
Elements of a Computer Science Research Agenda for Sustainability
The discussion of sustainability challenges in Chapter 1 shows that there are numerous opportunities for information technology (IT) to have an impact on these global challenges. A chief goal of computer science (CS) in sustainability can be viewed as that of informing, supporting, facilitating, and sometimes automating decision making—decision making which leads to actions that will have significant impacts on achieving sustainability objectives. The committee uses the term “decision making” in a broad sense—encompassing individual behaviors, organizational activities, and policy making. Informed decisions and their associated actions are at the root of all of these activities.
A key to enabling information-driven decision making is to establish models and feed them with measurement data. Various algorithmic approaches, such as optimization or triggers, can be used to support and automate decisions and to drive action. Sensing—that is, taking and collecting measurements—is a core component of this approach. In many cases, models are established on the basis of previous work in the various natural sciences. However, in many cases such models have yet to be developed, or existing models are insufficient to support decision making and need to be refined. To discover models, multiple dimensions of data need to be analyzed, either for the testing of a hypothesis or the establishing of a hypothesis through the identification of relationships among various dimensions of measured data. Data-analysis and datamining tools—some existing and some to be developed—can assist with this task.
Once a model is established, “what-if” scenarios can be simulated, evaluated, and used as input for decision making. Modeling and simulation tools vary widely, from spreadsheets to highly sophisticated modeling environments. When a model reaches a certain maturity and trust level, algorithms, such as optimizations or triggers, can be deployed to automate the decision making if automation is appropriate (for example, in terms of actuation). Alternatively, information can be distilled and presented in visual, interactive, or otherwise usable ways so that other agents—individuals, organizations and businesses, and policy makers and governments—can deliberate, coordinate, and ultimately make appropriate, better-optimized choices and, ultimately, actions.
All of the steps described above must be done in an iterative fashion. Given that most sustainability challenges involve complex, interacting systems of systems undergoing constant change, all aspects of sensing, modeling, and action need to be refined, revised, or transformed as new information and deeper understandings are gained. A strong approach is to deploy technology in the field using reasonably well understood techniques to explore the space and to map where there are gaps needing work. Existing data and models then help provide context for developing qualitatively new techniques and technologies for even better solutions.
FINDING: Enabling and informing actions and decision making by both machines and humans are key components of what CS and IT contribute to sustainability objectives, and they demand advances in a number of topics related to human-computer interaction. Such topics include the presentation of complex and uncertain information in useful, actionable ways; the improvement of interfaces for interacting with very complex systems; and ongoing advances in understanding how such systems interact with individuals, organizations, and existing practices.
Many aspects of computer science and computer science research are relevant to these challenges. In this chapter, the committee describes four broad research areas, listed below, that can be viewed as organizing themes for research programs and that have the potential for significant positive impact on sustainability. The list is not prioritized. Efforts in all of the areas will be needed, often in tandem.
- Measurement and instrumentation;
- Information-intensive systems;
- Analysis, modeling, simulation, and optimization; and
- Human-centered systems.
For each area, examples of research problems focused on sustainability opportunities are given. The discussions do not provide a comprehensive list of problems to be solved, but do provide exemplars of the type of work that both advances computer science and has the potential to advance sustainability objectives significantly. In examining opportunities for research in CS and sustainability, questions that one should attempt to answer include these: What is the potential impact for sustainability? What is the level of CS innovation needed to make meaningful progress?
As discussed in Chapter 1, complete solutions to global sustainability challenges will require deep economic, political, and cultural changes. With regard to those changes, the potential role for CS and IT research discussed in this chapter is often indirect, but it is still important. For example, CS research could focus on innovative ways for citizens to deliberate over and to engage with government and with one another about these issues, with the deliberations closely grounded in data and scientific theory. For some critical sustainability challenges, such as the anticipated effects of global population growth, the potential CS research contribution is almost entirely of this indirect character. For instance, there is potential for using the results of modeling and visualization research toward the aim of improved education and better understanding of population and related issues. In addition, advances in IT in the areas of remote sensing, network connectivity services, adaptive architectures, and approaches for enhanced health diagnosis and care delivery—especially in rural areas—also have a bearing on population concerns. Other contributions from CS and IT research toward meeting such challenges could be aimed at developing tools to support thoughtful deliberation, with particular emphasis on encompassing widely differing views and perspectives.
The research areas described in this chapter correspond well with the broader topics of measurement, data mining, modeling, control, and human-computer interaction, which are, of course, well-established research areas in computer science. This overlap with established research areas has positive implications—in particular, the fact that research communities are already established making it unnecessary to develop entirely new areas of investigation. At the same time, the committee believes that there is real opportunity in these areas for significant impacts on global sustainability challenges. Finding a way to achieve such impacts effectively may require new approaches to these problems and almost certainly new ways of conducting research.
In terms of a broad research program, an important question is how to structure a portfolio that spans a range of fundamental questions, pilot efforts, and deployed technologies while maintaining focus on sustainability objectives. For any given research area in the sustainability space,
efforts can have an impact in a spectrum of ways. First, one can explore the immediate applicability of known techniques: What things do we know how to do already with computational techniques and tools, and how can we immediately apply them to a given sustainability challenge? Second, one can seek opportunities to apply known techniques in innovative ways: Where are the opportunities in which the straightforward application of a known technique will not work but where it seems promising to transform or translate a known technique into the domain of a particular sustainability challenge? This process tends to transform the techniques themselves into new forms. Finally, one can search for the areas in which innovation and the development of fundamentally new computer science techniques, tools, and methodologies are needed to meet sustainability challenges. While endorsing approaches across this spectrum, the committee urges emphasis on solutions that have the potential for significant impacts and urges the avoidance of simply developing or improving technology for its own sake.
The advancing of sustainability objectives is central to the research agenda outlined in this report. As in any solution-oriented research space, there is a tension between solving a substantive domain problem, perhaps creating tools, techniques, and methods that are particularly germane to the domain, and tackling generalized problems, perhaps motivated by the domain, for which solutions advance the broader field. (Chapter 3 discusses this challenge in more detail and provides the committee’s recommendations on structuring research programs and developing research communities in ways that constructively address these issues.) When focusing on the challenges presented in a particular domain, it is often essential that the details are right in order for the work to have meaningful impact. For the work to have broader impact, it must be possible to transcend the details of a particular problem and setting. Much of the power in computer science derives from the development of appropriate abstractions that capture essential characteristics, hide unnecessary detail, and permit solutions to subproblems to be composed into solutions to larger problems. A focus on getting the abstraction right for large impact, appropriability, and generalizability is important. Simultaneously, it is important to characterize aspects of the solution that are not generalizable.
FINDING: Although current technologies can and should be put to immediate use, CS research and IT innovation will be critical to meeting sustainability challenges. Effectively realizing the potential of CS to address sustainability challenges will require sustained and appropriately structured and tailored investments in CS research.
PRINCIPLE: A CS research agenda to address sustainability should incorporate sustained effort in measurement and instrumentation; information-intensive systems; analysis, modeling, simulation, and optimization; and human-centered systems.
MEASUREMENT AND INSTRUMENTATION
Historically, sensors, meters, gauges, and instruments have been deployed and used within the vertically integrated context of a single task or system. For example, a zone thermostat triggers the in flow of cold or hot air into specific rooms when the measured air temperature deviates from the target set point by an amount in excess of the guard band; the manifold pressure sensor in a car dictates the engine ignition timing adjustment; the household electric meter is the basis for the monthly utility bill; water temperature, salinity, and turbidity sensors are placed at particular junctures in a river to determine the effects of mixing and runoff; and so on. Examples of specific scenarios are innumerable and incredibly diverse, but they have in common the following: the selection of the measurement device, its placement and role in the encompassing system or process, and the interpretation of the readings it produces are all determined a priori, at design time, and the resulting system is essentially closed—sensor readings are not used outside the system.1
This situation has changed dramatically over the past couple of decades owing to the following key factors:
• Embedded computing. Until the 1990s, the electronics associated with the analog-to-digital conversion, the rescaling to engineering units, and the associated storage and the data processing dwarfed the size and cost of the transducer used to convert the physical phenomenon to an electrical signal. Consequently, these electronics were shared resources wired to remote sensors. Over the past 20 years, digital electronics have shrunk to a small fraction of their former size and cost, have been integrated directly into the sensor or actuator, and have expanded in function to include quite general processing, storage, and communication capabilities. The
_______________
1In settings in which the transducer is physically and logically distinct from the enclosing system, typified by the Highway Addressable Remote Transducer (HART) for process control and Building Automation and Control Networks (BACnet) for building automation, readings are obtained over a standardized protocol, but their interpretation remains entirely determined by the context, placement, and role of the device in the larger process. The use of the information produced by the physical measurement, and hence its semantics, are contained within the enclosing system.
configurable, self-contained nature of modern instrumentation reduces the costs of deployment and enables broader use.
