
Appendix A:
Commissioned Papers
A National Library for Undergraduate Science, Mathematics, Engineering, and Technology Education: A Learning Laboratory
Prudence S. Adler
Assistant Executive Director
Association of Research Libraries
Mary M. Case
Director, Office of Scholarly Communication
Association of Research Libraries
Introduction and Summary
Digital technologies are transforming all aspects of education including scholarly communication. These technologies provide an unprecedented opportunity to rethink how the education community including the research library community creates, uses, publishes, accesses, and manages these resources. The greatest impact of these technologies can be seen in the creation of new knowledge and how scholars, researchers, and students are increasingly finding new means of providing education services and collaborating Via the networked environment. This transformation or transition to a new mode of scholarly communication and education generally necessitates a rethinking of the concept of a "digital library." One does not want to recreate the current system that predominately reflects the print environment and as presently constructed, does not provide equal benefits to all participants.
Instead, in designing a digital library for undergraduate science, mathematics, engineering, and technology education, a starting point could be identification of the values or ethic of a new scholarly communications medium in support of education and to map these against the potential of the networked environment. As Einstein commented, "The significant problems we face cannot be solved at the same level of thinking we were at when we created them." There will be more than ever the need to heed Einstein's advice and think creatively in these discussions.
The development of a digital library for undergraduate science, mathematics, engineering, and technology education (SME&T) presents a unique opportunity to build a "library" which breaks out of the current system and incorporates the unique capabilities of the networked environment into its structure. It also permits the scholarly and research community to recapture and reengineer one facet of the scholarly communication process to meet their needs.
Selected Attributes of an SME&T National Library
The National Library should provide an active learning environment. Using the vast capabilities of the Internet and the Next Generation Internet, the National Library should provide a distributed system of access not only to primary data resources, reference materials, and other resources, but to a variety of interactive components including such features as: computer-aided design, lab simulations, access to research tools such as telescopes, instructional software, virtual reality, multimedia, teleconferencing, among many others. With the emphasis on introducing students to research early in their undergraduate careers, the National Library could provide not only instructional packages for basic undergraduate classes, such as calculus and statistics, but could also provide the opportunity for students even at small institutions to participate in the research of scientists located at major research universities. Simulations, online lab notebooks, shared problem solving would all support the collaborative environment that makes learning so exciting.
Key to this vision of a National Library is the concept of providing the resources, tools, and col-
laborative environment to support the creation of new knowledge. The promise of the networked environment is not in the pipes or the data alone. The great promise of the network is in the ability for human interaction with vast amounts of data and with numerous other students and researchers from around the globe. The value of many minds exploring the same problem or the serendipitous connection of seemingly unrelated efforts is enhanced by a national network. A National Library system that supports and encourages the creation of new knowledge by undergraduates could serve as a model for reshaping the educational process for other disciplines.
This National Library would need a number of attributes to succeed. First, the user must be able to access the available resources transparently, regardless of his or the information's location. A robust network, and effective and affordable delivery systems (bandwidth, scalable systems, and quality of service) are inherent parts of such transparency. Second, applications to retrieve, access, authenticate, evaluate, and utilize data and information, including detailed metadata and/or object content, will be critical in the effectiveness of the National Library and its adoption and use. Third, applications to perform operations on the data—to make it meaningful to the user—including the provision of links to other providers' sites, commercial or noncommercial, and/or to compile data objects to meet a user's needs, will be an essential component of the system. Fourth, authoring applications that simplify the reporting of research results, the incorporating of data Sets or simulations, the building of curricula, will be critical to ensuring timely and active reporting of research results by faculty and students. Finally, communications systems that support interactive real-time text, audio, and visual transmission—the key to the student-faculty, student-student, and student-resource interactions—are equally as important to the success of the National Library.
In addition to these technical issues, there are a number of practices and policies that need to be considered to achieve the vision of the National Library. Access to robust content is essential to the education and training of tomorrow's scientists and engineers. Content in the National Library must be provided with the understanding that it will be used in various ways to support the educational mission. These uses may include access through multiple sites by students across the country, printing and downloading for individual student and classroom use, excerpting for inclusion in papers, projects, instructional packages, multimedia presentations, etc. The uses may also include the making of preservation copies by designated library sites to ensure long-term access to the resources and new knowledge created through the system.
Content for the National Library will come from a variety of sources. Several years of backfiles of scholarly journals, varying by discipline, will need to be included. Permissions will need to be obtained and broad use rights as described above negotiated. Indexing and abstracting flies will also be needed to support efficient access to the published literature. Primary resource data, such as photographs from Mars, human genome data, astronomical observations, the periodic table, geographic information data, should also be at the student's fingertips.
To be successful, new practices and policies are required, particularly with regard to copyright and intellectual property. The current balance between users of proprietary information and creators of that information must be maintained while at the same time, rethinking how creation of information and access to that information is managed.
The education community is both a creator and user of proprietary information, Thus members of this community participate in the full spectrum of activities regulated by the laws governing copyright and must be sensitive to the balance of interests. As digital technologies revolutionize how information is recorded, disseminated, accessed, and stored, these technologies eliminate the technical limits that have supplemented the legal framework of balance between ownership and public dissemination. Unlimited technological capacity to disseminate by transmission in ways that can violate the rights of copyright holders confronts equally unlimited technological capacity to prevent works from being used in ways contemplated by law. Carried to its logical extreme, either trend would destroy the balance currently enjoyed, with results that would likely undermine core educational functions as well as radically transform the information marketplace.
New practices could extend this balance but ones that would represent a different ethic, namely balance in support of furthering the goals of the education community. For example, a legal regime which ensures that such factual data critical to the progress of science remains in the public domain is essential. It will also be important that current work of faculty and students be a vital part of the library. Participation in the library as an active learning environment will require faculty and students, if they choose to publish their work elsewhere, to retain the rights that would allow full use of the resource within the National Library. Participation in the National Library will also mean that faculty and students accept the responsibility to respect use restrictions where they apply and to respect the principles of attribution and fairness in the use of others' work.
To encourage faculty contribution to and participation in the National Library, implications for promotion and tenure will need to be addressed. If the new knowledge created through the National Library is highly collaborative in nature, with the potential for students and faculty from around the country making contributions, how is the contribution of an individual evaluated? Technology may provide some help, if methods can be found to track unobtrusively the flow of discussion as a group makes its way through a problem, simulation, or experiment. But at what point does such tracking invade the privacy of the participants? In addition, how is the extensive contribution of a faculty member to the development of a national curriculum in undergraduate science to be evaluated within an educational context that emphasizes research and publication?
Finally, the National Library will only be a success if it indeed improves the education of undergraduates in science, mathematics, engineering, and technology. Evaluation methods will need to be designed to measure pre-and post-library use. Not only skills and knowledge could be measured, but also interest in the disciplines, interest in research, and career plans.
Selected Concerns/issues to Resolve
- The SME&T National Library would be an extremely useful application to test the evolving and proposed infrastructure for the Next Generation Internet, the vBNS, and the I2 project. But to be effective, the SME&T National Library should be accessible and available well beyond those participating in these efforts. It needs to reach a much wider audience (e.g., community colleges and selected K-12 institutions) who generally do not have the necessary connectivity nor the resources to gain such connectivity. This represents a significant hurdle for the success of the proposal. Collaboration with the networking division of NSF would be essential to design strategies to promote needed connectivity to these other institutions. It will be important to view this as a multi-phased initiative; one that acknowledges the shortcomings and limitations of the current environment yet continues to promote a broader vision.
- As noted above, there will be a need to refocus the expectations and in many instances, practices, of faculty and students regarding publication, education, and access to resources beyond an individual institution.
- To be successful, the National Library must meet the timing and access needs of community, reflect how the materials are used, and in the settings that are most productive. This again may be particularly problematic with regard to connectivity issues.
- The availability of trained and committed staff able to build, navigate, and to translate the needs of users in this complex environment is another key factor in the success of this initiative.
If we think broadly and imaginatively, the digital National Library has the potential to create an exciting new learning environment for undergraduates that may result in better education and an increased interest in pursuing careers in science, mathematics, engineering, and technology.
The Digital Library as “Road and Load”: Partnerships in Carrier and Content for a National Library for Undergraduate Science, Mathematics, Engineering, and Technology Education
Harold Billings
Director of General Libraries
The University of Texas at Austin
Introduction
The "digital library" is still being defined very much with respect to how it is perceived in the mind of the beholder. A librarian, a computer scientist, an educator, a journal publisher, or a Web master will each have a different perception of what a digital library is from their point of view. For the majority of participants in the technical construction of the infrastructure that provides access to information on the Internet or within the World Wide Web, and for most of the users of that world, a digital library is simply a collection of information stored in electronic format.
Defined in this fashion, cyberspace is a virtual wilderness of digital information of frequently dubious content, utility, authority or longevity. The rapid growth of information sources that are of more obvious benefit to the business, governmental, educational, and technical communities—and to the prospectively larger benefit of the social weal—has led to an intensified examination of the infrastructure that supports the provision of and access to such resources. In several ways, there has been much more attention paid to the "road" to distribute and reach digital resources than there has been paid to the "load" it carries.
The digital library is much more than the definition above assumes it to be. Its roots lie much more deeply in the traditional library than is generally assumed, and its users are likely to be more typical, in need and habit, of traditional library customers than might be imagined. But road and load are dramatically different within the traditional and the digital library. This difference, built around the new information technologies, represents both the opportunity and the challenge for the establishment of a National Library of Science, Mathematics, Engineering, and Technology Education, because such a library must incorporate the best of each.
Road and Load
Road as carrier, and load as content are the most basic elements of a digital library. Carrier is defined by computing and telecommunications—information technology. Content is defined by the boundaries of several digital library spatial concepts. These concepts include those of information stored "somespace" in electronic format. It includes information in physical format stored somewhere, usually within the traditional library, capable of being transmuted into digital form and delivered through electronic transmission. And it includes the interactive distribution and receipt of purposeful scholarly communication, teaching, and distance learning content—all deliverable through the information technologies that provide the road.
Digital content may consist of textual information, sound, video, animation, raw data, response-invoking semiotics such as art or music, streaming communication, electronic curricula or teleconferenced course content, and so on—all of it hypertextually linked. Its sources may be commercial Web sites, "publications" by amateurs on the Web, interactive courseware developed at a faculty member's home page, databases at national laboratories, traditional library Web sites which supply information stored in local servers including bibliographic, textual and multimedia content, and a plethora of other information providers with a presence on the Internet.
