that generates many good ideas, but no results. This creates an environment that is results oriented but at the same time is inclusive and fosters “bottom-up innovation.”
Process Overview of the S&I Framework
The S&I framework being developed by ONC is an attempt to leverage the work of HITSP and other previous standards development efforts, while designing a new process to embrace the lessons learned and best practices of prior efforts. This process is not something that will be built de novo, but will leverage and harmonize past activity. The framework (Figure 3-2) is broken down into a series of functions that are intended to guide healthcare interoperability initiatives. The first is use case and functional requirements—ONC’s outward-focused activity aimed at engaging the healthcare community by developing business scenarios to help make the case for adoption.
The next function in this model is the harmonization of core concepts. This function includes usage and adoption of the National Information Exchange Model (NIEM), and is a process that has been developed that focuses on taking use cases developed by the healthcare community and harmonizing existing standards in support. This allows for two important functions: (1) describing the data needed for information exchange and (2) describing the behaviors, functions, and services and how the information exchange supports them. The first function focuses on specifying the data that are important to be exchanged, and the second function specifies what can be done with it. Along with a policy and trust framework, this function defines what is needed to successfully exchange information.
Successfully harmonizing core concepts is a necessary step in developing implementation specifications. In many ways, developing successful imple-
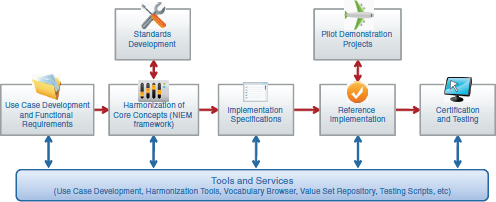
FIGURE 3-2 Preliminary schematic of the S&I framework.
mentation specifications is the way interoperability is achieved—taking all of the standards and services (ingredients) and combining them in a way that serves a particular purpose (recipe). That recipe is the implementation specification, and the S&I framework is also focused on making sure the “recipe” is understandable and “easy to bake.” Once an implementation specification has been defined, the next functions in the framework are focused on developing a reference implementation, which is a fully functioning version of the defined implementation specification, and certification and testing, which ensures that the implementation is certified against a set of requirements and fully tested. As part of these functions, pilot environments are also created so that ONC and its partners in the private and public healthcare sectors can test and evaluate how the reference implementations work.
Without reference implementations it is not possible to test whether or not implementation specifications that have been developed are usable without unforeseen problems. ONC works with the National Institute of Standards and Technology to develop the certification and testing requirements needed to test reference implementations.
It is important to note that not all of the components that are outputs of the S&I framework will be built within ONC. The vision of the framework is that, in its coordinating capacity, ONC will take the best examples and work products currently available and integrate them into a common framework, so that best-of-breed solutions come to the forefront.
Situating in the Broader Context
The S&I framework is designed to map to NIEM and its foundational structure, based on the Information Exchange Package Documentation (IEPD). (Figure 3-3). The NIEM IEPD lays out a series of artifacts that define what is needed for interoperability, and when combined with the outputs of the framework, it is expected that S&I Framework interoperability initiatives will produce the logical and foundational artifacts needed to enable health information exchange. As indicated in the figure, the S&I Framework also augments NIEM with additional features. One is a description of services, known as service specifications. While the NIEM IEPD defines exchange, it does not describe services explicitly. Additionally, the S&I framework adds implementation, testing, and certification to the NIEM model, so that information exchanges are not just developed, but tested and certified to promote adoption. These additional features are examples of how ONC is working to integrate existing initiatives such as NIEM into a broader standardization and interoperability framework for health care.
It is important to remember that the S&I framework is not designed to operate in a vacuum, as noted in (Figure 3-4). The Health Information Technology Policy Committee (HITPC) will be providing use cases and pri-
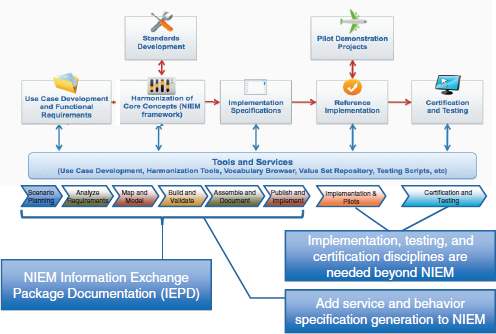
FIGURE 3-3 Mapping the S&I framework to NIEM processes.