• Information-rich operation. The primary control loop of operational processes (typically represented in manufacturing as plant-sensor-controller-actuator-plant) is usually augmented with substantial secondary instrumentation to permit optimization. For example, in refinery process control, such additional instrumentation streams help to tune controllers to increase yield or reduce harmful by-products. In semiconductor manufacturing, they are employed in conjunction with smallscale process perturbation and large-scale statistical analysis in order to shorten the learning curve and reach a final configuration more quickly. In environmental conditioning for buildings, multiple sensing points are aggregated into zone controllers. Automotive instruments are fused to present real-time mileage information to the driver.
• Cross-system integration. Measurements designed for one system are increasingly being exploited to improve the quality or performance of others. For example, light and motion sensors are installed to modulate the amount of artificially supplied lighting in many “green buildings.” But those motion detectors are then also available to serve as occupancy indicators in sophisticated heating, ventilation, and air conditioning (HVAC) controls. Rather than simply isolating indoor climate from external factors, modern design practice may seek to exploit passive ventilation, heating, and cooling; to do so requires the instrumentation of building configuration (such as open and closed window and door states) and of external and internal environmental properties (temperature, humidity, wind speed, etc.). All of these sources of information may also be exploited for longitudinal analysis, to drive recommissioning, retrofitting, and refining operations. Interval utility meter readings are used not just for time-of-use pricing but also to guide energy-efficiency measures. Traffic measurements and contentcondition instrumentation are applied to optimize logistics operations.
The factors described above have changed the role of instrumentation and measurement from a subsidiary element of the system design process to an integrative, largely independent process of design and provisioning of physical information services. For many sustainability challenges, methodologies are needed that can start with an initial model that is based on modest amounts of data collected during the design process; those methodologies would then include the development of an incremental plan for deploying sensors that progressively improves the model and exploits the improvements to achieve the goals of the system. In many sustainability applications, such as climate modeling and building modeling, the most effective approach may involve combining mechanistic
modeling with data-driven modeling. In these applications, mechanistic models can capture (approximately) the main behaviors of the system, which can then be refined by data-driven modeling. Classically, models may be developed from first principles based on the behavior laws of the system of interest, given sufficiently complete knowledge of the design and implementation of the system. Such approaches are reflected not just in the instrumentation plan, but in simulation tools and analysis techniques. However, for most aspects of sustainability, the system may not be rigorously defined or carefully engineered to operate under a narrow set of well-defined behaviors. Examples include watersheds, forests, fisheries, transportation networks, power networks, and cities. New technical opportunities for addressing the challenges presented by such systems as well as opportunities in instrumentation and measurement are emerging, several of which are discussed below.
Coping with Self-Defining Physical Information
Rather than simply drawing its semantics and interpretation from its embedding in a particular system, each physical information service could be used for a variety of purposes outside the context of a particular system and hence should have an unambiguous meaning. The most basic part of this problem is the conversion from readings to physical units and the associated calibration coefficients and correction function.2 The much more significant part of the problem is capturing the context of the observation that determines its meaning.3 For example, in a building environment, supply air, return air, chilled water supply, chilled water return, outside air, mixing valve inputs, economizer points, zone set point, guard band, compressor oil, and refrigerated measurement all have physical units of temperature, but these measurements all have completely
_______________
2These aspects have been examined and partially solved over the years with electronic data sheets, such as the IEEE [Institute of Electrical and Electronics Engineers] P1451 family, ISA [Instrumentation Systems and Automation Society] 104 Electronic Device Description Language, or Open Geospatial Consortium Sensor Model Language (SensorML). However, many variations exist within distinct industrial segments and scientific disciplines; the standards tend to be very complex, and adoption is far from universal.
3One example of this problem is a stream-water temperature sensor that is normally submerged but under low-water conditions becomes an air-temperature sensor instead. How should this contextual change in semantics be captured? One possibility might be a subsequent data-cleaning step that determines in what “mode” the sensor-context combination was (in this case, perhaps by using a stream- flow sensor or by correlating with a nearby airtemperature sensor). Another example is a soil-moisture sensor whose accuracy can increase with time when more is known about the soil composition—the parameterized equations used by the sensors can be tuned to the soil-type details.
different meanings. The same applies to the collection of measurements across many scientific experiments. Typically, contextual factors are captured on an ad hoc basis in naming conventions for the sense points, the presentation screens for operations consoles, or the labels in data-analysis reports.
The straightforward application of known techniques can be employed to collect the diverse instrumentation sources and deposit readings into a database for a specific setting or experiment. Similarly, electronic records can be made of the contextual information to permit an analysis of the data. The collection, storage, and query-processing infrastructure can be made to scale arbitrarily; processes can be run to validate data integrity and to ensure availability; and visualization tools can be introduced to guide various stakeholders.
To provide these capabilities in general rather than as a result of a design and engineering process for each specific domain or setting, however, requires either significant innovation in the techniques deployed or the development of new techniques. There are, for instance, welldeveloped techniques for defining the meaning, context, and interpretation of information directly affected by human actions, where these aspects are inherently related to the generation process.4 To cope with many large-scale sustainability challenges, similar capabilities need to be developed for physical or non-human-generated information.
Closely related to this definitional problem is the family of problems related to registration, lookup, classification, and taxonomy, much as for human-generated information, as one moves from physical documents to interconnected electronic representations. When an application or system is to be constructed on the basis of a certain body of physical information, how is the set of information services discovered? How are they named? If such information is to be stored and retrieved, how should it be classified? If physical information is to be accessed through means outside such classifications, how is it to be searched? Keyword search can potentially apply to the metadata that capture context, type, and role, but what about features of the data stream itself?
Today one addresses these problems by implicitly relying on the enclosing system for which the instrumentation is collected. As physical information is applied more generally, it becomes necessary to represent the model of the enclosing system explicitly if it is to be used to
_______________
4For example, the inventory of products in a retail outlet is quite diverse, but schemas are in place to capture the taxonomy of possible items, locations in the supply chain or in the store, prices, suppliers, and other information. Actions of ordering, shipping, stocking, selling, and so on cause specific changes to be made in the inventory database.
give meaning to the physical instrumentation. However, general model description languages and the like are still in their infancy.
The Design and Capacity Planning of Physical Information Services
Once the physical deployment of the instrumentation capability is decoupled from the design and implementation of the enclosing system, many new research questions arise. Each consumer of physical information may require that information at different timescales and levels of resolution. Furthermore, the necessary level of resolution can change dynamically depending on the purpose of the measurements. In principle, one could measure everything at the finest possible resolution, but this is rarely practical because of limitations in power consumption, local memory, processing capacity, and network bandwidth. What is needed for many sustainability-related challenges is a distributed system by which information needs can be routed to relevant sensors—for the purposes of this discussion, comparatively high bandwidth sensors are meant—and those sensors can then modulate their sampling rates and resolution as necessary.5
Recent advances in compressed sensing (to help conserve bandwidth and power) and network coding (to take advantage of network topologies for increasing throughput) add to the complexity of such a distributed system. One can imagine tools that take as input a collection of information consumers, a set of available sensors, and an understood network topology and produce as output a set of sensing and routing procedures that incorporate compressed sensing and network coding. However, this perspective assumes that the locations of the sensors and the network topology are already known. In virtually all practical situations, determining the number, location, and capabilities of individual sensors is an important design step. To support these design decisions, algorithms are needed for sensor placement and sizing. These algorithms require models of the phenomena being measured and of the information needs of each consumer. How will such models be provided and in what representation?
As mentioned above, system architecture has traditionally been organized as a cycle: plant-sensor-controller-actuator-plant. In this model, sensor readings are centralized and aggregated to produce an estimate of the
_______________
5Consider, for example, a thermometer in a freshwater stream. For purposes of hydrological analysis, it might suffice to measure only the daily maximum and minimum temperatures and report them once per week. But suppose that one seeks to detect sudden temperature changes that might indicate the dumping of industrial wastewater. Then the thermometer may need to measure and report temperatures at 15-second intervals.
state of the plant. The controller then determines the appropriate control decisions, which are transmitted to the actuators. However, as the “plant” becomes a large, spatially distributed system (e.g., a city, a power grid, an ecosystem) and the volume of data becomes overwhelming, it is no longer feasible to integrate centrally the state estimation and decision making. A recent International Data Corporation study6 suggests that there will be more than 35 zettabytes of data stored in 2020. Distributed algorithms are needed that can push as much computation and decision making as possible out to the sensors and actuators so that a smaller amount of data needs to be moved and stored. At the same time, these algorithms will need to avoid losing the advantages of data integration (reduction of uncertainty and improved forecasting and decision making).