The fact is that the information available via the Internet is dwarfed by the holdings of most academic libraries. The problem is that the road to the content of most libraries continues to be a manual circulation or interlibrary lending system that reaches print-on-paper resources. Comparatively little useful information is yet available through the Internet digital road and load, and as suggested above this information is a complex mix of digital library contributions.
The manager of the digital library selects and organizes this content, supplies access to it, and may provide new types of digital library assistance: e.g., routinely staffed interactive help-desks, electronic
messaging between user and library, the sharing among institutions of human expertise to provide specialized subject assistance, and information-gathering tools that use every hour of the day to identify and deliver to the scholar information of interest that has gathered in its space.
The best of traditional libraries are now identifying and providing the Internet address on their Web home pages of the most useful digital content providers. These. libraries are providing access to electronic journals and other information mounted on local or remote servers, and are encouraging the reformatting and delivery of information from library print collections into a load suitable for the national information highway. This is the same plan that is most likely to serve as the architecture for the National Library, a library of selective digital library and distance learning linkages.
Question. The selection of resources to be "held" in the National Library will certainly be a major issue. Is the concept of distributed selection the best model, or should there be a central "collection development" office? (It should certainly be assumed that a "collection development policy" similar to those used in contemporary traditional libraries would need to be constructed if determinations of the content of the National Library were to be made at the top, rather than built up through the accretionary development of choices made at the local SME&T participant level by faculty and library collection development experts.)
The growth of information available over the Internet has started to attract more attention by the federal, state, educational, and scientific sectors for its potential to enhance learning and research. The recent submersion of the Internet by commercial and personal interests has led to consideration of a means to establish an Internet dedicated to education and research. It is apparent, however, that there will have to be gates between these roads since a digital library will require access to loads on each. A number of projects at institutional, state, and library association levels have been established to promote a higher-quality information infrastructure and to foster the development of a more useful national structure of digital libraries.
Question. How is it possible to relate federal government and state activities in the changing model of distance learning and distance information? There is a growing federalism of library programs—that is, a distinct urging through funding and legislative mechanisms at the state level to push libraries into information management organizations or networks to leverage their resources. Will this conflict with the concept of a National Library for SME&T Education ?
In my view, the traditional library that in the past has supported the informational needs of the K-12, higher education, and the general public communities has not been as closely involved in the digital library movement as it should have been. This is a result of both lethargy on the part of the traditional library community and of a misapprehension by the information technology and instructional communities that there will be as important a role for the traditional library in the information future as there has been in the information past.
As I see them, traditional research libraries are being rapidly enhanced and extended electronically. In the most accurate sense of the word, these libraries are becoming increasingly "bionic"—organic, evolving bodies whose collections are growing rapidly in both traditional paper and in digital format, and that are increasingly responsive interactively with their users.
It is from the grass roots growth of information resources into the contemporary "bionic library," and from the creation of pockets of digital information created by multiple agencies and authors and distributed throughout the Web, that the hypertextual fullness of a National Library for Undergraduate Science, Mathematics, Engineering and Technology Education can be realized. To some extent, just as the definition of a digital library poses uncertainties in a discussion of issues relating to it, the metaphor of the "web" may confuse the necessary definition of the National Library and the prospective role of the National Science Foundation in that enterprise.
Given the organic nature of libraries and knowledge, a superior metaphor in these circumstances might be that of a hypertextual Knowledge Tree, with its roots in undergraduate scholarship and research and its limbs and twigs the result of the growth triggered at these grass-root levels. The information resources that abound today on the World Wide Web are not the results of a top-down effort, but rather that of a libertarian attitude that lets the many roots and trees and flowers grow. It is almost ironic that
much of the current digital library environment was designed by students who had the foresight to seize and exploit information technology opportunities. It is likely that this will be the same group that will continue to use the Web in unique and uncontrollable ways, helping create new mechanisms from which digital libraries and distance learning can grow. It may be that it is this group, also—students active in SME&T—who can tell us how a National Library might be constructed and how it might best meet the needs of the undergraduate student.
In terms of the information content of digital libraries and the services required of them, there is basically little evidence available today to differentiate between the methodologies of the users of science, mathematics, engineering and technology library materials and those of other disciplines. Content is the point. A major problem at the moment is the difficulty in attracting the attention of either faculty or students to the richness of the resources available to them through the Internet or the World Wide Web. But, ultimately, it will be this audience who will determine which information resources, which faculty, whose courses, what kind of learning techniques, flourish on the Web and which are assigned to the digital dust heap.
Question. How can the National Library and the National Science Foundation make the best use of the experience of institutions that have established digital library models and have provided both general content and learning resources to accompany the information they provide? An example is the Library of Congress's American Memory Project, and its accompanying Learning Page. How to adapt such programs for SME&T?
Distance Education and Distance Information
The location of information is of little importance until it is needed. Every hypertext location on the World Wide Web is immediately present to any other location, and every visitor on the Web is in virtual assemblage with other visitors. Time presents fewer constraints on access to information than it has in the past. Through the use of new information technologies it is increasingly possible for libraries to provide information to the user wherever, whenever, and in whatever format it is needed. The availability of the technology, however, does not ensure access to the needed information.
The barriers of cost, copyright, licensing, an absence of economic models, a deficiency of skilled knowledge workers and teachers versed in the capabilities of the new technologies, and a lack of understanding at policy-making levels of the advantages to be gained from the new information opportunities, have all restricted the level of progress that should have been made in this arena.
Perhaps the most serious impediment to progress has been the difficulty of gaining the attention, or maintaining the attention, or providing a sufficiency of attention by the groups that should gather in partnership to encourage a rapid and orderly progress towards a richer digital library model and, in this instance, to develop the National Library. Michael Goldhaber certainly has a point when he contends that the new natural economy is not information but attention. Whatever catches and commands attention becomes a major currency, although the target of that attention is only worth the informational substance imbedded in it.
The economy of digital libraries is a major concern. Digital reference works, electronic journals, and scholarly databases are already here, already on the Web, and already delivered to millions of undergraduates, and the number of these products grow by the minute. But these products do not come cheaply.
The enormous costs of information products in SME&T can be illustrated by the recent deal that Elsevier made with OhioLINK, the digital library alliance of Ohio. Elsevier has licensed its journals to members of OhioLINK, some 40 libraries, for three years, for $23 million—quite a load of another kind. Given this arrangement in one state, from one publisher, for three years, it is possible to gain some perspective regarding what the costs might be for the digital products of several publishers for just a few states for just a few years. Can a National Library offer a lower-cost model?
Question. NSF must ask itself what its most appropriate role would be in helping develop a National Library. Should it place its resources and effort at the top? or at the grass roots? Could it develop cost models, collect background materials, provide expert testimony, underwrite the preparation of electronic
curricula, support an organizational partnership to design the National Library? Or, might not its best role be as facilitator and enabler, not just of the National Library as a "collection," but as an agent to help direct scholarly communication towards a new model of SME&T information creation and delivery exemplified by the National Library?
It is very much the case that many funding bodies for educational institutions have seen the digital future and believe it holds the answer to reducing costs and achieving efficiencies in the learning process. The elevation of cost in the educational process has certainly captured the attention of those who provide its funding. Many examples of the implementation of distance education are appearing quickly on the national educational scene.
This rapid emergence of a demand for distance education and learning among institutions of higher learning—even though most teachers do not appear ready to embrace the concept—is leading also to the required availability of information to support these programs. Any learning process must include an information source. "Distance information" is just as relevant in this new paradigm as are new pedagogical considerations, as are issues that relate to teaching methodologies and learning skills, as are new environments for this process.
The traditional teacher-centered environment that has been a characteristic of the university as place is beginning to be replaced by learner-centered environments, where the requirements for distance education enterprises and for distance information are unlike those for the classrooms and the libraries of the past. There are new road and load issues implicit in this new model that require thoughtful consideration.
Any successful transportation or delivery system must pay attention to both road and load, to carrier and content, and to how each of these elements relate to one another. One must consider as a part of this entire system the technological, fiscal, legal, political and social issues, as well as telecommunications, content selection, content organization, indexing, human and machine interfaces, instructional tools, and, yes, even "sand boxes" to try the systems out in.
New alliances must be formed and focused on these issues since there is no single entity that can address them all. The National Library project can provide a venue for such a partnership.
Diminishing the Boundaries Between Educational Institutions
The development of distance education and learning programs, with its attendant integration of digital libraries, of computing, information technology, and telecommunications, may very well shake apart the fundamental distinctions between the very institutions that have previously provided the educational experience. A more placeless role for educational institutions could lead to a diminishment of the boundaries between the K-12, the higher education, and the lifelong learning processes and the institutions in which they have traditionally been located. It might also more easily provide for a binding of the teaching, learning, and research processes into a more seamless model that could help reduce the presumed fracture that too many persons believe exists between these tightly related educational activities.
The dissolution of the university as we have known it is a topic that appears frequently in the literature. The establishment of the "virtual university" is already occurring on at least a limited basis. As suggested above, it is undoubtedly the case that the same information content, pedagogical and learning processes, and similar interactive exchanges between teachers and learners—and their "libraries"—could very well be shared among the K-12 community and the undergraduate population of institutions of higher education. Lifelong learners, who will become an increasingly active component of the distance education population, as well as information users and learners in the research and business sectors, can very well make use of many of the same resources. The prospective far-reach of the National Library is probably far greater than can be immediately imagined.
More meaningful partnerships need to be established to extract the full advantage of what the digital library opportunity holds to improve the level of knowledge skills required for competition in a new world commerce of goods, services, and ideas where information resources and a command of attention are the chief currencies.
Information technologists, Internet engineers, computer scientists, human and machine interface designers, information service providers and publishers, experts in intellectual property rights, class-
room teachers, and librarians, who know the audience and the content—and including especially students themselves—who can articulate and resolve the complexities of the vision of the National Library, will be important to the success of any project that emanates from distance learning plans and digital library concepts.
Question. What is the best structure in which to incorporate the participation of those parties identified above to establish and maintain the National Library? Would the concept of a single centralized national center of responsibility be the best choice, or would cooperative, distributed centers of digital library excellence, centrally coordinated—a Virtual National Library—be a better model?
Whatever our preconceptions are of a digital library and the behavior of its users, the actual determination of those points will be made by the use that people make of the library. That will be determined by the marketplace of learning. That is the chief reason why the National Science Foundation must have as dear an understanding as possible of the road and load digital library issues that will confront the effective creation of an as potentially important learning and research resource as a National Library for Undergraduate Science, Mathematics, Engineering, and Technology Education.