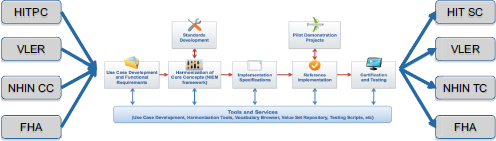
FIGURE 3-4 The S&I framework will enable stakeholder coordination throughout the standards and interoperability development life cycle.
orities to the framework and will serve as the primary source for interoperability initiatives. The Health Information Technology Standards Committee evaluates the work completed through the S&I framework process and may propose additional standards that need to be incorporated. Other programs are also integrated into the framework as important stakeholders, including the joint Department of Defense–Department of Veterans’ Affairs Virtual Lifetime Electronic Record (VLER) project, the Nationwide Health Infor-
mation Network (NWHIN) Coordinating Committee (CC) and Technical Committees (TCs), and the Federal Health Architecture (FHA). This level of broad participation and integration ensures that S&I framework functions are always aligned to the needs of the broader healthcare community.
INTEROPERABILITY FOR THE LEARNING HEALTH SYSTEM
Rebecca D. Kush, Ph.D.
Clinical Data Interchange Standards Consortium
The digital infrastructure for a learning health system must be based upon information possessing integrity and quality such that users can trust in the system and important medical decisions can be made based upon accurate information and knowledge. While search engines, signal detection, natural language processing, and other state-of-the-art techniques can potentially surface indicators and interesting information, the knowledge held in these search results is only as good as the underlying research data available. To optimize the quality of patient care, rigorous scientific methods with adequate sample sizes and comparable data should be the basis for the evidence upon which medical decisions are made. Unfortunately, the time frame cited today for bringing research results into clinical care decisions is purportedly on the order of 17 years (Lamont, 2005). Recent government incentives in the United States have provided a new opportunity to change the current “ignorant” system into a true learning system by creating an appropriate electronic digital infrastructure as electronic health records (EHRs) are adopted across the nation. Interoperability to enable data sharing and the ability to aggregate adequate, analyzable information upon which to base scientific conclusions are at the heart of this infrastructure.
Interoperability has been defined by the Institute of Electrical and Electronics Engineers as “the ability of two or more systems or components to exchange information and to use the information that has been exchanged” (IEEE, 1990). To be more specific, one can differentiate between syntactic and semantic interoperability. Syntactic interoperability occurs if two or more systems are capable of communicating and exchanging data. Fundamental to this type of communication are specified data formats or communication protocols (such as SQL, XML, or even ASCII). Syntactic interoperability is a requirement for any further attempts at interoperability. Semantic interoperability, which goes beyond simply exchanging information, is the ability to automatically interpret the information exchanged meaningfully and accurately in order to produce useful results. Semantic interoperability requires a common information exchange reference model to ensure that what is sent is understood by the recipient.
In the cycle of an informed healthcare system, medical research is based upon healthcare information and, in turn, clinical decisions are based upon research results. Medical research or clinical research are terms used broadly in this context. They include the understanding of diseases, discovery and testing of new therapies, comparative effectiveness research (CER), understanding responses to therapies (e.g., personalized health care, biomarkers, and genomics), safety monitoring, biosurveillance, and evaluating quality. For the purpose of defining a digital infrastructure and understanding the essential role of interoperability, one aspect of the definition of a learning health system could be efficient exchange (and aggregation) of sufficient high quality, meaningful information upon which trustworthy decisions can be leveraged to improve health care for all of us, as patients.
The path to interoperability, in an ideal situation would rely on both a common information exchange reference model as well as controlled terminology. However, the real situation is that we are faced with competing terminologies and repositories; mapping, legacy data conversion, and normalization; and we have competing models and “mini-models” such as clinical data elements, detailed clinical models, archetypes, and clinical element models. Approaches to deal with this reality are surfacing solutions such as service-oriented architecture and Services-Aware Interoperability Framework. These issues will need to be addressed in terms of the digital infrastructure to turn an inefficient and ignorant system into a learning health system.
Valuable Enablers to a Learning Healthcare System
The Critical Path Institute2 has brought the Food and Drug Administration (FDA), the European Medicines Agency (EMA), the National Institutes of Health, and biopharmaceutical companies together to form the Coalition Against Major Diseases (CAMD). CAMD—a unique public–private partnership tasked with better understanding neuro-degenerative diseases—has now produced a new database of information on more than 4,000 Alzheimer’s disease patients who have participated in 11 industry-sponsored clinical trials. This is the first database of combined clinical trials to be openly shared by pharmaceutical companies and made available to qualified researchers around the world. Disease modeling, biomarker validation, and the gleaning of knowledge from failed therapies and placebo patient data for Alzheimer’s disease are techniques anticipated to enable an improved process of therapy development and evaluation.