Finally, tools are needed to support the planning and design process. These tools need to provide the designer with feedback on such things as the marginal benefit of additional sensing and additional network links, the robustness of the design to future information needs, and so forth. In summary, all aspects of capacity planning present in highly engineered systems, such as data centers and massive Internet services, arise in the context of the physical information service infrastructure.
Software Stacks for Physical Infrastructures
Potential solutions to the problems delineated above suggest that sophisticated model-driven predictive control and integrated cross-system optimization will become commonplace rather than rare. As discussed in Chapter 1, on the electric grid today, the independent service operator attempts to predict future demand and to schedule supply and transmission resources to meet it, with possibly coarse-grained time-of-use rates or, in rare cases, critical peak notification to influence the demand shape. In the future, environmental control systems for buildings may be able to adapt to the availability of non-dispatchable renewable supplies on the grid, using the thermal storage inherent in a building to “green” the electricity blend and ease the demand profile. Distributed generation and storage may become more common in such a cooperative grid. Various analysis, forecasting, and planning algorithms may operate over the physical information and human-generated information associated with the grid, the building, the retail facility, the manufacturing plant. It becomes important to ask what the execution environment is for such control algorithms and analytical applications. What are the convenient abstractions
_______________
6International Data Corporation, “The 2011 Digital Universe Study: Extracting Value from Chaos” (June 2011), available at http://www.emc.com/collateral/demos/microsites/emcdigital-universe-2011/index.htm.
of physical resources that ease the development of such algorithms, and how is access to shared-resource protected and managed? In effect, what is the operating system of the building, of the grid, of the plant, of the fleet, of the watershed? Today these operating systems are rudimentary and consist of ad hoc ensembles of mostly proprietary enterprise resource planning systems, building management systems, databases, communication structures, operations manuals, and manual procedures. An important challenge for computer science research is to develop the systems and design tools that can support effective and flexible management of these complex systems.
Sustainability problems raise many research questions for information-intensive systems because of the nature of the data sources and the sheer amount of data that will be generated.7 Computer science has applied itself broadly to problems related to discrete forms of humangenerated information, including transaction processing, communications, design simulation, scheduling, logistics tracking and optimization, document analysis, financial modeling, and social network structure. Many of these processes result in vast bodies of information, not just from explicit data entry but through implicit information collection as goods and services move through various aspects of the supply chain or as a result of analyses performed on such underlying data. The proliferation of mobile computing devices adds not just new quantities of data, but new kinds of data as well. Some data-intensive processes are extremely high bandwidth event streams, such as clickstreams from millions of web users. In addition, computer science is widely applied to discretized forms of continuous processes, including computational science simulation and modeling, multimedia, and human-computer interfaces. In both regimes, substantial data mining, inference, and machine learning are employed to extract specific insights from a vast body of often low-grade, partially related information.
All of the techniques described above can and must be applied to problems associated with sustainability. Nonetheless, several aspects of sustainability, even in addition to the vast quantities of data that will
_______________
7Given the vast amounts of data expected to be generated in the near future, traditional approaches to managing such amounts of data will not themselves be sustainable. Bandwidth will become a significant barrier, meaning that approaches to computation (such as moving computational resources to the data, or computing on data in real time and then discarding them, or other new techniques), different from simply storing the data and computing on them when necessary, will need to become more widespread.
have to be managed, demand greater innovation, or even wholly new techniques, particularly as ever more unstructured data are generated. To a large extent, these challenges arise from the need to understand and manage complex systems as they exist rather than to engineer systems for a particular behavior.
Notions regarding the coming wave of “big data”—the vast amounts of structured and unstructured data created every day, growing larger than traditional tools can cope with—and how science in general must cope with it were articulated in The Fourth Paradigm: Data-Intensive Scientific Discovery,8 which posits an emerging scientific approach, driven by data-intensive problems, as the evolutionary step beyond empiricism, analyses, and simulation. Useful data sets of large size or complicated structure exceed today’s capacity to search, validate, analyze, visualize, synthesize, store, and curate the information. The complexity of the transformations that must be applied to render some kinds of observations useful to the scientist or decision maker makes better infrastructure imperative. It is necessary so that one can build on the work of others and so that the population of those with useful insight can expand as data products of successively higher levels of integration and synthesis are constructed.
Unfortunately, there is a growing disparity between available software tools and the ability to leverage those on the scale referred to above. Solutions to many complex systems do not parallelize well, and new tools, algorithms, and likely hybrid systems will be needed. Computer science research is needed to go beyond the embarrassingly parallel problems and to find new approaches, methods, and algorithms for solving these problems. More parallel programming tools, methods, and algorithms are needed to leverage these large-scale systems.9 Progress in CS is needed in order to move from descriptive views of data (reporting on “What happened, where, how many?”) to more predictive views (“What could happen, what will happen next if …?”), and finally to more prescriptive
_______________
8Tony Hey, S. Tansley, and K. Tolle (eds.), The Fourth Paradigm: Data-Intensive Scientific Discovery, Seattle, Wash.: Microsoft Research (2009).
9A 2011 report from the National Research Council elaborates on the challenge of and increasingly urgent need for significant advances in parallel programming methods that are coupled with advances up and down the traditional computing stack—from architecture to applications: National Research Council, The Future of Computing Performance: Game Over or Next Level?, Washington, D.C.: The National Academies Press (2011).
approaches (“How can the best outcomes be achieved in the face of variability and uncertainty?”).
In order to handle big data, new approaches or improvements will be required in data mining, including clustering, neural networks, anomaly detection, and so on. For example, the smart grid will grow in terms of complexity and uncertainty, especially as renewables are made a more significant element of the energy mix. This increasing complexity will create an increasingly complex system of equations that will need to be solved on a shrinking timescale in order to create secure and dispatchable energy over larger geographies. This challenge implies a need for improvements in computational capabilities to cope with problems ranging from relatively simple N 1 contingency analysis, to N x, to an ability to parallelize the solution to very large systems of sparsely populated matrices and equations that run on high-performance computing systems. In addition, appropriate semantic layers will be needed to bridge the various data sources with a common vocabulary and language, in such a way as to make them more universally applicable.
Because sustainability problems involve complex systems, the data relevant to those systems are typically very heterogeneous. Challenges lie not just with huge quantities of data, but stem also from the heterogeneity of their structure and the number of data sets often needed to study a topic. In the management of ecosystems (fisheries, forests, freshwater systems), relevant data sources range from detailed ground-based measurements (catch-and-release surveys, tree core data), to transactional data (fish harvest, timber sales), to hyperspectral and lidar data collected by aircraft and satellites. As discussed above, data for smart buildings include not only energy-consumption and outdoor-weather data, but also data on room occupancy, the state of doors and windows (open or closed), thermostat settings, air flows, HVAC operational parameters, building structure and materials, and so on. Dealing with such diverse forms of information arises, to a lesser degree, in multimodal multiphysics simulations, which typically stitch together multiple major simulation capabilities using specialized adapters and a deep understanding of the algorithms employed in each subsystem. Similar situations arise in data fusion problems and large-scale logistics, such as air-traffic control. But such management of vastly heterogeneous information and processing is typically done on a domain-specific basis. New techniques will be required to do so systematically—say, with transformation and coordination languages to orchestrate the process, or automatic transformation
and coordination derived from declarative description of the constituent data and processes.
In some cases, “citizen science” data—such as those provided by bird-watchers (project eBird10), gardeners (project BudBurst11), and individuals who participate in sport fishing and hunting—may be the only available data about particular regions or events. Heterogeneity extends as well to the provenance, ownership, and control of the data. These data are typically not under the control of a single organization. Access (either one-time-only or ongoing) must be negotiated, and there are important security, privacy, and proprietary data issues. Such authorization and access are generally not transitive, and so new techniques must be developed to manage information flow as information services are composed out of other services.
Coping with the Need for Data Proxies
A persistent challenge in sustainability is the meaningful translation of physical, biological, or social variables into an electric signal. More generally, the data of use with respect to sustainability often do not directly measure the quantities of interest, but instead are surrogates. For example, occupancy in a building may be derived from motion detection, infrared signatures, appliance usage, acoustics, imaging, vibration, disruptions, or other factors, but to varying degrees these may provide only a noisy indication of room occupancy. Ecology focuses on the interactions among organisms (e.g., mating, hatching, predation, infection, defense), but these interactions are virtually never observed directly. An animal (or a disease) may be present in an ecosystem and yet fail to be detected by observations or instruments. Weather radar can detect the movement of birds but not the species or the full direction of motion. Over-the-counter drug sales and web queries can be proxies for the prevalence of flu. As another example, measuring snow-water equivalent is normally estimated by sensor pressure at the snow-soil interface. However, snow is not a fluid and thus may bridge over a sensor. Other challenges arise from the sensors, which themselves may affect the thing needing to be measured. This may not be chiefly an IT problem, but it creates barriers to useful data creation.