References
Billings, H. 1996 [i.e. 1997] Library Collections and Distance Information: New Models of Collection Development for the 21st Century. Journal of Library Administration 24 (1/2): 3-17.
Billings, H. 1991. The Bionic Library. Library Journal 116 (17): 38-42.
Bothun, G. 1997. Seven Points to Overcome to Make the Virtual University Viable. Cause/Effect 20 (2): 55-57.
Goldhaber, M.H. 1997. The Attention Economy and the Net. First Monday (http://www.first monday.dk/issues/issue2_4/goldhaber/index.html)
Library of Congress American Memory (http:/llcweb2.loc.gov/ammem/)
Wulf, W. 1995. Warning: Information Technology Will Transform the University. Issues in Science and Technology 11 (Summer): 46-52.
A National Library for Undergraduate Science, Mathematics, Engineering, and Technology Education: Needs, Options, and Feasibility (Technical Considerations)
William Y. Arms
Corporation for National Research Initiatives
Digital Libraries and Undergraduate Education
Introduction
This is a discussion paper for the National Research Council workshop on August 7-8, 1997. The paper is arranged as a series of key topics that fall within the theme of the workshop. Although the paper emphasizes technical aspects of a digital library, it is impossible to introduce technical considerations without discussion of the overall goals and form of the library.
"Please can I use the Web. I don't do libraries."
ANONYMOUS CORNELL STUDENT, REPORTED BY CARL LAGOZE.
The fundamental question for the workshop is how can a national digital library enhance undergraduate science education. My basic assumption is that there is little utility in taking. existing education materials, designed for other media, and simply placing them on a computer network. The greatest benefits will be gained by modification of curricula and creation of different forms of materials, in parallel with the deployment of the digital library.
Some Personal Examples
Each of us brings to this workshop pre-conceptions based on our own experiences. Here are two examples of my own.
During the 1980s, as part of the Andrew project at Carnegie Mellon University, we invested heavily in the creation of educational materials. They were delivered over the campus network, through a networked file system—a campus digital library for education. The computing initiatives that grew out of the Andrew project have had an impressive impact on education at Carnegie Mellon. Our regular surveys of faculty showed more than half the faculty regularly using computing as an integral part of their courses, but the surveys also showed that most of this impact came from materials that were not developed explicitly for education. The surveys showed that the dominant educational uses were as follows:
- Professional computing tools. Many of the enhancements in education came from providing students with the same tools that the faculty use in their research and professional activities. These include applications programs (e.g., statistical packages such as SAS, symbolic mathematics such as Maple and Mathematica, graphical programs such as AutoCad or Quark), and mainstream computing applications (e.g., electronic mail, databases, and compilers). They also include data sets such as census data, NASA's images from space, and the genome data base. Although some of these tools began as non-commercial materials, by the time that they became widely used in science education, they were of a scale and complexity that required a commercial framework of support.
- Communication. For many years, the dominant applications over the campus network were electronic mail and bulletin boards. In addition, from 1986, extensive reference materials were provided by the university libraries over the network. These materials were widely used by both faculty and students. They also appear to have helped stimulate the steady increase in the use of traditional library materials that occurred during the same period, though it must be admitted that the use of libraries by engineering and computer science students (and faculty) never reached the level that one would hope. As soon as the Mosaic browser was released, the World Wide Web was adopted by the Carnegie Mellon community as a very important source of communication, both for finding and for publishing information.
The second example comes from my time as a faculty member at the British Open University in the early 1970s. This was the first large-scale university organized completely around home-based learning. Although Britain has good public libraries, many students do not have easy access to a library.
Therefore, we were forced to construct courses on the assumption that students had access to no materials other than those provided by the course team. The university provided each student with a set of educational materials. These materials included printed texts, reprints of articles, and home experimental kits. Television and radio were used to augment these materials; they were an important part Of some courses, but less important in my areas of mathematics and computer science.
The academic achievements of the Open University have shown that good undergraduate education is possible without providing the students access to a library. However, it places serious limitations on course design. In particular the options for independent work are severely limited. As distance learning becomes more common, the workshop might ask the question how can modern technology help a home-based university, or any university, improve on the Open University's approach thirty years ago.
Both these examples show the importance of creating services where the teaching faculty have a large measure of control over how the services are used in education.
Potential Benefits
To begin to answer the question how can a national digital library enhance undergraduate science education, here is a list of the potential benefits that might be hoped from a digital library aimed at undergraduate science education.
- Provide faculty and students with access to original scientific materials. Studying science from original papers, research reports, data sets, etc. is fundamentally different from learning based on distilled materials, such as textbooks. As the volume of scientific information that is crammed into undergraduate courses has grown, universities have moved from the ideal of a liberal education in which students explore a subject through reading original materials to heavily structured curricula. Recently we have seen a trend, at least in some universities, that is partially reversing this direction by encouraging students to carry out independent work, which requires easy access to the source materials of science. Independent work requires good libraries and a digital library has much to offer.
- Provide faculty with materials used in preparing courses. Preparation of a good course is extremely labor intensive. Faculty need ways to discover and evaluate educational materials and scientific source materials. They also need access to curricula, course notes, problem sets, etc. The better the services that are provided to faculty, the more they are able to build on the successes of others, and the less likely to use inappropriate materials or to re-create materials.
- Provide communication among faculty and students. Communication can be within a university or college, or across organizations. Many faculty, particularly in small colleges, are quite isolated. Networked services, such as bulletin boards and the World Wide Web, develop a community where they can cooperate in both education and research. In a similar manner, students can interact with others from around the world. There is continuing development in collaborative tools that allow faculty and students to distribute their work to others, including annotations and comments.
- Deliver specific educational materials. An increasing variety of educational materials are intrinsically digital. They include computer programs, data sets, various categories of multimedia items, etc. Computer networks and digital libraries provide a cost-effective way to store, retrieve, and deliver these materials.
-
One topic has been deliberately left out of this list, reflecting a personal bias. Because of a combination of technical and economic issues, my instinct is not to focus on using the digital library as a substitute for traditional textbooks. Computer networks have long proved to be an effective way to deliver course notes and other supplementary materials, but textbooks and courses built on textbooks are so closely tied to the strengths of printed volumes that they are difficult to migrate to digital libraries.
The Technology of Digital Libraries
Assumptions
The following are my basic assumptions about the proposed library.
- This is a digital library. Although materials will sometimes be printed by the user, and some materials may be available on CD-ROM, the focus is
- on materials that are created and stored in digital formats, and transmitted to the user over the Internet.
- It will be a virtual library. This will not be a conventional library in that it will not acquire and store all its materials. The digital library collections will be managed by many organizations, with materials stored on many different computers. Three models of delivery of information to faculty and students are possible: (a) directly from the originator of the materials (e.g., a publisher), (b) from a service center at the educational establishment (e.g., a library or media center), (c) from collections maintained by the national digital library.
- The library will contain both proprietary and public materials. Many of the best educational materials are created by companies or individuals who wish to be paid for their efforts. However, as the World Wide Web has shown, there is also an enormous quantity of high-quality material that is made publicly available at no cost. In some areas of science, large amounts of scientific source material are available online with no restrictions on access.
- Faculty and students will be able to interact with the collections. In a traditional library, it is a serious misdemeanor to write on the books or otherwise alter the collections. In a digital library the collections can be dynamic. People can annotate the materials, or link them to others; some materials are programs that students can execute or interact with; others can carry out computations, simulations, searches, or other actions on behalf of the user.
A Possible Technical Framework
Today's remarkable growth in digital libraries results from the maturing of several technologies: personal computers, the Internet, the World Wide Web, and protocols for searching online databases. Major areas where technical barriers remain include: interoperability among disparate systems, user interfaces, authentication and security, archiving, real-time and other non-static media, copyright management, payment for services, and searching vast amounts of information.
In each of these areas, there are adequate short-term solutions, supported by extensive research and development. Hardware costs and performance continue to improve rapidly. There are no fundamental, technical barriers to the development of digital libraries for scientific education.
A rough technical outline might be as follows:
- The digital library will be built on the Internet. Almost every university and college now has a good connection to the Internet. Faculty and students working at home can dial-up to their university or connect through an Internet service provider. All protocols will be based on the TCP/IP suite.
- Users will have a standard personal computer (PC or Macintosh) running widely available software. For the foreseeable future, the user interface will be a Web browser, such as Netscape Navigator or Microsoft's Internet Explorer. The library will select a specific set of standard formats and protocols. The aim will be to follow the technical mainstream as it evolves with time, but the library will probably need to provide some additional software to handle special formats, authentication and payment, and identification of materials. These will be provided as applets, plug-ins, or other extensions that can be installed over the network.
- Materials in the digital library will be stored on a variety of servers. The collections will be managed by a variety of organizations including universities, publishers, and libraries. With a large-scale library, where collections are maintained by many organizations, it is naive to believe that all the computers will be equally up-to-date or run the same protocols and formats. The library must accommodate the problems that are associated with heterogeneity. Today, many of the servers will be HTTP Web servers, but there will also be servers based on other protocols, such as relational databases (SQL), and Z39.50. Object-oriented systems using IIOP may be the next important development. Interoperation among such systems is not easy but can be achieved by adopting suitable formats and protocols. (The Stanford University Infobus project has done good work in this area.)
- Materials in the digital library will be entered into a registry. The registry is a centrally managed list of materials that have been selected for the library. The registry contains information about each item, but not the item itself. The information includes an identifier, a digital signature, the location of the material, and perhaps indexing information and annotations. (CNRI has developed a registry for the U.S. Copyright Office and is planning to deploy a modified version in other library applications.)
- There will be a central index to materials in all the collections. The indexing information will include cataloging and classification information, organized for distributed retrieval using modern methods of information retrieval. (Several good commercial systems are available today.)
- The library will permit annotation of materials. When an item is selected for the collections, an annotation is entered into the registry evaluating the material. Subsequently, users of the library can add annotations that comment on the effectiveness of the materials. (A fascinating approach to annotation is the Multi-Valent Document protocol developed by the Berkeley Digital Library Initiative. This is still a research project that has not yet resulted in any products.)
- Key parts of the library will be replicated. The registry and the indexing information will be replicated at several locations for performance and reliability.
-
Technically, all these components already exist, at least in preliminary form. Assembling and integrating them is, however, a significant undertaking. One challenge for the workshop is to set a framework that balances long-term ambition against short-term implementation difficulties.