The aggregation of sufficient information from these patients required a “common model” for which CAMD selected the Study Data Tabulation
___________________
2 See http://www.c-path.org/CAMD.cfm (accessed September 13, 2010).
Model (SDTM). SDTM was developed through a global, open consensus-based standards development process led by the Clinical Data Interchange Standards Consortium (CDISC). Unfortunately, since the original clinical trials were conducted using proprietary standards, or no standards at all, the data had to be mapped into the SDTM format before the database could be developed. Also, standard formats for the Alzheimer’s-specific efficacy data were necessary to augment the existing SDTM standard safety data domains. Now that these are available, future research studies on Alzheimer’s patients can be designed to collect the data in the standard format “up front,” which will facilitate ready aggregation into the database in the future.
This will also accelerate study start-up. A business case conducted with Gartner indicated that the use of CDISC standards at the beginning of the medical research process (study startup) can reduce startup (cycle time) by 70–90% (Rozwell et al., 2007). In other words, a study can be initiated faster and with significantly fewer resources (time and personnel) if standards are employed. In addition to these objective savings, the use of the standards resulted in higher data quality and integrity, improved communication among stakeholders/project teams, and flexibility in selecting technologies that work together. The standards enable ready data aggregation and semantic interoperability among proprietary or unique technologies as long as these technologies inherently support the research standards.
One key enabler of a learning health system would be to have a core dataset (with common value sets and terminology) that is “standard” as a base to support multiple purposes. Ideally, these data would be collected once in an EHR and the be repurposed for multiple different uses, including but not limited to medical research, CER, safety monitoring, quality reporting, public and population health, and other uses.
This is not feasible today since we cannot even all agree, for example, on whether a patient’s sex (or gender) is collected as male/female, M/F, 2/1, 1/2, or even if there are 2, 4, or 15 options in the value set for gender (or is it sex?). Automated teller machines and credit cards work today because there is a core set of information that has been agreed upon and standardized across banks/card issuers—that is, codes for credit card type, cardholder type, 16-digit card number, expiration data, 3-digit code on the back. Such electronic data interchange standards allow access to personal banking and funds around the world.
Dr. John Halamka, in his blog comments3 on ONC’s HIT Standards Committee Testimony, listed a set of “Gold Star Ideas.” The following three stand out:
___________________
3 See http://geekdoctor.blogspot.com/2009_10_01_archive.html (accessed February 23, 2011).
- We’ve learned from other industries that starting with simple standards works well.
- Keep the standards as minimal as possible to support the business goal.
- Start immediately rather than waiting for the perfect standard.
This begs the question of what is available that could be used now as a foundation upon which a learning healthcare system can build. It is critically important to start now to ensure convergence of the current “meaningful use” criteria with future efforts to enable a healthcare system that can take rapid advantage of scientific findings.
Leveraging Existing Enablers
Following are existing enablers that could be leveraged now to provide a foundation for a learning healthcare system.
eSource Data Interchange (eSDI) Initiative
The purpose of this initiative (a collaboration between CDISC and FDA) was to facilitate the use of electronic technology in the context of existing regulations for the collection of eSource data in clinical research. The term eSource pertains to collecting data electronically initially through such technologies as e-diaries, e-patient-reported outcomes, e-data collection instruments, and EHRs. The overarching goals of this initiative were to make it easier for physicians to conduct clinical research, to collect data only once in a global research standard format for multiple downstream uses, and to improve data quality and patient safety. The product is the eSDI Document,4 which contains 12 requirements for eSource that comply with existing regulations for electronic record retention good clinical practices. This document and the 12 requirements, specifically, are cited by the EMA for their field auditors.5
Workflow Integration
The eSDI Initiative formed the basis for the Retrieve Form for Data Capture (RFD) Integration Profile,6 which was collaboratively developed
___________________
4 See http://www.cdisc.org/eSDI/eSDI.pdf (accessed September 14, 2010).
5 See http://www.ema.europa.eu/ema/index.jsp?curl=pages/regulation/document_listing/document_listing_000136.jsp&jsenabled=true (accessed September 14, 2010).
6 See http://wiki.ihe.net/index.php?title=Retrieve_Form_for_Data_Capture (accessed September 14, 2010).
by CDISC and Integrating the Healthcare Enterprise (IHE). This is an extremely powerful workflow integration profile that streamlines the use of an EHR for a variety of purposes. It is easily implemented, which has led to its endorsement by the EHR Association.7
Global Clinical Research Standards and BRIDG
Through a global, consensus-based standards development process, a suite of open and freely available standards has been developed to support medical research from protocol through reporting. These are harmonized through the Biomedical Research Integrated Domain Group (BRIDG) model and have a common set of controlled terminology openly housed and curated through the National Cancer Institute (NCI) Enterprise Vocabulary Services (EVS). The BRIDG model was so named because it bridges research and health care in addition to bridging organizations and stakeholders. The harmonized global research standards are depicted in Figure 3-5. One particular standard that would pave the way for a learning health system is the Clinical Data Acquisition Standards Harmonization (CDASH),8 which defines a core minimum research dataset.