Supervised and unsupervised machine learning techniques, as well as those used for gesture recognition, intrusion detection, and preference characterization, may be applied to infer quantities of interest from
_______________
available surrogates, but the scale and fidelity needed to make substantial headway on sustainability problems require significant transformations of these techniques. Moreover, as these quantities would feed into an extensive process of modeling and automated decision making rather than providing a one-time suggested action, it would be necessary to propagate the uncertainty quantification along with such derived metrics (see below the section “Decision Making Under Uncertainty”).
Coping with Biased, Noisy Data
Many data sources are biased (in a statistical sense) and noisy. For example, weather and radar data are collected at special locations (e.g., airports) that were likely chosen to reflect the primary purpose of the data, which may be far from ideal for assessing other topics of interesting, such as climate effects. Carbon- flux towers are usually deployed in flat areas where the models that guide instrument interpretation are well understood, but not necessarily representative of important topography. Many citizen scientists make their observations near their place of residence, rather than by following a carefully designed spatiotemporal sampling plan.
Data from sensors can be very noisy. Indeed, the sensor network revolution aims to transition from deploying a small number of expensive, highly accurate sensors to much larger numbers of inexpensive (and less reliable) ones. Moreover, sustainability problems often involve the analysis of longitudinal data (e.g., historical weather records, historical power consumption, historical carbon dioxide concentrations) that have been produced by multiple technical generations of sensors and data-collection protocols. Hence, the data are not of uniform quality. Each new generation of sensor and each change in the protocol may affect the biases and noise properties of the data.
As one significant example, many aspects of climate change center on the increase in global surface temperature. Although there is now broad scientific consensus that human activity is a significant contributor to global climate change, there is much continuing debate about the exact nature of the phenomenon and (more importantly) about the prognosis for the future. Regarding the global surface temperature in particular, Earth’s temperature is a very complex phenomenon that varies widely over the surface at any point in time and varies in complex ways over time. There has been assembled over the past hundred years a data set of over 1.6 billion temperature readings at various points over land and seas, using various instruments, by various methodologies, at over 39,000
unique stations.12 Significant algorithmic work must take place in order to allow the development of a meaningful temperature reconstruction from this complex, noisy, incomplete data set.
Most existing machine learning and data-mining tools make assumptions that are not valid for these kinds of data. They assume that the data are collected at a single temporal and spatial resolution; methods are needed that can work with heterogeneous data. Existing machine learning and predictive data-mining tools typically were designed under the assumption that the data directly measure the desired input-output relationship rather than measuring surrogates. Finally, existing methods assume that the data can be cleaned and rationalized so as to remove noise, impute missing values, and convert multigeneration and multisource data into a common format. However, this process tends to be manual and carried out relative to a particular study of interest by individuals highly trained in the area of study. Even so, it tends to result in a least-common-denominator data set in which numerical, spatial, and temporal resolution are all set to the coarsest level observed in the data. This process may fail to address the different sampling biases and error properties of different data sources, and hence it has the potential to introduce errors into the data.
A fundamental computer science challenge is to automate this cleaning and rationalization process as much as possible and to make it systematic, able to scale to vast streams of continuous data, and able to retain the full information content. A related challenge is to provide tools that support the visual detection of data anomalies and, once an anomaly is found, fast methods for finding and repairing all similar anomalies. An analyst would like to ask, “Are there other data that look like this plot?” and obtain useful answers despite variations in underlying sampling rate, fidelity, and format.
Coping with Multisource Data Streams
Most early machine learning and predictive data-mining tools were designed for the analysis of a single data set under the assumption that the data directly measure the desired input-output relationship; the goal was to learn a mapping from inputs to outputs. Increasingly these techniques
_______________
12The Goddard Institute for Space Studies (GISS) maintains a record of global surface temperatures as well as information on their analysis and on GISS publications, which is available at http://data.giss.nasa.gov/gistemp/. See also National Research Council, Surface Temperature Reconstructions for the Last 2,000 Years, Washington, D.C.: The National Academies Press (2006), according to which historical temperature measurements go back to about 1850, and proxy temperature measurements go back millions of years but are most prevalent for the past two millennia.
are applied in real-time settings, such as in massive Internet services both for the adaptive optimization of the complex distributed system providing the service and in adapting the service to optimize the user experience, the profit derived, and so on. One path for CS research in dealing with the reality of noisy, multigeneration, multisource data streams is to develop machine learning and data-mining algorithms that explicitly model the measurement process, including its biases, noise, resolution, and so on, in order to capture the true phenomenon of interest, which is not directly observed. Such methods should treat the data in their original, raw form so that they can capture and take account of different properties of each generation of instrumentation. In some cases, it is possible to focus on empirical model development by applying unsupervised learning methods to extract relationships between inputs and outputs without establishing a specific physical interpretation of the input values. This way of proceeding can sometimes provide insight without the need to isolate the bias, eliminate noise, and calibrate readings.
The field of statistics has studied latent variable models, such as that described in Box 2.1, in which the phenomenon of interest is modeled by one or more latent (hidden) variables (e.g., Zs). However, existing statistical methods rely on making strong parametric assumptions about the probability distributions governing the latent variables. An important research challenge is to transform these statistical methods into the kinds of flexible, non-parametric methods that have been developed in computer science (support vector machines, ensembles of tree models, and so on).13 Such a transformation should also result in methodologies that are easy to apply by non-statisticians and non-computer-scientists.
The use of these techniques may in some circumstances sharpen the tension between information quality and privacy. If the raw data have been obfuscated to enhance privacy, the latent variable model will seek to undo this and infer the un-obfuscated form. When is it appropriate to do this? Are there effective and broadly applicable ways to preserve privacy and proprietary rights while still applying these methods?
A further challenge raised by these problems is how to validate hidden-variable models. Traditional statistical methods rely on goodness of fit of a highly restricted parametric model; modern machine learning methods rely on having separate holdout data to test the model. Neither of these approaches will work here—at least not in their standard form. One promising direction is to develop simulation methodologies to evaluate the identifiability of the model; another is to develop methods for
_______________
13R.A. Hutchinson, L.P. Liu, and T.G. Dietterich, Incorporating boosted regression trees into ecological latent variable models, Twenty-Fifth AAAI Conference on Artificial Intelligence, pp. 1343-1348 (2011).
BOX 2.1
Understanding the Gap Between Observation and Truth
The reality of noisy, multigeneration, multisource data streams requires new machine learning and data-mining algorithms that explicitly model the measurement process, including its biases, noise, and resolution, and so on, in order to capture the true phenomenon of interest, which is not directly observed.1 Such methods should treat the data in their original, raw form so that they can capture and take account of different properties of each generation of instrumentation.
In general, there is a gap between observation and underlying truth. In a basic sense, this gap exists whenever a transducer is used to measure a phenomenon—in addition to the mapping from input stimulus to output reading, there is a question of how the transducer is coupled to the underlying phenomenon generating the stimulus. How is the accelerometer bonded to the vibrating beam? How does the soil-moisture sensor disturb the hydrological behavior of the surrounding soil? A phenomenological gap may exist regardless of the precision of the sensor.
For example, consider the case of an observer conducting a biodiversity survey. The observer visits a site and fills out a checklist of all of the species observed. The resulting data provide a record of detections rather than a record of the true presence or absence of the species. The latter can be captured by an occupancy/ detection model,2 as shown in Figure 2.1.1.
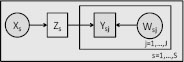
FIGURE 2.1.1 Probabilistic graphical model representation of the occupancy/detection model. Observed variables are shaded; S is the number of sites; J is the number of visits to each site. An observer visits site s at time j and reports Ysj = 1 if the species is detected and 0 if not. The hidden variable Zs = 1 if the species is present at site s and 0 otherwise. Xs is a vector of attributes of the site, and the X→Z relationship predicts whether, based on these attributes, the species will be present. This is the occupancy model that is of primary interest. Wsj is a vector of attributes that influence detectability (e.g., the level of expertise of the observer, the density of the foliage, the weather, how much time the observer spent, etc.). The Z→Y←W relationship represents the detection model, which predicts the probability that the species will be detected given that it is actually present (and the probability that it will be falsely reported, given that it is actually absent).