Student Access
Student access is a problem. Students will use the digital library routinely only if it is convenient. Although student ownership of computers is increasing steadily, it is far from universal. The capabilities of their computers vary considerably and network access is still patchy.
Currently universities follow several different approaches to providing student access; none is ideal. Most universities provide some computers in student labs or computing clusters, connected to a campus network. This forces the students to go to the computer, thus wasting some of the potential of a digital library. Supply and demand are always a problem at peak times.
Another approach is for students to own their own laptop computers and to connect to the campus network on an ad hoe basis. This is increasingly common with law school students, whose computing needs are very simple, but in science education there are problems of cost, access to software, and hardware limitations. Many scientific applications require substantial computational power or network bandwidth. A variant to this approach, which is followed by some of the best undergraduate colleges, is to urge students to buy their own computers with their own money. The institution supports them by providing software, training, and network connections in the dormitories. This approach is usually supplemented by public computers in labs or clusters.
Each of these approaches is more convenient for a student or faculty member than being restricted to a traditional library. None is as convenient as owning a physical copy of each book. As a result, we are seeing a broad movement to provide digital copies of lightly used scientific information, such as journals, but limited enthusiasm for replacing core education materials with online materials, except for those education materials that are intrinsically computer applications.
Information Discovery and Guidance for Students and Instructors
The organization of materials in the library collections is central to its success. Faculty and students must be able to find relevant material quickly; they must have confidence in its accuracy and its suitability for their purpose.
Recently, the NSF sponsored a workshop in Santa Fe to discuss what should follow the current Digital Libraries Initiative. One clear theme emerged from the discussions. The Digital Libraries Initiative emphasized the creation of online library collections. Now, four years later, enormous amounts of material are online. Some of it is excellent, some is junk. Information overload is emerging as a fundamental issue in digital libraries. The undergraduate science library faces this problem. Instructors need help in identifying materials and evaluating their potential for specific courses. Students need help in exploring beyond the required materials. Because of their inexperience, students are often unable to evaluate the quality of materials. Therefore, evaluation and systematic description of material are vital parts of the library. How best to do this is a research topic, but there are some basic approaches that can be used today. Here is a possible framework.
- All materials in the library will be selected by members of the library staff. Sometimes, selection will be at an item level, at other times by groups of material. The method of selection and the selection criteria will be stored with all material, so that users will know why each item is in the library.
- Reviews and other annotations will be added to the materials. The library will systematically assemble reviews of materials and feedback of educational usage, from both faculty and students.
- External annotations will be welcomed. The library will encourage unsolicited annotations and recommendations from third parties. (As described below, some editorial control will probably be needed.)
- There will be a central index. Descriptive metadata about all materials will be consolidated in a central index to the library. It is anticipated that the process of creating this metadata will combine automatic indexing, with selective human cataloging and quality control.
- There may be other indexes to parts of the collection. Many of the individual collections that constitute the library will have their own indexes, catalogs, or finding aids.
This strategy does not expect the central library staff to be responsible for all aspects of information discovery. The Internet has shown us the power of private initiatives in organizing and presenting information in novel ways. The digital library needs to harness this utility and creativeness.
Policy Questions
Economic and Licensing Issues
Some materials in the library will be openly available. Others will be commercial products. Most core educational materials are created commercially as business ventures. The budget for each new edition of a major textbook approaches a million dollars; publishers of research papers are large and profitable; software packages and multimedia materials are equally expensive to produce.
Copyright has been used as the mechanism by which materials are controlled. At present there is intensive debate about the form that copyright should take in digital libraries. One opinion (which I share) is that this is fundamentally an economic debate. Whatever legal framework develops will enable the owners of educational materials to control their use, set terms and conditions, and price them as the market will bear.
Materials are paid for in three different ways. The first is by the student directly, by purchasing books, photocopies, computer software, lab fees, etc. The second is by the educational establishment, through its library, computing, and media budgets. The third is by the producer of the materials, such as by creating Web sites.
- Controls on access to materials. We are currently seeing a change in the balance between these three methods of payment, particularly with the growth of open-access publication of scientific research and other resources over the Internet. Thus we can expect that large amounts of good material will not require payment, but the library must be built around a framework that permits control of access to materials if required by the owner. (Currently the tools to do this are rather limited, except where a university or college has installed a comprehensive authentication system, such as Kerberos. Because progress has been disappointingly slow, systems have to rely on crude authentication, such as IP address or ID and password.)
- Controls on accuracy. The principal reason that authors and publishers wish to control educational materials is the desire to make money. A secondary reason is the wish to control the content, in particular to ensure accurate representation of the ideas and concepts, with appropriate attribution. One approach to this issue is to register each item as it is added to the collection with a unique identifier and a digital signature, which can be used to verify that an item has not changed. (This technology is becoming widely available from several sources.)
Good Science versus Bad Science
A tough policy decision is how much the library will be an arbiter of good science. The library must anticipate pressures from those whose political, economic, or religious agendas are antagonistic to good science and good education. With considerable reluctance, I suggest that, from the start, the library will need an editorial board of scientists committed to defending the library from these pressures. For example, unsolicited annotations are highly desirable, but the library must be prepared to exercise
editorial control if necessary. The aim is to find a balance between openness to new or controversial ideas, while weeding out the cranks and the bigots.
Conclusion
To build a large-scale distributed library for undergraduate science education is technically difficult. It faces no fundamental barriers, but to do it well requires a skilled and motivated team. It is vitally important that this team be driven by the wish to build a practical, high-quality service for education.
Even more importantly, the creators of the library must focus on the underlying challenge, how to have a major impact on science education. The challenge is to create a framework that will allow the teaching faculty flexibility to use the library in ways that were not envisaged by its creators. In this manner, it can indeed become the premier focus of materials for undergraduate science education.
A Digital Library of Undergraduate SME Education Materials: The Need and Technical Issues
Su-Shing Chen
Department of Computer Science & Engineering
University of Missouri-Columbia
Introduction
In the 1945 Atlantic Monthly article, Vannevar Bush provided a vision for an information system to disseminate and manage the vast amount of information accumulated about science, mathematics, and engineering. After 50 years, we are realizing his vision in information highways, information services, digital libraries, and many other information infrastructures, all made possible through the advances in computer science and engineering, information technology, and communications networks.
Since the NSF/DARPA/NASA Initiative of Research on Digital Libraries was started in 1993, many digital library projects have flourished around the world. In this article we discuss the need and technical issues of a digital library of undergraduate SME (Science, Mathematics, and Engineering) education materials. Such a library not only covers a wide variety of backgrounds and disciplines but also connects well the digital library content developers and technology innovators. In undergraduate SME education, content developers and technology innovators may be the same instructors and their student assistants. This is most evident in the fields of computer science, information science, library science, information technology, and computer engineering. This article provides some arguments for the need and a list of technical issues about a digital library of SME Education Materials.
The Need
Let us examine how traditional libraries were institutionalized. A library is a body of collected information brought together for the purpose of knowledge dissemination and utilization by users. Library collection evolves throughout the ages. The ancient library structure of handwritten books changed significantly by the introduction of the printing process in the mid-15th century. The printing process was capable of producing multiple copies of the same text. The proliferation of printed books for use in universities and learning centers drove the development of these institutions in which books were collected and stored.
This time a similar revolution stimulated by the advent of digital information is reshaping the library structure. Today's libraries Contain materials in many different media and formats. In addition to printed materials, libraries collect films, videos, filmstrips, computer disks, sound recordings, digitized files, and various kinds of media records. Despite the many changes in library operations and structures, the basic functions of the library remain the same: acquisition, collection, indexing, organization, dissemination, and utilization. We call this process the life cycle of information.
In the Information Age, technologies have the capabilities to potentially expand the life cycle of information into many new dimensions, and change the operations and structures of existing libraries as one of the oldest social institutions. In a digital library, information can be read, communicated, and utilized over subjects, spaces, and times by many library users. Fundamental but only intuitively understood is that knowledge may be disseminated and utilized in a digital library. Through knowledge discovery and visualization tools, information becomes knowledge of users. A digital library has more collaboration, explanation, interpretation, and presentation capabilities than traditional libraries. Information content can be processed and synthesized by computers into knowledge of users.
Throughout the recent years, SME education materials have been developed in a very large-scale. There is a significant amount of digital courseware for SME education purposes. The digital courseware is mostly in the form of online and CD-ROM materials provided by publishers, information technology vendors, and not-for-profit organizations. There is also federal funding for SME education. A notable example is the NSF Engineering Education Coalition Program. It was founded in 1990 with the purpose to change the paradigm of engineering education to an integrated experience focusing on the development of human potential and resources. The
results of these efforts can be captured, organized, and utilized in a digital library.
A digital library containing SME education materials serves students and faculty in colleges and universities. The collection and services of this library should be designed to match the need of their users that range from basic support of the curriculum to the research requirements of students and faculty. As the book, journal, and courseware production expands and spreads, worldwide information output has increased to the point where it is now impossible for a traditional library to acquire all the items produced in any but the narrowest of subject fields. As a result, a national digital library should identify and register the holdings of SME education materials around the country.
The following questions should be discussed:
- Who will be the potential user group?
- What will be the scope of faculty and students utilization?
- What will be the impact for improving undergraduate SME education?
Technical Issues
This article will describe several technical issues about a digital library of SME education materials. At present, digital libraries still seem to be different things to different people. A key observation is that digital libraries should not be simply networked information services. Digital libraries should be more organized and structured as traditional libraries.
As digital libraries are organizations involving humans and collections of information content, they are not just information retrieval and database management tools, nor they are object-orientation environments. A balanced overview of organization, users, information content, and hardware/software system shells is important.
There has been significant progress in the direction of hardware/software system shells. The increasing research funding, thriving information services and Internet related business activities are responsible. However the development of hardware/software system shells—e.g., information retrieval, database management, and object-oriented environment—alone will not guarantee the success of a digital library. A digital library of SME education materials must become a dynamic learning organization involving humans and collections of information content. Some technical issues to be discussed include:
- Organizational structure
- Content collection
- Authoring and creation
- Formats and standards
- User interaction
- User needs
- Copyright
The organizational structure and content collection of a digital library are its defining forces. For SME education, the learning process should be carefully defined, evaluated, and formulated. The organizational structure and content collection of a SME digital library must be compatible with the learning process.