Standards-Inspired Innovation
The mission of CDISC is to develop and support global, platform-independent data standards that enable information system interoperability to improve medical research and related areas of health care. To this end, a concerted effort has been made to ensure interoperability between research and health care. In addition to the BRIDG model, through the development of the CDISC IHE RFD integration profile the eSDI work has been leveraged to streamline the workflow from EHRs/clinicians who wish to conduct research or support other enhanced uses of clinical information. CDASH, in particular, was developed collaboratively through the FDA’s Critical Path Initiative. CDASH is a case report form/data collection standard that represents a core minimum dataset to support 18 domains for any clinical research study. CDASH has been “mapped” to the CCD (or the Continuity of Care Document) such that EHRs can produce a core research dataset (the CDASH clinical research data elements). Together the CCD, the IHE RFD integration profile, and CDASH constitute an interoperability specification that readily supports the conduct of clinical research using EHRs, while adhering to existing regulations for research (Figure 3-6).
___________________
7 See http://www.cdisc.org/stuff/contentmgr/files/0/f5a0121d251a348a87466028e156d3c3/miscdocs/ehra_cdisc_endorsement_letter_100908.pdf (accessed September 14, 2010).
8 See http://www.cdisc.org/cdash (accessed September 14, 2010).
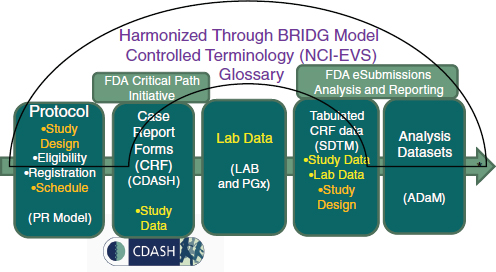
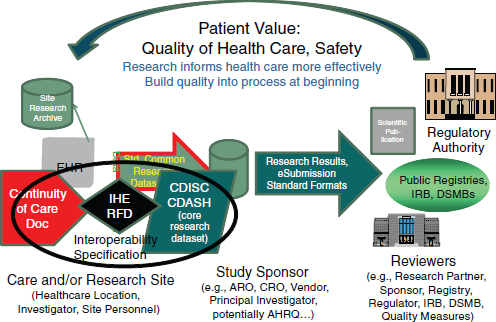
Unfortunately, standards are frequently misperceived as stifling creativity in research. However, they have been known to inspire innovation in other industries. In the aforementioned interoperability specification, standards are, in reality, enablers of workflow and efficiencies in the processes associated with a learning health system. A number of implementations are now in place around the world to leverage enablers. For example, the Adverse Drug Event Spontaneous Triggered Event Recording study has brought safety reporting from >34 minutes (which meant that a busy clinician would not make such a report) to less than a minute (which increased reporting dramatically) (Neuer, 2009). Other use cases include outbreak reporting and clinical research studies, with the potential to harmonize with quality reporting measures. Currently in progress is a new integration profile (based on Business Process Execution Language) that will leverage the CDISC Protocol Representation Model to automate research subject identification, patient scheduling, and data collection by visit, thus making it far easier for physicians to conduct research or adhere to reporting requirements.
Standards-Inspired Innovation
A core dataset with standard value sets and terminology can dramatically reduce time and effort to report key information for safety, research, and public health; accommodate e-diaries and other patient-entered data; improve data quality; enable data aggregation and analysis or queries; be extensible and pave the way for more complex research and clinical genomics for personalized health care; and be readily implemented by EHR vendors.
While search engines and signal detection have their place in the learning health system, ensuring the integrity of the search results—and thus trust in the knowledge upon which clinical decisions are based—a learning health system must support rigorous scientific research. The current research process is antiquated and ripe for transformation. EHRs may provide the impetus for necessary changes.
PROMOTING SECURE DATA LIQUIDITY
Jonathan C. Silverstein, M.D., M.S.
The University of Chicago (formerly)
North Shore University Health System
Any healthcare system is made up of individual people and institutions. Whether focused on clinical care, population health, quality, or research, each entity is goal directed while being dependent upon the activities of others. In the current healthcare environment, these dependencies are often
problematic due to misalignment of individual incentives, policy restrictions, and competition for control rather than competition for value (Porter and Teisberg, 2006). This is sufficiently obvious in the fact that it is acceptable to assert that the U.S. healthcare system is failing to systematically deliver measurable quality at acceptable cost.