_______________
1S.K. Thompson and G.A.F. Seber, Adaptive Sampling, Washington, D.C.: Wiley Interscience (1996) offers researchers in fields ranging from biology to ecology to public health an introduction to adaptive sampling.
2D.I. MacKenzie, J.D. Nichols, J.A. Royle, K.H. Pollock, J.E. Hines, and L.L. Bailey, Occupancy Estimation and Modeling: Inferring Patterns and Dynamics of Species Occurrence, San Diego, Calif.: Elsevier (2005).
In settings in which the observation process can be designed in advance, optimal methods exist for determining the spatial layout of sites and the number of visits to each site.3 When the data are collected by an uncontrolled observation process (e.g., by citizen scientists) or when the underlying process is poorly understood, more flexible machine learning methods are needed.
_______________
3S.K. Thompson and G.A.F. Seber, Adaptive Sampling, Washington, D.C.: Wiley Interscience (1996).
visualization that permit the inspection and manipulation of the various components of the model.
Although hidden-variable models can address the challenges of multiple generations of sensors and heterogeneous data sources, they do not solve the problem of biases in sampling. There is a need for new methods that can explicitly capture the differences between the spatiotemporal distribution of the sampling process and the desired spatiotemporal distribution of the model.14
An additional challenge is to make all of these methods fast enough for interactive use. Current practice in machine learning modeling harkens back to the days of batch processing. Each iteration of model development and evaluation takes several days, because the data are so voluminous that the management tools, algorithms, and visualization methods require several hours to run. Data volumes will continue to explode as the number of deployed sensors multiplies. Can CS researchers develop integrated data-mining and visualization systems that can support interactive model iteration? Such systems would produce a qualitative change in the sophistication of the models that can be applied and the thoroughness with which they can be evaluated.15
_______________
14One promising direction is to build on recent advances in covariate shift methods. See J. Quiñonero-Candela, M. Sugiyama, A. Schwaighofer, and N.D. Lawrence (eds.), Data Shift in Machine Learning, Cambridge, Mass.: MIT Press (2009). There is also a growing literature in handling preferential sampling for modeling geostatistical processes: see, for example, P.J. Diggle, R. Menezes, and T. Su, Geostatistical inference under preferential sampling, Journal of the Royal Statistical Society, Series C, 59(2) (March 2010).
15Such integrated data-mining and interactive model iteration will be critical to transforming the electric grid. M. Ilic, Dynamic monitoring and decision systems for enabling sustainable energy services, Proceedings of the IEEE, Vol. 99, pp. 58-79 (2011), offers a possible framework in which distributed models evolve as more information becomes available and
ANALYSIS, MODELING, SIMULATION, AND OPTIMIZATION
One key role of computer science in sustainability is to provide technology for model development. Models permit the extraction of meaningful information from context-dependent, potentially noisy measurements and observations of complex, at best partially engineered, systems in the physical world. Models allow the many interrelated aspects to be decomposed into facets so that progress can be made in a somewhat incremental fashion. Models provide a frame of reference for the many distinct but interrelated streams of information. Computational resources and CS techniques can be brought to bear in several ways: to refine the grid size and time step, to improve the model’s representation of processes (making it more complex), and to run the model over multiple scenarios (varying the time period, input values, and so on). This section discusses three interrelated topics: multiscale models, the combining of mechanistic and statistical models, and optimization under uncertainty.
Developing and Using Multiscale Models
Multiscale models, the first of the three interrelated topics, represent processes at multiple temporal and spatial scales. For example, a biological population model might include the agent-level modeling of each organism within a landscape, coupled with the flock-level modeling of group behavior at a regional scale, and population-level modeling at a continental scale. Forest fire models could include models of individual tree growth and burning, coupled with the stand-level and landscapelevel modeling of fuel load, coupled with regional models of fire ignition and weather. Global multiscale weather models can operate at low resolution over the entire planet but with higher resolution over regions of interest (e.g., for forecasting hurricanes). In a sense, most sustainability problems arise because behavior at one scale (e.g., energy use in automobiles, land use along migration flyways) affects phenomena at very different scales (e.g., global climate change, species extinctions), and those larger-scale phenomena then enter a feedback cycle affecting activities at lesser scales. Multiscale models are important for understanding these sorts of problems.
the complexity of the interactions among layers is minimized. The complexity of decision making is internalized to the (groups of) system users instead of burdening the system operator with overwhelming complexity. Iterative learning through binding technical and/ or economic information exchange is implemented for learning the interdependencies and aligning them with the objectives of the system as a whole. Significant effort is needed to make such frameworks and system designs more concrete.
One standard approach seeks to capture all phenomena by modeling only at the finest scale in space and time. However, there are both computational and information-theoretic reasons why this approach often fails. Computationally, fine-scale models are extremely expensive to run; multiscale methods allow computational savings while still providing fine-scale predictions. From the perspective of information, large-scale emergent phenomena may not be well modeled by aggregating fine-scale models. Small errors at the fine scale may lead to large errors at larger scales. With limited data available to calibrate fine-scale models (clouds, land surface, human dimensions, etc.), it may not be possible to get a good fit to larger-scale phenomena (global or regional climate change). Hence, it is often preferable, both for computational and representational reasons, to model systems at multiple scales while coupling the models so that they influence one another.
Homogeneous multiscale models, such as models based on Fourier or wavelet analysis and models that employ adaptive grid sizes (e.g., multiscale meteorology models), are reasonably well understood. However, heterogeneous multiscale models, in which models at different scales employ very different representation and modeling methods, are not as well studied. Methods of upscaling, that is, summarizing fine-scale information at coarser scale (e.g., “parameterizations” in climate models), and methods of downscaling, that is, extending coarse-scale models with fine-scale information, have only recently been developed and still require much additional research. Among the questions to be addressed are these: What is the design space of upscaling and downscaling methods? Are there best practices? Can these be encapsulated in general-purpose modeling packages (e.g., as middleware services)? To the extent that upscaling is primarily performed for computational reasons, can it be automated? How do upscaling and downscaling interact with parallel implementations of the models? In addition, how should mismatches in scale (e.g., mismatches in temporal scale in areas such as coupled ocean-atmospheric models) best be handled?
Combining Statistical and Mechanistic Models
The second of three interrelated modeling challenges is that of combining statistical and mechanistic models. (The former are empirical and the latter are derived from first principles.) In many sustainability settings, some aspects of the problem can be captured by mechanistic models—for example, of physics, chemistry, and so on. However, often it is not tractable to construct models with sufficient fidelity to capture the aspects of the phenomena of interest. For example, consider managing the heating, ventilation, and air conditioning of an office building. Mechanistic models
of air ow and heat transport can provide a good first approximation of how a building will behave under different HVAC configurations. However, in actual operation, the outdoor environmental conditions, status of doors and windows (open or closed), position of furnishings, installation of other equipment (e.g., space heaters, digital projectors, vending machines), and number and behavior of occupants can produce very different operational behaviors. Introducing all of these secondary and tertiary factors into a mechanistic model may be very demanding; these factors are typically in flux. Alternatively, as more sensors are incorporated into building environments there may be enough data to fit a statistical model of building behavior—that is, to develop an empirical model. However, such statistical models must in effect rediscover aspects of the physics in the mechanistic models, and this can require an immense amount of data. An attractive alternative is to integrate one or more datadriven modeling components with the mechanistic model. A mechanistic model would be modified by inserting statistically trained components with the goal of these components being to transform the inputs (initial state and forcings), dynamics, and outputs so that the model produces more accurate predictions.
Virtually all existing work on the integrating of statistical models into mechanistic models has taken place outside of computer science. A key challenge is to bring these methods into computer science and generalize and analyze them. Among the research questions are the following: What general-purpose algorithms work well for fitting the statistical components of an integrated model? How can overfitting be detected and prevented (i.e., what are appropriate regularization penalties for such integrated models)? What are good methodologies for evaluating the predictive accuracy of such models? Many algorithms for evaluating mechanistic models employ adaptive meshes; how can statistical methods be integrated with mesh adaptation? The fitting of statistical models typically requires evaluating the mechanistic model hundreds or thousands of times. Running global climate models even once at full resolution can require many days of time on the world’s largest supercomputers. Can experimental designs that make efficient use of and minimize expensive model runs be implemented? Can the statistical models be fitted on upscaled versions of the mechanistic models and then downscaled for full-resolution runs? Under what conditions would this work?