The learning process of SME may be considered as a constructive theory of information seeking and utilization. The constructive theory of information seeking and utilization could be traced back to John Dewey. Recent researchers have addressed the limitation of the traditional system-centered approach to libraries. In that approach, library services, as the intermediary between information resources and information users, define all functions and operations without much considerations of usability and user needs as the primary purposes. The alternative is a new user-centered approach. Will digital technology realize the user-centered approach? At least it increases the usability and satisfies user needs in terms of the user/system/information interaction of digital libraries. To name a few capabilities, it supports information seeking planning, task analysis, and information utilization evaluation.
The organizational and technical aspects of digital libraries are mutually dependent. Digital libraries provide potential paradigms for the user-centered approach. New technologies enable users do information seeking, knowledge dissemination, collaborative learning, and other organizational activities. The linear life cycle of information seeking is thus extended to a spiral life cycle—a selforganizing process. In it, users are involved directly with the life cycle. A digital library impacts the tasks
and activities of users and user groups. The design and implementation of a national digital library of undergraduate SME education materials should take the user needs, usability, and learning requirements into consideration. Several relevant questions naturally arise:
- What will be the learning process of SME education?
- What will be the organizational structure of a national digital library for undergraduate SME education?
- What will be the SME education content?
- What will be the types of SME education materials?
- What will be the scope and nature of curricular content vs. pedagogic materials?
- What will be the adaptive process of change in curriculum and pedagogy?
- What will be the mechanism of integrating library materials and course materials in curriculum?
- Who will be responsible for the implementation, maintenance, and management of the library?
- Who will be responsible for the editorship of SME education materials?
- What will be the cost of establishing a national library of undergraduate SME education materials?
- What will be the long-term technical implications for hardware and software to support advances both in content and pedagogy?
Conclusion
A digital library of SME education materials will be different from a digital library of culture and history. SME education materials are not rote and mechanical. They are interactive and pedagogical. There are new challenges and opportunities in this effort. The user-centered approach to information seeking and utilization leads to the organizational structure of users and the knowledge dissemination of collaborative learning. The spiral life cycle of information seeking and utilization is a self-organizing process. In it, users are involved directly with the life cycle. This is our perspective of the learning process of SME education.
Digital National Library for Undergraduate Science, Mathematics, and Engineering Education: Comments and Another Option
Stephen C. Ehrmann, Ph.D.
The American Association for Higher Education
What Is “the Library”?
We have been asked to posit the nature of a digital library for undergraduate science, mathematics and engineering education, and then to critique what we have invented. My initial assumptions about its character:
- The library would maintain a refereed and indexed collection of curricular elements such as interactive exercises, heavily annotated syllabi, assessment tools and the like. Otherwise it would rapidly silt up and be abandoned. The collection would need to be reviewed and filtered frequently, especially since digital materials are likely to continue to have a short half life.
- There would be no presumption that NSF-funded materials would, or would not, be included; they would need to pass the refereeing process.
- The refereeing process would seek materials that would not be published by other means, typically because the costs of finding, editorial, indexing, and support would not produce returns worth a publisher's investments. (This intention is easy to defend in the beginning but may produce objections from publishers or the Congress later on.)
- Such a library would require significant funds to create and maintain.
Need for Such a Library?
- There's too much reinventing of round and square wheels in MSET teaching. There are a number of reasons for that, only a few of which would be dealt with by a library alone, however.
- Will enough faculty take the time to search the library? There are limits on faculty time available for screening and selecting materials, published or unpublished, once found; textbooks are relatively easy for veteran faculty to screen, as are short assignments; videos and nontraditional texts require a greater investment of time by potential users; interactive software on disk or Web can require most time. Good (expensive) screening can help this problem but only to a degree. For this and other reasons faculty seem to do little such searching. Is that changing?
- Would enough good material be available for the collection? For example, preparation for publication, and perhaps publication, of curricular materials would be the author's responsibility (?). Such editorial reengineering is a time-consuming business. Curricular materials that work for one's own students are rarely bullet proof enough, or documented enough, to work for others who have no special training or orientation.
- Other reasons to worry about the supply of good materials: free sharing of the library materials might mean no monetary incentives for the author or anyone else. Nor does such publication of curricular freeware usually earn professional rewards.
Issues to Consider if NSF Decides to Create the Library
- NSF, I'm sure, does not want to subsidize such an expensive endeavor forever. But where would continuing revenue come from? Who would continually pay, or donate, and why? Can you suggest a business plan that relates a user base, frequency of use, fees and costs?
Additional Comments
- This idea reminds me a little of a CD-ROM called "Mathfinder" that was funded by NSF and developed by the Education Development Center, composed of K-12 math materials, organized using the NCTM Standards. It would be worthwhile to see how influential that product was. One of my former colleagues at the Annenberg/CPB Project commented recently that Mathfinder was "a solution in search of a problem. How big a need is there for easier access to a comprehensive collection of aging curricular materials?" That's just one person's view, of course, but I suggest you study its character, full costs, benefits, and fate.
References and a Suggestion for What NSF Might Do Instead of a Library
We tackled similar problems of reinvented wheels a few years ago at the Annenberg/CPB Project. We used a rather different design: the "Rethinking Courses" funding program that focused on selected content areas. Our six projects were intended to:
- seek out hard-won experience (negative and positive) in applying technology to educational needs in a particular content area of high priority (finding good instructional materials was only a small part of this inquiry),
- analyze and synthesize the resulting findings in order to create outreach materials and opportunities that could help large numbers of faculty improve their teaching in these content areas,
- market and offer that outreach widely, especially using the Internet (libraries, directories, online seminars, train the trainer, etc.), CD-ROM, video tape, and print.
I'm proud of what those projects have accomplished so far. However in retrospect they were badly underfunded, averaging $150,000 each for a two-year project.
Two examples drawn from the six projects:
- Central Michigan University's awards program for rethinking service courses in math (co-funded with NSF, about $150,000 over two years) <http://www.cmich.edu/~mthaward/> and
- the American Studies Association's Crossroads Project, co-funded with FIPSE (total funding of $400,000 over three years). <http://www.georgetown.edu/crossroads/> The latter project demonstrates a mix of scholarship and outreach that might be one good model for NSF.
Given Annenberg/CPB's experience with "Rethinking Courses" and my subsequent experience with AAHE's Teaching, Learning and Technology Roundtable Program, I would suggest the following not-really-a-library strategy:
- Identify key, focused instructional problems—Moderately Grand Instructional Challenges (MGICs) such as learning bottlenecks and other reform priorities in specific fields.
- Fund a continuing inquiry for existing wisdom about each of these MGICs (including but not limited to curricular materials)—a process of continual searching, gathering, editorial work, and publication. This search for wisdom would include a search for problems encountered when adopting new approaches, for staff development strategies needed to implement approaches, and so on.
- Support extensive scholarly analysis of the findings.1 Cross-indexing would help spotlight the inevitable relationships between the responses to the various MGICs. When the Initiative finds important gaps in what's available, even after rigorous searching, it would publicize them to academics, to NSF, and to other funders.
- Active outreach: Sort these MGICs not only by content and educational level but also by whether the problem can be dealt with by an individual faculty member (e.g., adopting a new assignment or reading) or whether it requires departmental or institutional action (e.g., studio courses). Use different outreach strategies for each of those two categories, e.g., problem-specific e-mailed periodicals to alert individuals to new "holdings"; team-oriented workshops and seminars online and in regional meetings to help teams utilize "library" resources in developing local attacks on more complex problems (e.g., reforming math sequences and the facilities supporting such teaching).
- Economics: seminars and workshops would be fee based. For access to the collection, institutions would pay a fee to give their own staff free access, similar to the way colleges provide free access for their communities to journals or the Internet. My guess is that revenues could never pay the full price of the enterprise, but the enterprise would be required by NSF to recoup a fixed and substantial fraction of its operating costs. So long as the enterprise could find and keep a sufficient market, it would be subsidized by NSF. I think this market discipline would help attract a more aggressive and creative staff.
Digital Libraries for Educational Reform: Instantiation, Ignorance, and Information
John R. Jungck
Mead Chair of the Sciences
Department of Biology
Beloit College
Education for the future must be based on a more profound appreciation for actual professional practice in science, mathematics, engineering, and technology (SMET) than current classroom and laboratory practice. Students are screened off both from the power and potential of contemporary technology. Why is it that when powerful research software operational on microcomputers, that can do the work of main frames affordable only to major research universities, is easily affordable, if not free, that few students are even exposed to learning how to use these powerful design, analysis, computation, and visualization tools? Why is it that when databases exist on the World Wide Web which students could use to perform original research that they have to continue doing cookbook exercises or simple demonstrations? Why is it that when the World Wide Web can serve to connect millions of learners that we persist in an individualistic orientation to education rather engaging students in collaboration, communication, and peer review of their finest ideas and projects? Is this not an enormous waste of intellectual power, a misuse of human effort, and an antidemocratic view of education?
If these four questions serve as a preliminary introduction to NRC's questions about the role of digital libraries of SMET educational materials, then what alternative metaphors can we explore for instantiating a radical alternative to outmoded views of education that focus on one-way transmissions between teachers and students, that depend upon the acquisition of information rather than the evaluation and utilization acquisition of information, and that isolate, individuate, and alienate rather than connect learners.
Recent reports have suggested that scientists and engineers have access to "collaboratories" which enable them to remotely operate expensive and sophisticated scientific equipment. Science studies
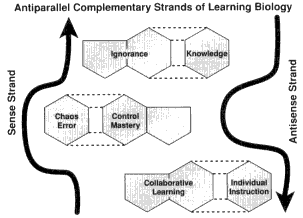
Figure 1.
A BioQUESTian learning paradigm: Ignorance, Error, and Chaos.
have reported upon the enormous sociological shift in SMET work where international teams of teams work on projects. For example, consider the recent sequencing of the entire genome of Bacillus subtilis (Science July 1997) that involved seventeen teams from Europe and Japan or the MIR space station that has teams from both Russia and the United States as well as scientists from other countries and projects of global interest or biodiversity studies in the Amazon that involve the development of data bases based upon data collected over many years by participants from numerous countries. Scientists publish papers as multi-author teams. These practices are distinctly different from those currently seen in schools. As evolutionary biologist Michael Wade, of the University of Chicago, has said: "It takes a whole village to educate a graduate student in systematics and evolutionary biology." What other subjects reflect this concern? In this particular context, how do we organize, collect, access, share, and query a digital library for SMET education if we are to base its instantiation upon these contemporary SMET practices?