Health Care Is a Complex Adaptive System
We do not assign the assertion that the system is failing as fault to any entity. In fact, there are exceptional institutions that can effectively deliver measurable quality at acceptable cost. Unfortunately, this cannot be demonstrated for the system as a whole. Rather, we assert that the failure at the system level is a result of not matching the technology required to enable a functioning system with the nature of the system itself. Health care and biomedicine in the United States exist as complex adaptive systems and needs the underpinning technology infrastructure to match.
A complex adaptive system is a collection of individual agents that have the freedom to act in ways that are not always predictable and whose actions are interconnected. (IOM, 2001). Ralph Stacey (1996) describes these essential characteristics of a complex adaptive system:
- Nonlinear and dynamic.
- Agents are independent and intelligent.
- Goals and behaviors often in conflict.
- Self-organization through adaptation and learning.
- No single point(s) of control.
- Hierarchical decomposition has limited value.
The Need for Secure Data Liquidity
If we accept that these characteristics of a complex adaptive system match the reality of the healthcare system, as we develop shared responsibility, policy, governance, and competition for value, we will need matching infrastructures that are driven from a systems-level perspective and that scale. Such infrastructures must enable integration, interoperation, and secured appropriate access to biomedical data on a national scale. Useful data will emerge from multiple sources and need to be distributed for multiple creative reuses to drive better understanding and decision making. This, in turn, drives the need for provably secure systems that work across organizations. In short, we need to develop and deploy systems for secure data liquidity.
Secure data liquidity is a catch phrase for a functional architecture that enables an explosion of new uses of healthcare data by making two
things possible: provable electronic policy enforcement in regard to who is delivered precisely what data for what purpose (flexible, robust access control, provenance, and logging—or “secure data”); and scalable data pipelines and transformations that make data unambiguous and computable such that data from multiple sources can be used together in meaningful ways (“liquid data”). We need to break through from having data locked up and unlinked, to a situation where data flow for many purposes, with provable security in regard to who is permitted to use, and is, using, which data for what purpose (“secure data liquidity”). Too often the Health Insurance Portability and Accountability Act has been interpreted defensively, driving risk avoidance rather than motivating best practices for systems and data management. As a result, secure data liquidity has, to date, been undesirable by individual organizations and therefore unattainable. The limitations are not technical but sociotechnical.
As biology and medicine undergo their digital transformation, more and more collaborative endeavors among investigators and clinicians will emerge. Technical resources will be increasingly shared as well. Even the world’s largest supercomputers—standing as silos, rather than connected—aren’t enough to move, store, or analyze all of the available data. When multiple entities need to share, there are natural security concerns, resource utilization and scheduling problems, and the need for data movement across organizations. These cannot be satisfied in a single, monolithic system with the required multiorganizational security, flexibility, extensibility, redundancy, stability, robustness in multiple industries, openness, and lack of central ownership. These technical requirements underpinning multiinstitutional resource sharing toward common goals are just beginning to be appreciated by the private sector and governments. As they begin to face the issues squarely, some technology will need to be deployed in order to harvest these socioeconomic benefits.
Federated, Hosted Services (e.g., Grids and Clouds)
Ian Foster described a federated framework of service-oriented science based in grid computing approaches in which individuals with varying expertise can create services (e.g., data services, algorithms, pipelines) which others discover and compose to create a new function, and then publish as a new service (Foster, 2005). In this model, each actor in the system does not have to become an expert in operating services and computer infrastructure. Instead, they depend upon “others” to host services and manage the underpinning security, reliability, and scalability. In this way, everyone is leveraged for their own expertise. Federation and hosting of services allows people, organizations, or institutions to “outsource the complex and mundane activities” to third parties. These enabling features map quite closely
to the problems facing health and biomedical systems—that of multiple, often competing, and differentially motivated entities—that need to work together to care for patients, improve public health, and conduct research. Thus, effective use of federation and hosted technical approaches have great potential impact in enabling the learning healthcare system.
Grossly oversimplified, grid approaches can be thought of as federations toward data and computation sharing across assemblies of multiple organizations driven by complex multiorganizational functional requirements. The grid paradigm is a combination of philosophy and technology including principles and mechanisms for dynamic sets of individuals and/or institutions engaged in the controlled sharing of resources in pursuit of common goals (virtual organizations), leveraging service-oriented architecture, loose coupling of data and services, and open software and architecture (Foster, 2002; Foster et al., 2001). Grid is not a technology, but rather a set of approaches that have moved through several technological generations in the last 15 years. This approach remains robust, flexible, secure, and is increasingly deployed in the biomedical sciences.9
In contrast, clouds can be thought of as an approach toward data and computation hosting driven by business models leveraging outsourcing and economies of scale. This is most prototypically achieved technically by deploying on-the-fly multiple identical virtual machines—infrastructure-as-a-service. Amazon’s Elastic Compute Cloud10 is a prime example. Cloud approaches also provide scalable software-as-a-service (Salesforce.com11) and platform-as-as-service (Google’s App Engine12).