Decision Making Under Uncertainty
Actually addressing sustainability problems requires that one move beyond observation and analysis to action. But there is inherent uncertainty every step of the way—in the decision making informed by modeling
and simulation, in the measurements, in the modeling and simulation itself, and possibly in the basic characterizations of the factors that comprise the system. In terms of science-based decision making, a central challenge is thus the making of (optimal or at least good) decisions under uncertainty. There are many sources of uncertainty that must be taken into account. First, the scientific understanding of many systems is far from complete, and so many aspects of these systems are unknown. Second, even for those aspects for which good mechanistic models exist, the data needed to specify the boundary conditions with sufficient accuracy are often lacking, especially when human decisions and activity need to be included. Third, the lack of data and the computational cost of running the models often require a coarsening of the scale and the introduction of other approximations. Finally, today’s sustainability risks are time-critical, and so just waiting for additional scientific and engineering research in order to address these uncertainties is not an option. Action must be taken even as research continues. Therefore, the choice of actions should also take into account the fact that scientific understanding (and computing power) is expected to improve over time, and future decisions can be made with a better scientific basis.
In effect, uncertainty must be treated as a quantity that persists and is accounted for at every stage. It is a product of measurement, data collection, and modeling, along with the data themselves. It is both an input and an output of the analysis, modeling, and simulation efforts. And finally, decisions must be made based not just on expected outcomes, but also on the uncertainty associated with the various alternatives.16 There are three areas that pose interesting research challenges for computer science with respect to uncertainty: assessment, representation, and propagation of uncertainty; robust-optimization methods; and models of sequential decision making.
Assessment, Representation, and Propagation of Uncertainty
Many models employed in global climate change, natural resource management, and ecological science are deterministic mechanistic models
_______________
16Regarding the challenge of the propagation of uncertainties and, nevertheless, how best to use models to help decision making, a paired set of papers on the climate sensitivity problem appeared in 2007 in Science: one was a research article and the other a perspective (G.H. Roe and M.B. Baker, Why is climate sensitivity so unpredictable? Science 318(5850):629632 [2007]; M.R. Allen and D.J. Frame, Call off the quest, Science 318(5850):582-583 [2007]). Their main point, in the general context, is that decision making based on models of future scenarios must be adaptive. Another point is that estimating the distribution function of model uncertainty requires knowledge of the distributions of the input data.
that provide no measures of uncertainty. Recently, there has been substantial interest in assessing the uncertainty in these models. The primary method is to perform Monte Carlo runs in which the model parameters and inputs are varied in order to reflect uncertainty in their values, and the propagation characteristic of the uncertainty is reflected in the degree of variation in the outputs. Although valuable, this does not assess uncertainty due to model-formulation decisions and computational approximations. Research questions include the following: How can one minimize the cost of Monte Carlo uncertainty assessment? For example, can program-analysis methods determine that uncertainty in some sets of parameters interact in well-behaved ways (independently, additively, multiplicatively)? Can convenient and efficient tools be provided for authoring, debugging, and testing alternative modeling choices so that the uncertainty engendered by these choices can be assessed? Can existing tools for automated software diversity—which were developed for software testing and security17—be extended to generate model diversity?
Models are often part of a sensor-to-decision-making pipeline in which sensor measurements are cleaned and rationalized, then fed to a set of models that simulate the effects of different policy choices and assess their outcomes. However, it is often the case that uncertainty in one stage (e.g., data cleaning) is not retained and propagated to subsequent stages. Existing scientific workflow tools (e.g., Kepler18) do not provide explicit representations of uncertainty or standard ways of propagating uncertainty along such pipelines. Additional work is needed to develop such representations and to provide support for automating the end-to-end assessment of uncertainty. For example, it should be possible to automate end-to-end Monte Carlo uncertainty assessment. One can also imagine extending methods of belief propagation from probabilistic graphical modeling in order to propagate uncertainty along data-analysis pipelines automatically. Coupled with modules for representing policy alternatives and modules for computing objective functions, such workflow tools could provide important support for decision making under uncertainty.
Robust-Optimization Methods
The assessment of explicit uncertainty aims to address the “known unknowns.” Classical models of decision making typically involve selecting the actions that maximize the expected utility of the outcomes according
_______________
17For a review, see A. Gherbi, R. Charpentier, and M. Couture, Software diversity for future systems security, CrossTalk: The Journal of Defense Software Engineering 25(5):10-13 (2011).
18For more information on Kepler, see http://kepler-project.org/.
to some underlying statistical model. Unfortunately, experience with ecological modeling and environmental policy suggests that there are many “unknown unknowns”—phenomena that are unknown to the modelers and decision makers and therefore not accounted for in the models.19 One possible safeguard is robust optimization.20 Rather than treating model parameters as known, this approach assumes instead that the parameters lie within some uncertainty set and optimizes against the worst-case realization within these sets. The size of these uncertainty sets can be varied to measure the loss in the objective function that must be sustained in order to achieve a given degree of robustness. Robustoptimization approaches can greatly improve the ability to sustain significant departures from conditions in the nominal model. Existing robustoptimization methods generally assume that the decision model can be expressed as an optimization problem with a convex structure (e.g., linear or quadratic programs). Robust optimization is sometimes considered overly conservative. Convex constraints over multiple uncertainty sets can be introduced to rule out simultaneous extreme events and reduce the over-conservatism of first-generation robust-optimization methods.21 An open theoretical question is that of determining the best ways to use data in optimization problems. In some problems in which there are insufficient data, the question becomes one of how to properly incorporate subjective opinion about the data and what the best way is to characterize uncertainty. Another research challenge is to develop robust-optimization methods that are applicable to the kinds of complex nonlinear models that arise in sustainability applications.
Optimal Sequential Decision Making
Most sustainability challenges will not be addressed by a decision made at a single point in time. Instead, decisions must be made iteratively over a long time horizon since a system is not sustainable unless it can be operated indefinitely into the future. For example, in problems involving natural resource management, every year provides a decision-making opportunity. In fisheries, the annual allowable catch for each species must be determined. In forests, the location and method for tree harvesting
_______________
19D.F. Doak et al., Understanding and predicting ecological dynamics: Are major surprises inevitable? Ecology 89(4):952-961 (2008).
20A. Ben-Tal, L. El Ghaoui, and A. Nemirovski, Robust Optimization, Princeton, N.J.: Princeton University Press (2009).
21D. Bertsimas and A. Thiele, Robust and data-driven optimization: Modern decisionmaking under uncertainty, INFORMS Tutorials in Operations Research: Models, Methods, and Applications for Innovative Decision Making, pp. 1-39 (2006).
must be specified, as well as other actions such as mechanical thinning to reduce fire risk. In energy generation and distribution, the location of new generation facilities and transmission lines must be chosen. In managing global climate change, the amount of required reduction in greenhouse gas emissions each year must be determined. The state of the art for solving sequential decision problems is to formalize them as Markov decision problems and solve them by means of stochastic dynamic programming. However, an exact solution through these methods is only feasible for processes whose state space is relatively small (tens of thousands of states). Recently, approximate dynamic programming methods have been developed in the fields of machine learning and operations research.22 These methods typically employ linear function approximation methods to provide a compact representation of the quantities required for stochastic dynamic programming.
An important aspect of sustainability problems is that they often involve optimization over time and space. For example, consider the problem of designing biological reserves to protect threatened and endangered species and ecosystems. Many conflicting factors operate in this problem. Large, contiguous reserves tend to protect many species and preserve biodiversity. However, such reserves are also more vulnerable to spatially autocorrelated threats such as fire, disease, invasive species, and climate change. The optimal design may thus involve a collection of smaller reserves that lie along environmental gradients (elevation, precipitation, etc.). The purchase or preservation of land for reserves costs money, and so a good design should also minimize cost. Another factor is that reserves typically cannot be designed and purchased in a single year. Instead, money becomes available (through government budgets and private donations) and parcels are offered for sale over a period of many years. Finally, the scientific understanding and the effectiveness of previous land purchase decisions can be reassessed each year, and that should be taken into account when making decisions.
The solution of large spatiotemporal sequential decision problems such as those described above is far beyond the state of the art. Striking the right balance between complexity and accuracy, especially in the context of complex networked systems, is critical. New research is needed to develop methods that can capture the spatial structure of the state each year and the spatial transitions (e.g., fire, disease) that occur. There are sustainability problems in which all three of these factors—uncertainty, robustness, and sequential decision making—combine. For example, in
_______________
22W. Powell, Approximate Dynamic Programming: Solving the Curses of Dimensionality (2nd Ed.), New York, N.Y.: Wiley (2011).
reserve design, models of suitable habitat for threatened and endangered species are required. These are typically constructed by means of machine learning methods and hence are inherently uncertain. This uncertainty needs to be captured and incorporated into the sequential decision-making process. Finally, existing stochastic dynamic programming methods are designed to maximize expected utility. These methods need to be extended in order to apply robust-optimization methods. A research opportunity is to integrate the training of the machine learning models—which can itself be formulated as a robust-optimization problem—with the robust optimization of the sequential decision problem. This integration would allow the machine learning methods to tailor their predictive accuracy to those regions of time and space that are of greatest importance to the optimization process and could lead to large improvements in the quality of the resulting decisions.