Let us consider an antiparallel model to much of contemporary education (see Figure 1):
Please note that we (members of the BioQUEST Curriculum Consortium) have used the sense strand of this antiparallel double helical representation of learning biology as containing three
bases or cornerstones of this alternative mode: (1) ignorance, (2) error and chaos; and (3) collaborative learning. Since the latter is so much a part of most American higher education reforms in science education (e.g., Priscilla Laws' and Ron Thorton's "Workshop Physics," David Smith's and Lang Moore's "Project CALC" {a calculus reform project}, and Brock Spencer's and George Lisensky's "ChemLinks”), we simply refer readers to them (links describing their projects are connected to the BioQUEST Curriculum Consortium homepage). One critical element of the collaborative learning approach where BioQUEST differs from some of the other reforms is that we distinguish between simple cooperation in the acquisition of already known scientific principles and the collaborative construction of meaning in the world promoted by educational constructivists (Bruffee, Driver, Stewart, yon Glaserfeld), by "strong program social studies of science” theorists (Latour, Woolgar, Barnes, Knorr-Cetina, Shapin), and many feminists (notably Longino).
In order to instantiate science education with a more robust possibility of preparing students (all future citizens, some future scientists) to comprehend and/or participate in scientific decision making or investigations, several aspects of ignorance, error, and chaos that might lay a better philosophical foundation for such enabling possibilities. Also, scientists may better appreciate why "the public" frequently misunderstands them if they see that usual measures of education based on knowledge, mastery, control, and individual competition misconstrue much of their own motivation for pursuing science based on curiosity, love of puzzle solving, desire to collaborate with their peers and respond responsibly to criticism, and ability to persevere with enormous frustration in their pursuits. How does this "sense strand" influence: Individual student learning? Collaborative student learning? Interest, confidence, and competence in scientific problem solving? Ability to cope with frustrations in pursuing unsolved problems and to deal with resistance to change? An ability to do scientific research and draw warranted inferences from research? The context of scientific research whether by a student or a professional? An appreciation for history of science? Roles of science in society? Professional responsibilities?
Figure 2.
Michael Smithson's "Taxonomy of Ignorance" (1989).
From Ignorance and Uncertainty: Emerging Paradigms © Springer-Verlag, 1989. Reprinted with permission.
Ignorance
Why ignorance? We assert that the purpose of science education is to help citizens understand scientific values of humility about the current state of our knowledge, the limits of our practice, social responsibilities of scientists, and respect for the processes of investigation and communal peer review as well as the education of future scientists who are able to explore new and difficult problems creatively, rigorously, and responsibly. Michael Smithson, a fuzzy set theorist in the social sciences who is concerned with public decision making about environmental risks, has laid out a decision tree for ignorance (Figure 2).
Why ignorance as a value for informing science education?
First, while ignorance is socially constructed, it is usually less commodified or miffed than "knowledge" (usually with an inferred capital K). Smithson (1989)
elaborates this thusly: "Ignorance is a social creation, like knowledge. Indeed, we cannot even talk about instances of ignorance without referring to the standpoint of some group or individual. Ignorance, like knowledge, is socially constructed and negotiated (p. 6)." One of the widely shared values of scientists that is usually difficult for students to understand is widespread skepticism. The poet Kenneth L. Patton asserts this positively in his poem, "The Faith of Doubt" of which I only share a few verses:
Doubting is but the forefront of faith,
a faith in the inexhaustibility
of growth and the illimitable
extent and wonder of the universe.
A doubting age is an age in the restlessness
and discontent of growth; a doubt is an
idea that is still alive.
To doubt that the past has uncovered
all things is to express faith
that many things are still to
be uncovered.
Thus, the wonder, awe, and mystery that drives many scientists throughout full and long careers can be more easily shared with students. Science can be a search for deeper questions rather than a quest for eternal, absolute truth. The fallibility of science can help to differentiate our practice from aspects of religious conversion. In The Encyclopedia of Ignorance, the editors Ronald Duncan and Miranda Weston-Smith (1977) introduced the volume by stressing these values: "Compared to the pond of knowledge, our ignorance remains atlantic. Indeed the horizon of the unknown recedes as we approach it. The usual encyclopedia states what we know. This one contains papers on what we do not know, on matters which lie on the edge of knowledge. In editing this work we have invited scientists to state what it is that they would most like to know, that is, where their curiosity is presently focused. We found that this approach appealed to them. The more eminent they were, the more ready to run to us with their ignorance." One such famous scientist, Charles Darwin, notes that being: "Deeply stirred by the excitement of hard scientific thought, he succumbed to the full force of ambition. To chase a theory through the mind like this was marvelous: an intoxicating combination of effort, skill, caution, and bravery - and in this case too, a healthy dose of ignorance which encouraged imaginative leaps in the geological dark... (Browne, 1995, pp. 185-186)." Note that this approach flies directly in the face of Jeremiads such as most recently John Horgan (1996) who proclaims in his book, The Ends of Science, that “further research may not yield much.” Today's students have infinite possibilities for problem-solving opportunities that are as likely to radically transform science as in the past: with an explosion of knowledge, there is a parallel development of associated questions that have never arisen before.
I. Considerations about the potential nature and impact of a National Library:
- Who and how large is the potential audience? What is the evidence that faculty and students would utilize this resource?
- What impact can be expected for improving undergraduate science, mathematics, engineering and technology (SME&T) education community ?
Several of the greatest problems in transforming collegiate science curricula relate directly to people's knowledge of resources. If there is no "library" that focuses upon collecting, classifying, indexing, querying, sharing, and making accessible technological curricular resources and reviews of those materials, then there are enormous costs in the initiation, instantiation, maintenance, and extension of curricular reform:
- because a democratic view of SMET education should support the ability of students to pose problems, solve problems based upon in-depth searches and analyses of complex, multidimensional, multivariate data sets, and persuade their peer reviewers of the quality of their hypotheses, a digital library should serve students in each of these phases of their work. Collaboration among students is as critical as the need for national collaboratories, international genomic data bases, and massive biodiversity analyses that include GIS, GPS, geographic, geologic, meteorologic, cartographic, hydrologic, and biotic data sets;
- because there is no equivalent to Science Citation Index for the many curricular initiatives
- that are funded, or are local to one campus, or even those which have articles on them in journals, newsletters, and magazines, there is enormous wastage due to the "not-invented-here" syndrome. In particular, NSF does not get the full benefit of their critical investment. Many marvelous innovations of the post-Sputnik era have simply been lost because few others than the innovators themselves have any knowledge at all about these NSF-funded innovations;
- because many technological changes have come "top down" on campuses by adoption of hardware, across campus wiring programs, and commitments to use of the World Wide Web in the absence of consulting faculty about what software has been most transformative in the teaching, learning, and research in their discipline, professors frequently have inadequate exposure to what exists out there because of limitations imposed by these top down decisions;
- because the diffusion of technological innovations has been "owned" by developers and "early adopters," there has been enormous discussion about how to make what has been created much more accessible to the vast majority of professors who may only be using “worldware" such as e-mail, WWW searching, word processing, spreadsheets, graphics, mathematical and statistical packages, or presentation packages. Even if they have physical access to curricular materials to review, they may not have learned about how to evaluate the diversity and quality of many discipline-specific software applications for learning and research. Evaluation should not only be based on the SMET content, but also on the GUI interface, the quality of the algorithms implemented and how they have been implemented, and perhaps most importantly, upon the pedagogy involved. Most professors have no experience in evaluating software that are incompatible or incommensurable for cooperative versus collaborative learning, for formative evaluation versus outcomes-based education, or for active learning in a student-centered approach versus teacher-centered instruction. Frequently, professors eclectically treat the potentials as a Chinese menu and fail in their initial attempts because they have combined mutually exclusive approaches that are based on diametrically opposed educational philosophies;
- because the professional costs to individuals have been enormous without such a "library" due to the difficulty in documenting the impact of their work on transforming college curricula through the development of curricular materials. Many professors who have taken the risk of being innovators, particularly of those innovations that extensively employ technology, have suffered because of the lack of understanding for the professional quality of good technological innovations. If the new, primary, and extremely productive contributors have been raised in a new generation that is computer literate, used to enormous computer power and wide access and democratic practices associated with expression on the World Wide Web, then how do we build a library that helps document their contributions and their impacts?
II. Considerations about content of a National Library for undergraduate SME&T education:
- What types of materials should be included? Should materials be removed from the library as curriculum and pedagogy evolve? Who should make these decisions?
Thus, the National Library for SMET Education must store, classify, and make available "every" funded SMET educational innovation in a highly democratic fashion that provides both access and equity. Since philosophy and history are critical to informing a deep view of educational reform, it is necessary to not only seek out "best practices" but to extensively collect, evaluate, and make more available an exceptionally. wide diversity of materials: books, journals, magazines, software, syllabi, grant proposals and reports, equipment, and gadgetry. Thus, it is hoped that the National Library for SMET Education will develop and maintain archives, rare collections, and other antiquaria rather than falling to the whims that anything five years old is obviously irrelevant.
- How can the library respond to changes in curriculum and pedagogy? How might the scope and nature of the content of curricular and pedagogic materials for inclusion in the National Library be made? Who should be involved in making such decisions? What
- standards are needed for inclusion of materials in the library? How would those standards be implemented?
Bruce A. Shuman (author of The Library of the Future: Alternative Scenarios for the Information Profession) suggests a list of tools for futurists involved in such planning:
- an open mind
- pooled intuitive judgment
- thoughtful reading, especially of science fiction and fantasy
- computer simulation and modeling
- gaming and role-playing
- scenario writing and discussion
Note that this list is heuristic rather than algorithmic. The exploration of needs for the National Library for SMET Education should not be based upon the technology that is currently available to construct such a library, but instead upon the diversity of materials already produced and an openness to the sorts of materials that are likely to be immediately on the horizon. As an evolutionary biologist and computer educator, I will risk that the National Library for SMET Education should model itself on those aspects of living systems that enhance potential for adaptation to rapidly changing fitness landscapes. Some of the current technology that has been used to develop (note: not design) such systems have employed genetic algorithms, evolutionary programming, neural networks, and multivalue or "fuzzy" logic. While I would not prescribe any one of these with great confidence, I do believe that these investigators are seriously addressing the problems of building (evolving) open, flexible, robust approaches to problem solving. I therefore believe that these investigators as well as many curriculum innovators and library reformers should be involved in the planning conversations. In that way, it is hoped that any arbitrary notion of "standard" be visciated in favor of a dynamic, adaptive approach that will constantly be re-evaluating the "state of the art."