These science-based approaches and business-based technical approaches need to converge to support the complex nature of biomedicine and promote the development of a learning health system. Both grids and clouds leverage core Internet protocols and services and are typically deployed in a services-oriented approach. Thus, combining characteristics of grids and clouds in a hosted federation of services is required for the digital infrastructure of the learning health system. At the same time we are learning to value crowd-sourced information, or information that is annotated and curated by individuals most familiar with the data.
___________________
9 For examples of the grid approach, see http://www.opensciencegrid.org; http://www.birncommunity.org; http://www.cagrid.org (accessed December 17, 2010).
10 See http://aws.amazon.com/ec2/ (accessed December 17, 2010).
11 See http://www.salesforce.com (accessed December 17, 2010).
12 See http://code.google.com/appengine/ (accessed December 17, 2010).
Hosted Federations of Services Can Transform Health Care
Facing squarely the many sociotechnical issues in the health domain will drive deeper understanding among healthcare policy makers, health information managers, and lawyers. This in turn should drive individual organizational social behaviors away from risk avoidance and fear in regard to health information privacy, and toward good data management practices that effectively reduce risk.
Although health and medicine have their own custom set of requirements—particularly in regard to specific workflows and data standards—we need to leverage the existing distributed computing models and Internet standards as we address problems of scale instead of attempting to build new healthcare-specific infrastructures. This cannot occur in a monolithic system. Thus, there is an inevitable need for a distributed computing approach that will foster the generation of new knowledge and drive better care based on that knowledge. The convergence of grid and cloud systems can address the required enabling multiorganizational, scalable technical characteristics:
- Attribute-based authorization.
- Distributed identity management.
- End-to-end security.
- Data naming, linking, movement, and integration.
- Flexible, but enforceable policy/sociability.
- Extensibility.
- Redundancy.
- Robust in multiple industries/stability.
- Without central ownership/manageability.
Summary
The issues facing health and biomedical systems of multiple—often competing and differentially motivated—entities that need to work together to care for patients, improve population health, and conduct research can be addressed by federated (grid) approaches in combination with hosted (cloud) approaches. The general idea of infrastructure on demand drove both cloud and grid. Whereas cloud emerged from virtualization of machines, business models, and flexible capacity, grid evolved from virtualization of organizations, social models, flexible capabilities, security, and open services. Both head toward hosted federation of services which are promising paths to transforming healthcare into a high performing system.
INNOVATIVE APPROACHES TO INFORMATION DIVERSITY
Shaun Grannis, M.D., M.S.
Regenstrief Institute
Comprehensive clinical information stitched together from a diverse set of data sources supports many healthcare processes including direct patient care, population health management, quality improvement, and comparative effectiveness research (CER). However, these data are captured from many independent systems with complex relationships where information is stored as separate islands with different identifiers, names, and codes. Such heterogeneity impedes seamless integration of data by the healthcare system. Therefore, to effectively and efficiently support the informational needs of a variety of healthcare processes, approaches to managing system complexities and information heterogeneity are needed.
Adding to the challenge is that fundamental perspectives on the nature of complexity often differ. To illustrate, Alan Perlis, a computer science luminary, suggests that complexity can be abrogated when he said, “Fools ignore complexity. Pragmatists suffer with it. Some people can avoid it. Geniuses remove it” (Perlis, 1982). If simplicity can be taken as the opposite of complexity, Albert Einstein suggested that achieving maximal simplicity (and thus minimizing complexity) may be ill-advised with his exhortation to “make things as simple as possible, but no simpler.”13 With differing perspectives on the degree to which complexity can or should be mitigated, strategies designed to address the challenge may vary substantively.
The Challenge of Heterogeneous Data
These strategies are critical to the success of Health Information Exchanges (HIEs) because HIEs are an amalgamation of many healthcare data sources with data quality characteristics that vary both by data source and by time. Consequently, HIEs pose particularly illustrative data heterogeneity challenges. These challenges are driving HIEs to become emergent centers of innovation in health data management with core competencies that focus on standardizing and integrating clinical data to support the informational needs of myriad healthcare processes. Stated simply, addressing the complex task of managing information heterogeneity is an intrinsic HIE function.