Formulating problems in terms of sequential decision making can sometimes make the problems more tractable. For example, Roe and Baker23 show that structure inherent in the sensitivity of the climate system makes it extremely difficult to reduce the uncertainties in the estimates of global warming. However, by formulating the problem as a sequential decision-making problem, Allen and Frame24 show that it is possible to control global warming adaptively without ever precisely determining the level of climate sensitivity.
It is critical, for real-world applicability, to situate technology innovation and practice within the context-specific needs of the people benefiting from or otherwise affected by that technology. For example, in the context of introducing intelligence into the electric grid in order to increase sustainability, the essential measures and relevant information are very different when considered from the differing perspectives of the utility, supplier, and customer. The utility may be interested in introducing payment schedules that influence customer behavior in a manner that reduces the need to build plants that run for only a tiny fraction of the time (to serve just the diminishing tail of the demand curve). Avoiding such construction does reduce overall GHG emissions, but the primary goal is to avoid capital investment. Trimming the peak does little to reduce overall energy use, but it reduces the use of the most costly supplies. A consumer-centric perspective is likely to focus on overall energy savings
_______________
23G.H. Roe and M.B. Baker, Why is climate sensitivity so unpredictable? Science 318 (5850):629-632 (2007)
24M.R. Allen and D.J. Frame, Call off the quest,” Science 318(5850):582-583 (2007).
and efficiency measures, not just on critical-peak usage. Thus, greater emphasis may be placed on visualizing usage, understanding demand, reducing waste, curbing energy consumption and less important usage, and (if there is dynamic variable pricing) helping to move easily rescheduled uses (e.g., water heating) to off-peak times. A grid-centric perspective, by contrast, may focus on the matching of supply and demand, as well as on the utilization of the key bottlenecks in the transmission and distribution infrastructure. All of these stakeholders need to be considered, and ideally involved, to substantially increase the penetration limit of non-dispatchable renewable supplies, because of the need to match consumption to supply. And, all stakeholders have substantial needs for monitoring usage data, determining causal relationships between activities and usage, and managing those activities to optimize usage. In addition to the needs and values of these direct stakeholders in the technology, the indirect stakeholders should also be considered—that is, those who are affected by the technology but do not use it. In the smart grid example, the set of indirect stakeholders is broad indeed, since everyone is (for example) affected by climate change. The ability to understand such needs and to guide the development of technology on that basis constitutes a natural application of techniques developed in the area of human-computer interaction (HCI).
More generally, a human-centered approach can and should be integrated with each of the topics discussed above. Issues such as human-in-the-loop training of machine learning systems, the interpretability of model results, and the possible use (or abuse) of large volumes of sensed data become particularly salient with a human-centered viewpoint. Indeed, with the vast quantities of data to be generated and used as described earlier, privacy becomes a first-order concern. The role of computer science in sustainability is predicated on the ability to capture and analyze data at a scale without precedent. The understanding and mitigating of privacy implications constitute an area in which fundamental CS research can play a role—in both formalizing the questions in an appropriate way (and indeed this is research well underway) and potentially in providing solutions that can help mitigate the loss of privacy that is, to some extent, inherent in taking full advantage of the power of information-gathering at a global scale with high resolution. It is essential that a human-centered approach be integrated with more traditional security approaches: not only should the techniques for preserving privacy be technically sound, but they should also be accessible, understandable, and convincing to the users of these systems.
Historically, much of the research on sustainability in HCI has focused on individual change. Perhaps one of the best-recognized examples is eco-feedback
technology, which leverages persuasive interface techniques25 and focuses primarily on residential settings. Reduced individual use can socialize people to the issues at hand, and can, at scale, have a direct if limited effect on overall energy use.26 However, population growth alone may outstrip the gains realized by such approaches. In response, the committee notes the importance of significantly increased attention to social, institutional, governmental, and policy issues in addition to issues of individual change. A challenging public policy question, for example, is how to verify compliance with GHG emissions requirements. Reliably validated carbon reductions, for instance, are important not just to global progress; they would be also invaluable for guiding sustainability efforts at a macro level.27
This report emphasizes opportunities for research, in addition to the data and privacy challenges mentioned earlier, on human-centered systems both at the individual level and beyond (at the organizational and societal levels). Examples of such research areas include visualization and user-interaction design for comprehensibility, transparency, legitimation, deliberation, and participation; devices and dashboards for individuals and institutions; expanding the understanding of human behaviors, empowering people to measure, argue for, and change what is happening; and education. Following are brief discussions of each of these.
Supporting Deliberation, Civic Engagement, Education, and Community Action
As noted in Chapter 1, moving toward a more sustainable society will require massive cultural, social, political, and economic changes—and today’s technologies are deeply intertwined with many of these changes. Technology can help to support an informed and engaged citizenry. Currently, civic engagement is uneven at best, and thoughtful public deliberation about major issues is often challenging to accomplish. However, the ease of information access, the existence of community-based knowledge
_______________
25For example, see J. Froehlich, L. Findlater, and J. Landay, The design of eco-feedback technology, in Proceedings of the 28th International Conference on Human Factors in Computing Systems, New York, N.Y.: Association for Computing Machinery, pp. 1998-2008 (2010).
26For a provocative essay on this issue, see P. Dourish, Print This Paper, Kill a Tree: Environmental Sustainability as a Research Topic for HCI, LUCI-2009-004, Laboratory for Ubiquitous Computing and Interaction, University of California, Irvine (2009), and a related article: P. Dourish, HCI and environmental sustainability: The politics of design and the design of politics, in Proceedings of the 2010 ACM Conference on Designing Interactive Systems, Aarhus, Denmark, pp. 1-10 (2010).
27See National Research Council, Verifying Greenhouse Gas Emissions: Methods to Support International Climate Agreements, Washington, D.C.: The National Academies Press (2010).
repositories, and the search and social networking capabilities online are transforming the manner in which humans learn, make decisions, and interact. These techniques can be adapted for a research program on designing, deploying, and testing innovative ways for citizens to deliberate and to engage with government and one another, particularly with those who may hold very different views in the context of sustainability. These deliberations should be closely coupled to data (gathered both by professional scientists and citizen-scientists) and simulation results—affordances should be provided to help ground the discussion in the scientific evidence. Similarly, online curricula for students in kindergarten through grade 12 and for adults can explore, for instance, ongoing scientific and policy discussions related to sustainability; and educational initiatives can contribute to societal changes needed to meet sustainability goals.
In addition to opportunities with respect to tools for engaged citizens generally, there are also promising areas of research in helping scientists provide more effective input into these broader discussions and debates on sustainability and potential initiatives. The intellectual merit of this research would center on the issues of how to facilitate large-scale online deliberation about contentious issues; the broader impacts would be in making the results of scientific inquiry more widely seen and discussed. As an example, suppose that there was a network supporting online deliberation among scientists concerned with sustainability for developing key points, areas of strong consensus, areas of disagreement, and supporting evidence. Those deliberations would produce a sustainability action agenda that could be introduced to the public by means of interesting interactive environments designed to appeal to those of all ages. These sites could feed information by means of different media outlets (both traditional and emerging) as well as providing interactive scenarios that people could use to answer questions and debate solutions. One highlight of this system would be a series of consensus news stories, perhaps on a weekly basis. These stories could be based on agenda items created by scientists and rated by public interest.
A core component of such a public education system could be a forum for discussing scientific data, for voicing views on which stories to present and when, and for suggesting how to frame them (deliberative forums for the science community for building consensus positions). A key research issue here is the development of technologies that help organize the discussion, both for long-standing participants and for people who are interested in entering into a long-running discussion but could use help in understanding it and in making useful contributions. The forum should include affordances that make it easy and natural to classify suggestions, pro and con arguments, and so on, to keep this type of exchange from degenerating into just a free-form discussion
board. Another important kind of affordance would be hooks for giving sources for assertions (tools to encourage grounding arguments in the scientific data).
Another project might be a highly visible forum for exchanges between groups with quite divergent views in a deliberative setting. Again, the system should include affordances that make it easy and natural to classify arguments and perspectives and tools that encourage the grounding of arguments in the scientific data.