- What other kinds of support would users need to integrate materials from the library into their courses and curricula and use them effectively ?
The establishment of the National Library for SMET Education should be coordinated to a variety of workshops, listserves, chat rooms, national meetings, dissemination, information bulletins, and collaboratories. Fundamental to change is taking risks. Asking people to take risks should be coordinated with the development of sustained support for people while they make forays into unexplored territories. Thus, long-term commitment is one of the most important aspects of providing support for change.
There should also be an appreciation for the diversity of institutions in which SMET educational reform is occurring. Community colleges in large urban areas face different problems from geographically widely dispersed institutions in rural regions. Small liberal arts colleges have a long historical set of expectations than engineering universities. Teaching is differentially valued in state universities that serve a local populous from internationally famous research universities. Students from various backgrounds socioeconomically, racially, ethnically, and geographically may come to new curricula with widely divergent expectations and prior experiences. Visually and manually challenged individual needs should be met.
Disciplinary differences also should be recognized. One size does not fit all. Engineers assume that contemporary technology should be rapidly assimilated into curricula. Mathematicians may value thinking per se over the introduction of extensive software and hardware into their curricula. Field geologists and biologists may have very different values from experimental bench scientists. Curricula need to be sensitive to the professional practices of these different communities to meet the criteria expressed in the introduction.
Conclusion
The National Library for SMET Education should enable the instantiation of curricular reform that is fundamentally democratic, open, flexible, and dynamically evolving. But a word of caution is necessary. In 1971, Thomas Childers ("Community and Library: Some Possible Futures," Library Journal 96: 2727-2730) stated: "How generously will a constituency support an institution. that is unused by the majority of adult residents, an institution that may be more of a monument than a
resource actively responding to the dynamics of society?" Shuman (The Library of the Future: Alternative Scenarios for the Information Profession, 1989, page 49) responded: "So what can the library do to prevent its own murder, suicide, or enfeeblement? Childers provides some alternative futures for the library, any of which could happen but each of which would require consensus, goalshifting, planning, cooperation, and effective carryover into a new, usually unfamiliar realm of what we do. Childers's list was a promising start and a commendable job of trying to carve out a societal niche for the public library before society metaphorically shelves the library in a rundown warehouse on the outskirts of town. But the authors contends that the list deserves fleshing out and expansion. . ."
Herein I have argued that a metaphor based upon open questions from students and unsolved scientific and societal problems and a pedagogy based upon ignorance, error, chaos, and collaborative learning will be more appropriate metaphors for the establishment of a library which will continue to serve curricular reform.
Issues in Developing a National Digital Library for Undergraduate Math, Science, and Engineering Education
James H. Keller
Information Infrastructure Project
Harvard University
Developing a national digital library presents a breakthrough opportunity for redefining the role of the library in supporting undergraduate SMET education, and potentially in reshaping the overall paradigm for undergraduate learning. The creation of such a resource requires an understanding of the unique enabling characteristics of the supporting infrastructure—both those that exist today and those that can be fostered. A national digital library for undergraduate math, science, and engineering education is, of course, not a stand-alone resource. It is one element of the larger, general-purpose information infrastructure. This paper will include attention to issues related to information and digital library infrastructure for other domains and disciplines as they relate to this community.
The digital library and its development will involve not only integration with the larger information infrastructure, but will also require a careful evaluation of the manner in which it will integrate with the larger organizational process for undergraduate education, including peer review, certification, and the system of professional reward necessary to engage participation in content development and evaluation. This latter set of requirements represents perhaps the greatest barrier to the success of the library. Technical development is not trivial, but is largely achievable with existing commercial capabilities. On the other hand, the institutional and organizational requirements of the library are daunting—only achievable with strong endorsement and participation extending well beyond the library community. The goal should not be merely to transfer the traditional library function to the networked environment, but to maximize the learning and research opportunities that can be enhanced through this new medium. This will require linkages beyond the higher education community to the larger technical and standards development efforts of which the library will be a part. It will also require participation in the ongoing public policy debates about the treatment of copyrighted work in the networked environment and about telecommunications policy, including universal access.
The Vision
What will the digital library be? The word library conveys the idea of a resource providing access to information, but in the digital realm a library is much more than this. It is an interactive vehicle for instructional learning, providing access to course materials, such as syllabi, and other instructional materials. It will run over a general purpose, most likely web-based, communications infrastructure, and will be accessed through general purpose client machines. The content will likely exist on distributed machines (an issue that will be explored later). Therefore, the question of what is and isn't the library becomes fuzzy. In practical terms, it may be described as a broadly agreed upon and deployed set of conventions for presenting, locating, authenticating, accessing, and using information for purposes of supporting undergraduate education within the worldwide Internet. Some parts of this space will be private, some public. It will support fair use access and market-based exchange. In many ways, this decentralized set of heterogeneous and autonomous networks and servers is, in an organizational sense, very much like the larger Internet. The Internet has evolved based on a set of voluntary agreements about standards for network interconnection and the presentation of information. The success of this system has been attributed to what has been called "the tinkerbell principle," a simple and powerful concept.1 In other words, it works because everyone believes it will. In the case of the Internet, faith was-reinforced through participation in the Internet
Engineering Task Force, a de facto standards body, whose legitimacy was strengthened by the ongoing participation of the U.S. government. Such an institutional focus will provide essential glue in the development of a national digital library.
The digital library will not replace the physical library. In fact, it is not a substitute for access to text-based materials, which are typically converted to print for use. The digital medium excels in browsing and in providing access to information, rather than text. The organizing paradigm for the digital library should be information, rather than documents, and the structure must support quality and context as search criteria.
A digital library to support undergraduate SMET will be both more than and less than the traditional library. If properly conceived and implemented, it will be more in that it will extend broadly and deeply into the whole set of functions related to undergraduate education. It will be less in the sense that the digital library itself may not house digital works, rather it may just help the user locate them within the larger Internet. The defining element of the library will be its search and indexing functions, and the digital library itself may be purely an index or registry and not a repository.
Why Develop a Digital Library?
A digital library can provide a repository and distribution mechanism for multimedia learning resources, but the true opportunity is far more profound. Historically, the links between undergraduate education and library use have been quite tenuous.2 If a national digital library is to be considered as a resource to support learning, it must go beyond providing access to static resources. The digital library presents an opportunity to overcome physical and geographical barriers and become integrated more closely with other functions of undergraduate education. The library may be brought into the classroom and study session and may also be seamlessly linked to web-based syllabi and computer-based learning modules. These opportunities require an assessment that looks beyond issues in development of a digital resource and addresses the larger questions of improvement of and expanded access to the undergraduate learning process.
Technical development of the key functional elements of a national digital library to support undergraduate SMET education can largely be fulfilled with existing web-capabilities. It can be built with existing knowledge and tools, but successful use of this resource will require a fundamental rethinking of the larger learning process in which it is intended to operate. This would affect some of the defining elements of the university, including peer review, standards for professional achievement, and undergraduate teaching. Any plan for a digital library which does not recognize and adequately address these organizational requirements should not proceed.
What is Different About Digital?
The most fundamental breakthrough presented by the move to digital infrastructure is the destruction of traditional notions of time and space as they relate to library access. This phenomenon presents important questions about the functional role of the library. For example, should the digital library be defined by education level and discipline, or be leveraged across a larger community? In other words, how much should it be different from the library that serves high school or graduate education, in math, science, and engineering, and in other curriculum areas? The undergraduate experience with the library could be an introduction to a lifelong resource. Similarly, the library would provide infrastructure (software, systems, processes, rules) which could serve many disciplines and communities. The opportunities for institutional and functional convergence are nearly boundless, and, in many cases, create significant and compelling economic effects. For example, the infrastructural requirements of the digital library are very close, and in some ways identical, to those of electronic commerce. These criteria include locating, evaluating, retrieving, and paying for information. In terms of institutional convergence, the library capabilities may be built into distance learning, adult education
programs, or industry research. The difficulty lies in coordination of systems and processes, and the problem shifts in part from one of invention to one of partnership and leveraging.
As thinking about the library enters the world of intelligent infrastructure, it quickly encroaches on other functions. Just as the digital library is a vehicle for access to information, it also presents a means for publishing and broadcast. It will be a medium not just for text, but also for new data and research results, digital models, and other multimedia objects. The creation of a system that seeks to extend these opportunities, while ensuring quality control and authentication, may promote rapid dissemination of new knowledge. This will rely on a system which recognizes the intellectual property interests of publishers (commercial, individual, and non-profit) and users. A key to minimizing intellectual property concerns is leaving them in the hands of the publisher. This will allow each to rely on policies which serve their respective professional and economic interests, and will reduce central administrative costs by pushing them out to the edges of the system. Such a decentralized, user-driven model minimizes the issues in ensuring continuity for the library beyond the period of its initial funding support.
The ability of the digital library to recast the learning process by extending across traditionally distinct institutions and processes raises the question of whether the word "library" remains an appropriate moniker. The so-called "digital library" will, if properly designed, quickly become a part of most, if not all, scholarly aspects of the university and the larger research community. Creative thinking about the opportunity presented by the digital library may be better served by the use of another name, such as the national digital university, or electronic learning resource. One benefit of the continued use of the term "library" is conformance to traditional funding criteria and guidelines in institutions such as NSF. These institutions must also adapt, however, to shift to a new paradigm for learning.
Intellectual Property Protection and Use
The success of the digital library will rely on meeting the intellectual property requirements of content developers, owners, and users. Currently, the legal framework for intellectual property rights is being reevaluated. 3 At the same time, new technological approaches to protecting intellectual property are being developed. These technological approaches present potential opportunities and threats to fair use of copyrighted material. While it is currently just about impossible to control copying and distribution of digital works once they leave the immediate control of the owner, it is possible that the pendulum of control will swing dramatically in the other direction. It is possible that technological approaches to intellectual property management will emerge that are so robust as to preclude any access or use that is not explicitly authorized. Such a scenario would effectively obviate the fair use provisions of copyright law relied upon by libraries and other educational and research users. This is of particular concern, as the current leanings of policy-makers appear to place the importance of copyright protection over fair use and the public interest. The ongoing development of law and technology related to copyright control should be an area of ongoing concern and attention for the digital library community. The library community is already active through organizations such as the Association of Research Libraries and the American Library Association. Communities of interest in the development of a national digital library for math, science, and engineering education must participate in this effort to ensure that their unique interests are maintained.