As clinical data are captured from an increasing number of sources, heterogeneity of data threatens to impede progress toward meaningful use,
___________________
13 See http://rescomp.stanford.edu/~cheshire/EinsteinQuotes.html (accessed February 23, 2011).
CER, and high-quality delivery of health care. Specifying standards for vocabularies, messages, and transactions will not be sufficient to mitigate substantial variations in data from different systems. New strategies will be required in the areas of patient and provider identity management, vocabulary standardization, and value set maintenance to facilitate quality reporting and disease surveillance in the future.
The fundamental premise of this paper is that while much energy has been spent on interoperability specifications, on standards, and on use cases, they are not sufficient. There are other necessary elements required to enable electronic sharing of semantically interoperable data. These elements include patient-level data aggregation, physician-level data aggregation, healthcare system metadata, and value set maintenance. In this paper I will draw on our experience with the Indiana Network for Patient Care (INPC), one of the nation’s most comprehensive and longest-tenured HIEs, to highlight some of these additional elements.
Differing opinions on the degree to which healthcare system complexity can or should be mitigated leads to differing strategies for addressing the challenges. Some may disagree with our approaches. What I hope this paper does is put a pebble in your shoe. You might not agree with how we went about a certain operation—but hopefully this discomfort may motivate you to understand the reason why we are doing it.
The Indiana Network for Patient Care
The INPC contains more than 3.1 billion coded standardized clinical observations, and a global patient index that holds more than 20 million person:source entities that represent more than 12 million unique individuals. Since the mid-1990s, the INPC global patient identity resolution service resolves identities from real-time clinical data streams provided by myriad sources with widely varying data quality. Currently, the INPC global patient identity resolution service adjudicates identities for between 350,000 and 1 million transactions received daily from over 1,100 distinct participating HIE sources.
With data extending back over 30 years, the INPC connects over 80 hospitals, as well as numerous outpatient clinics, ancillary laboratory systems, and public health organizations (Figure 3-7). These data are used for population health, population and clinical decision support, quality reporting, and research—all supported using standards that existed in the late 1990s and early 2000s. Of the 500,000 to 1 million clinical transactions per day being added to the system, about 99% of the data are in HL7 version 2. Hospitals, clinics, and other sources submit their data to the system utilizing their own local code. There was an effort to have the participating organizations standardize their data sources before submit-
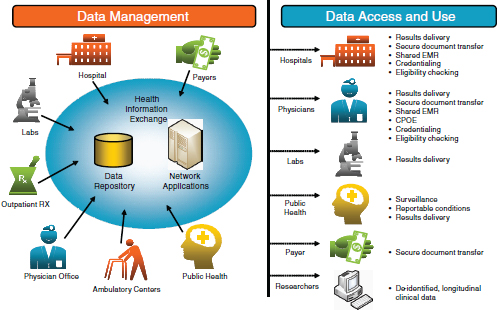
FIGURE 3-7 Schematic of the Indiana Network for Patient Care.
ting them to the system, but this did not last long. The administrators basically said that if there was value in having the data standardized then we would have do it ourselves. They did not see the value in this. Their priorities were taking care of patients, submitting bills, and the like. So, now we’ve hired five full-time employees whose entire job is mapping and clinical standardization.
All of the data for each provider or business entity go into a separate logical vault. We employ an entity-attribute-value data model, so as new terms are created and new vocabulary standards are produced, we are able to simply add new observation types to our database. Hence, the data model changes little over time. Although there are incremental changes, the core of the data model has been the same since the 1980s.
Domains of Data Standardization
The focus of our data standardization work falls into three main areas. First, patient data need to be standardized so that we can identify the same patient who is seen at many different parts of the healthcare system. We also need to standardize physician data since a single doctor can practice at multiple hospitals and be at multiple clinics throughout the week. Finally, we need to standardize metadata including business rules, knowledge basis, and so forth.
Patient-Level Aggregation
Many might assume that patient-level aggregation has been solved. But all of the studies to date on patient linking have been conducted using homogeneous data sources, not the kind of heterogeneous data that exist within most systems. Common errors in data input—a certain registration clerk at the local community hospital who always puts the date of birth in the wrong field or who always switches the last name and the first name—also present challenges. But these are the real-world issues that need to be addressed. What sort of matching methodologies would be needed to accommodate this kind of data heterogeneity?
A classic example of patient-level identification uncertainty is with newborns. When a baby is born, the first name is often not known and there is certainly not a social security number available. Yet, we still need to be able to link individual children from the newborn screening record to vital statistics. We also need to know if a patient has been screened for newborn diseases. In order to do that at INPC, we actually query the health department’s newborn screening registry. When a patient is not in the newborn screening registry we send out an alert that a match needs to be found. The matching algorithms of the vast majority of commercial products, such as maximum likelihood estimators, fail in this population.