Basic research in educational technology is also crucial to increasing the relevance and effectiveness of tools for a culturally and economically diverse population. Arguably, better support for deliberation and engagement will not be enough. Supporting community action is also essential. In recent years technology has become more and more salient as an enabler of successful social change.28 In another example, on a local scale, citizen sensing of environmental indicators (e.g., pollutants) has influenced the ability of individuals to advocate for change. As the cost of sophisticated sensors comes down, one can expect to see more and more of them employed by end users. A citizenry that engages with and helps to track this information is important to progress on the issues at stake, and this engagement leads to increased education and engagement in addition to increasing the amount of information available in crucial areas. However, this raises fundamental research problems ranging from the creation of these sensors to our ability to use the data effectively despite the inherent uncertainties that arise from its production.
Techniques developed to design for manufacturing, design for mass customization, and user-centric design can expand on the understanding of what it means to design for sustainability. Techniques such as ENERGY STAR ratings for appliances and Leadership in Energy and Environmental Design (LEED) ratings for buildings have had some success in reorienting industry providers and consumers alike toward more sustainable practices. These efforts can be substantially informed by the measurement, information-collection, and model-development techniques described earlier, but can also use HCI techniques for appropriation, reuse, and end-to-end design for technology products. This research can be expanded to shed light on process, distribution, middleware, and other aspects of the production and distribution of products. Technological advances can
_______________
28T. Hirsch and J. Henry, TXTmob: Text messaging for protest swarms, in Extended Abstracts on Human Factors in Computing Systems, New York, N.Y.: Association for Computing Machinery, pp. 1455-1458 (2005). DOI: http://doi.acm.org/10.1145/1056808.1056940.
also contribute to the tracking, monitoring, and analysis of the source materials, production processes, distribution, and eventual disposal of products. This information in turn can help to inform purchase decisions, provide better accounting, and otherwise improve the sustainability of the consumer economy.
Human Understanding of Sensing, Modeling, and Simulation
As the availability of sophisticated sensors, information collection, modeling, and dissemination increase, techniques need to be developed to provide in meaningful forms rich, highly disaggregate information to households, small groups, and organizations regarding resource usage (e.g., for electricity or water consumption). In addition to supporting improved decision making about energy use at the organizational and individual levels, this information could provide civil and environmental engineers with a picture at a new level of detail about how and why these resources are being consumed, allowing their science and practice to advance. At the same time, this possibility raises challenging research questions regarding appropriate amounts of information, how to deal with the inherent uncertainties in the data, techniques for evaluating such systems, coupling with other systems on the supply side (e.g., the smart grid), and important value questions regarding fairness, representativeness, security, and privacy. Better data can also drive modeling and simulation, which can help with such activities as predicting important trends, assessing how well proposed policies would meet objectives, and optimizing resource use. Modeling climate change is an obvious example, but there are many others, including a simulation of the evolution of urban areas, freight transport, and natural environments such as forests or rivers. However, to be effective and relevant to policy making and decision making, such modeling work must include careful consideration of how it integrates with deliberation and the political process. This raises issues of design for transparency, legitimation, appropriability, and participation.
Tools to Help Organizations and Individuals Engage in More Sustainable Behaviors
Another area for research concerns tools that make it easier and perhaps even enjoyable for people to engage in more sustainable behaviors. Some of the many examples in this area are the providing of real-time public transit arrival and route information (particularly on mobile devices), online ride-share matching, geowikis for bicycling, Zipcar, Freecycle, and the like. Another class of tools provides eco-feedback: targeted information
about resource consumption (perhaps in real time), integrated with suitable visualization techniques and appropriate persuasive technology, for example to show progress toward personal or group goals. This area is also related to the previous opportunity regarding the use of information from resource-usage sensing. It is important to recognize the limits of these technologies: better transit information is great if a good underlying transit system exists, but it is not so useful without that. Similarly, eco-feedback regarding energy use can be helpful, but it does not address the more fundamental, underlying energy challenges in some situations—such as low-income households in which comparatively expensive upgrades would be a financial hardship, or homes that contain inefficient appliances or poor insulation. For such challenges, alternative solutions would be needed.
Many of the techniques described here are relevant to organizations as well. For example, a large organization might similarly provide targeted information about resource consumption, in real time, to show progress toward goals for different branches of the organization.
Mitigation, Adaptation, and Disaster Response
Even under optimistic climate change scenarios, weather disasters are likely to increase in number and severity, resulting in both the need for immediate disaster relief and likely the need to assist large numbers of refugees (e.g., from low-lying regions).29 Also, unfortunately, human actions are likely to continue to contribute directly to environmental disasters such as oil spills. There are research challenges with respect to developing plans that can be revised rapidly under conditions of great uncertainty, making use of vast numbers of citizen observations (such as micro-content posted from disaster areas by individuals), coordinating supply efforts, and others. One challenge for this line of work is recognizing that there are huge uncertainties about the future and thus also in developing tools and infrastructure that are flexible, adaptable, and appropriate.
Using Information from Resource-Usage Sensing
Recent work has opened the possibility of providing rich, highly disaggregate information to households, small groups, and organizations regarding resource usage. For example, immediate feedback can now be
_______________
29National Research Council, Adapting to the Impacts of Climate Change, Washington, D.C.: The National Academies Press (2010).
provided on electrical energy use at the appliance or individual lighting circuit level. A number of possibilities arise as a result, including detailed eco-feedback about usage and tighter coupling with smart grid technology on the supply side. Similar feedback is possible for other resources such as water and natural gas.
This possibility does, however, raise a number of challenging research questions. For example, what is the appropriate amount of information to provide to households? Clearly there is the possibility of overwhelming them with information. How are the inherent uncertainties in the data to be dealt with? How are such systems to be evaluated? The traditional HCI evaluation techniques of laboratory studies and small-scale deployments are inadequate, but massive deployments over long periods are slow and expensive, implying that one can only try a small number of alternatives (in tension with the need for rapid prototyping and iteration). How can these systems be coupled with smart grid technology on the supply side? For example, the grid could signal to the household that the system was close to capacity and that lowering energy use for the next hour would be very helpful (or perhaps would result in a lower bill); or, conversely, the household could be signaled that this would be an opportunity for some non-time-critical activity. This arrangement would be a combination of automated actions, with the scripts under the household’s control, and explicit actions.
Another set of issues concerns fairness and representativeness. For example, the majority of households in the United States are low-income and many households rent, although most work in this area focuses on relatively affluent homeowners. Can systems and policies be designed that do not unfairly disadvantage some households, particularly ones that can least afford additional charges? Another set of challenges concerns security and privacy. Such systems offer the potential for reducing resource consumption and making better use of resources, but there are clear security and privacy risks if the system is compromised. Related to that issue are questions of responsibility and power around available infrastructure that must be addressed. Not everyone owns a home or pays for energy use, and the relationships between landlords, residents, laws (incentives, disincentives, and so on), available services (green contractors), and other factors influence energy use outcomes and may bear on the design of technology (for example, in terms of authenticating who has access to what data).
It is difficult to get good information about the fine-grained use of energy right now. Buildings are not generally instrumented to produce these data, yet a true understanding of the forces driving energy use is impossible without better data. Better information about which appliances are in use and when they are in use can help in developing a more complete
understanding of human behavior, and perhaps in identifing interventions that can have an impact on energy use. Even a modest advance such as analysis based on the segmentation of a building’s energy use among HVAC, lighting, and plug load could yield useful results. Although this may seem like a pure sensing problem, the process of deploying sensors, labeling data, and interpreting the results involves people, and computer science researchers are at the forefront of some of the innovations in this area.30 Despite these advances, the problem of labeling data and interpreting the results is one that requires more attention.
This chapter provides examples of important technical research areas and outlines a broad research agenda for computer science and sustainability. Although there are numerous opportunities to apply wellunderstood technologies and techniques to sustainability, there are also hard problems—such as mitigating climate change—for which current methods offer at-best partial solutions, and rapid innovation is essential in light of the pressing nature of the challenges. The areas highlighted in this chapter—measurement and instrumentation; information-intensive systems; analysis, modeling, and simulation; optimization; and humancentered systems—are counterparts to well-established research areas in computer science. This overlap has clear positive implications. However, finding a way to have a significant impact may require new approaches to these problems and almost certainly new ways of conducting and managing research. Chapter 3 explores ways of conducting and managing research so that computer science research can have an even greater impact on sustainability challenges.
_______________
30For example, Patel and others have developed comparatively lightweight methods to acquire reasonably fine-grained data in homes; see J. Froehlich, E. Larson, S. Gupta, G. Cohn, M. Reynolds, and S.N. Patel, Disaggregated end-use energy sensing for the smart grid, IEEE Pervasive Computing, Special Issue on Smart Energy Systems, January-March (2011).



