Our research has shown that there are ways to accommodate this kind of matching. However, until we actually start to look at the diverse data sources—and understand the different cohorts and pieces—we are not going to develop solutions. It is crucial that we look at the data as they exist today so that we can move from a diverse set of data to something more standard and interoperable. This work can only take place incrementally. We will not get all of the way there in 5, or even 10 years. In the meantime, however, we need to share strategies to understand the implications of data heterogeneity and begin to design solutions.
Physician-Level Aggregation
The second area for standardization research is physician-level aggregation. Despite the fact that a National Provider ID is mandated by Medicaid, there are many clinical transactions that lack a provider ID. Even on the billing side, Medicaid had to push back the deadline an entire year because hospitals were not ready to implement physician identifiers.
In addition, many clinical transactions do not contain sufficient physician data to generate quality reports for providers. As a result, the identifying information must be added manually by contacting the clinic to confirm which physician or provider was involved in a particular case. So, the national provider ID helps, but is not prevalent enough yet.
Healthcare System Metadata
At the level of healthcare system metadata, there are pieces of information that are important as we look at CER or quality reporting. This information includes which providers practice together, how different providers influence the quality of care, etc.
Another challenging area is patient-provider attribution that links a specific patient to the specific provider who performed the care. Knowing that information is critical to quality reporting so that outcomes can be assessed for providers and groups of providers. Other important information includes when new equipment, devices, and interventions were available for clinical use at specific locations and under which drug formulary a particular doctor was practicing? This information is crucial to understand healthcare outcomes.
Maintaining Value Sets
The final component to our research on data standardization and interoperability research is on maintaining value sets. A value set is a collection of concepts drawn from one or more controlled terminology systems and grouped together for a specific purpose—for example, ICD-9, SNOMED, and LOINC®. In addition to establishing specifications for individual value sets, the relationships between value sets needs to be maintained.
For example, INPC has an automated public health reporting system called the Notifiable Condition Detector. This system tracks hundreds of thousands of transactions every day and determines whether each transaction is a reportable event or not. To accomplish this, it uses a reference table called the Public Health Information Network Notifiable Condition Mapping Table (PHIN-NCMT), which was developed jointly by the Centers for Disease Control and Prevention (CDC), the Council of State and Territorial Epidemiologists, and the Regenstrief Institute to map standardized test codes to the conditions for which that test may be reportable.
Since the time of the initial PHIN-NCMT development, however, stakeholders at CDC and Regenstrief have maintained the reference table independently and the two tables have diverged considerably. There is currently no coordination among stakeholders when the disease list is changed or a new test added. Yet, if there is to be consistent reporting nationwide, these tables need to be maintained and synchronized.
Conclusion
As clinical data are collected from an increasing number of divergent systems, the prevalence of data heterogeneity will only increase. This varia-
tion impedes the aggregation of individual data across sources and hinders the use of these data in the delivery of care, public health reporting, clinical research, and related activities. Specifying standards is just one element of the solution to information heterogeneity. New strategies are also needed in the areas of patient matching, physician linkage, and value set maintenance to provide the most comprehensive health information for the benefit of individual and public health.
REFERENCES
Foster, I. 2002. The grid: A new infrastructure for 21st century science. Physics Today 55:42-47.
———. 2005. Service-oriented science. Science 308(5723):814-817.
Foster, I., C. Kesselman, and S. Tuecke. 2001. The anatomy of the grid: Enabling scalable virtual organizations. International Journal of High Performance Computing 15(3):200-222.
IEEE (Institute of Electrical and Electronics Engineers). 1990. IEEE standard computer dictionary: A compilation of IEEE standard computer glossaries. New York: IEEE.
IOM (Institute of Medicine). 2001. Crossing the quality chasm: A new health system for the 21st century. Washington, DC: National Academy Press.
Lamont, J. 2005. How KM can help cure medical errors. http://www.kmworld.com/Articles/Editorial/Feature/How-KM-can-help-cure-medical-errors-9606.aspx (accessed September 14, 2010).
Neuer, A. 2009. ASTER study jumpstarts adverse event reporting. http://www.ecliniqua.com/eCliniqua_article.aspx?id=93784 (accessed September 14, 2010).
Perlis, A. J. 1982. Special feature: Epigrams on programming. Association for Computing Machinery SIGPLAN Notices 17(9):7-13.
Porter, M. E., and E. O. Teisberg. 2006. Redefining health care: Creating value-based competition on results. Boston, MA: Harvard Business School Press.
Rozwell, C., R. Kush, and E. Helton. 2007. Saving time and money. Applied Clinical Trials 16(6):70-74.
Stacey, R. D. 1996. Complexity and creativity in organizations. San Francisco, CA: Berrett-Koehler.


