The evolution of legal protection of intellectual property can not be anticipated. Change initiatives are under way in the United States and internationally, where efforts are under way to rationalize the heterogeneity among national systems. Beyond this uncertainty, different information providers will continue to have varying needs and values related to what is proprietary and under what conditions they are willing to share material. These factors speak to the development of a decentralized system, which will allow information providers to manage their
own intellectual property in a manner that best meets their own objectives. The virtual nature of the medium means that users may be indifferent to or even unaware of the distributed nature of the resource and allows content developers and owners to control the presentation and use of their material. The World Wide Web is a powerful enabler of this type of self-publishing. It provides a common interoperable platform for sharing information objects. The web is a highly functional tool for providing access, but does not yet include widely available tools to support robust control of information access and use. Mechanisms for authentication, authorization, payment, and control of copying are critical to expanding the availability of high-quality content online. Market pressures for electronic commerce are pushing the development of these capabilities. Rather than pursue independent solutions to these problems, NSF should encourage participation in ongoing efforts to ensure that they address the needs of the digital library community. Such an approach offers a higher likelihood of success than an independent solution, as it brings larger market forces to bear on accelerating the development and adoption of the tools. Tool developers will be encouraged by the larger market prospects, and users will potentially be able to apply their tools and skills across more functions. A danger in the development of a digital library system closely linked to the world of electronic commerce is highlighted by early case law which questions the applicability of fair use provisions in an environment which supports reasonable mechanisms for payment. 4
Content Development
Success of the digital library will rely on creating a system that provides sufficient incentives to foster the development of high-quality material and to gain sufficient participation from members of the disciplines to review material as part of the quality process. Incentives are both financial, in part related to legal and technological mechanisms for managing intellectual property, and professional, including benefits that enhance career and reputation. These type of incentives are more difficult to create in the digital environment, due to the reduced barriers to publishing and participation. Key questions in addressing this issue are who will pay for quality control and access, and what will be the roles of the disciplinary societies. A successful incentive system, as with other aspects of the digital library, must recognize and be linked to core values and institutional processes of academic professional life.
Market elements necessary to support content development and availability include standards to support modularity and systems for protecting and accounting for use of the learning modules.5 Modularity refers to the ability to move objects—lesson plans, training programs, simulations—across different technical platforms and learning environments. Modularity is relatively easy and established for text and images. It is more difficult for more complex objects, such as simulations and training modules.
Pricing
Information infrastructure and the digital library as part of this larger phenomena, poses a serious challenge to traditional pricing models for information goods. In the physical library, multiple copies of journals and other resources are required to support multiple users in many different locations. In the digital world, one copy can be costlessly reproduced to serve infinite users in infinite locations. As in the print world, a tension exists between making resources as accessible as possible and providing incentives (not always financial) to knowledge providers to generate and make information available. One approach to lessening the tension is to develop and promote means of price discrimination to allow the capture of high rents from those that value early or otherwise differentiated access and low or no price for those with less urgent needs. Economic modeling has demonstrated that such schemes may capture both higher aggregate rents for information providers and higher total utility for users, depending on the demand and supply characteristics of the market. 6
|
4 |
American Geophysical Union v. Texaco Inc., 802 F. Supp. 1 (S.D.N.Y. 1992), and American Geophysical Union v. Texaco Inc., No. 92-9341, 1994 WL 590563 (2nd Cir. Oct. 28, 1994). |
|
5 |
See Brian Kahin, Making a Market for Advanced Distributed Learning, unpublished working paper. |
|
6 |
See Hal Varian, Versioning Information Goods, <http://ksg-www.harvard.edu/iip/econ/varian.html>. |
Evaluation and Feedback
Evaluation includes two elements—evaluation of the infrastructural elements of the library and of the content to which the library provides access. As a new medium for learning and communication, there is a great deal that is not known or understood about the use of digital libraries. Like all new media, it is impossible to anticipate the uses that may evolve for the library. An ongoing process of evaluation and user feedback will be essential to capturing the potential benefits presented by the library. This process should include assessment of the user interface, usefulness of content, utilization, and impact on the learning process. It should also contain an element of flexibility to capture unanticipated areas of concern or opportunity.
A standard search of the World Wide Web demonstrates that identifying useful material in a large distributed network may be difficult. For example, an Internet search for "molecular biology" currently yields 51,562 sources, including links to a German telephone book and the "McCoy family" home page. Systems for content evaluation must not only ensure the availability of high-quality content, but must also be linked to searchable structures that respond to context specific requests. Users must be able to request materials based on the level of knowledge, the teaching model, the budget constraints, and the type of tool. As described above, evaluation relies heavily on the participation of recognized members of the disciplines and success will require a system that includes incentives to satisfy their professional objectives.
Evaluation of digital content will be required to categorize and identify works based on criteria such as quality and targeted educational level. It is also necessary to provide a broadly acceptable means of bringing professional recognition and reward to the development of high-quality digital work. If publication in digital form is not linked to opportunities for professional achievement, it will only evolve as a secondary medium. Such evaluation must be conducted by or at least recognized by the traditional disciplinary societies. Conducting this evaluation on an ongoing basis is a highly intensive effort. To encourage participation by leading luminaries who can shine distinction upon contributors of seminal work that occurs in digital form, NSF and the Academy should consider developing a fellowship (or similar) program that brings recognition to participants in the evaluation process.
Related Initiatives
Many of the issues raised in this paper are currently being explored in a variety of research and policy settings. These include the 6 NSF/ARPA/NASA funded consortia focused primarily on technical issues; 7 the Benton Foundation, the Council on Library and Information Resources, and Libraries for the Future among others. Though these activities are not explored explicitly here, they represent potentially important linkages for NSF and others in the development of digital library infrastructure.
The Role of NSF
As an element of the larger information infrastructure, digital libraries will rely on tools, systems, laws, and regimes developed for a wide array of applications, including but not limited to digital libraries. Ensuring that the particular requirements of digital libraries are addressed in the development of these supporting structures is critical to fostering a robust sub-infrastructure for libraries. As such, NSF should support the digital library research community in the development of the unique technical features that the library will require and in participation in related technical standards bodies and public policy debates. NSF support includes fostering public policy research in the implications of various legal and technical approaches to intellectual property rights management and their impact on publishing and fair use. The Foundation should also ensure that the library is developed in a manner that recognizes opportunities to improve the overall learning and research processes and embraces the necessary institutional mechanisms to affect these larger functions.
College teaching will not drive the development of the standards, technology, and products that will support digital libraries and electronic commerce. Any effort to develop a national digital library for undergraduate education as a unique and isolated resource will fail. The changes required in the larger undergraduate environment to realize the full
benefits of the digital library may be beyond what can now be achieved through an NSF initiative. In light of this, NSF should consider a modest program, which would be intended both to stimulate development of library functions and build the institutional awareness necessary to allow eventual change in the learning process. One model for such an initiative would focus on the development of a web-based index or registry of materials to support undergraduate learning. The primary audience for this resource would be teachers. It would include links to both formal (approved) and informal (self-selected for inclusion) materials. Since the site would not be a repository, it should employ a method of authentication, probably through the use of simple encryption (similar to PGP software), to ensure that users locate the exact item they are referred to by the library. Potentially the largest problem posed by such an initiative is evaluation to ensure that there is a critical mass of approved quality material available. As described earlier, this evaluation process should initially be linked closely to the disciplinary societies to instill confidence among users.
The registry is an identifiable and understandable resource that can serve as a defining centerpiece for the initiative. Other supporting elements to which NSF funding could be applied include: bringing existing federally funded resources online; development of new content, such as pedagogical tools; new technological development to support functions such as expanded search features, platform portability, and intellectual property protection; and, needs assessment to determine how the digital library can best improve undergraduate SMET.
Some Technical and Economic Issues in the Design of a National Library for Undergraduate Science, Mathematics, Engineering, and Technology Education
Clifford Lynch
Executive Director
Coalition for Networked Information
Introduction
This paper briefly summarizes my view of some of the key issues that would be involved in designing a national digital library to serve undergraduate education in science, mathematics, engineering and related fields. It also tries to emphasize unique characteristics of such an undergraduate-focused library which differentiate it from many existing digital library research efforts, such as those being carded out under the auspices of the ARPA/NASA/NSF Digital Library program. The paper ranges widely over technical, economic, content, and user issues: at this early stage in the conceptualization of such an undergraduate library it is very difficult to separate the issues cleanly or to understand how choices in one area will dictate requirements and approaches in others.
A Library in Support of Education
A library targeted to serve undergraduates in science, engineering, mathematics and related subjects (and their teachers) is primarily an engine for enhanced teaching and learning rather than an opportunity to transform the broad system of scholarly communication and publishing. In these disciplines, textbooks have traditionally been the primary materials used by the majority of undergraduate students, rather than the general body of scholarly literature. There is a great deal of emphasis on problem sets and the techniques of problem solving; in some disciplines laboratory work and the analysis of experimental data is also important. In my view, much of the challenge here is how to supplement, extend, and enhance traditional textbooks and related educational materials (such as problem sets or experimental exercises) in the digital environment. Other than reserve materials, undergraduates in mathematics, many sciences and many engineering disciplines are not typically heavy users of library collections—at least when compared to their peers in the humanities and social sciences.
The economics for investing in sophisticated multimedia content are unusually favorable in this environment. Nationally, a huge number of students take undergraduate courses in mathematics, science, and engineering every year (in comparison to advanced graduate courses focused on the disciplinary research frontiers and based closely on an ever evolving research literature). Further, the syllabus for a course like introductory calculus, physics, or biology simply doesn't change a great deal from year to year. This means that investments in content can be amortized over large numbers of students and relatively long periods of time. There is a tradition of passing the costs of most instructional materials—textbooks and lab fees—directly back to the student, so to the extent that a digital library can replace expensive textbooks or the ever more expensive use of laboratory facilities, a funding source to help with ongoing operations already exists.
It would be very useful, in examining the ease for an undergraduate digital library, to compile data about the number of students per year that take various undergraduate science, engineering, and mathematics courses, and also to gather some data about the distribution of textbook use in these courses—for example, how many of the students taking first year calculus use one of the five most popular textbooks? How often are new editions of these textbooks issued? Correlating this information, particularly in conjunction with an identification of courses that many students find particularly difficult, might help to identify high-priority targets for content in the undergraduate digital library.
Because of the large number of students involved and the relative stability of many of the courses, this also seems like an excellent context to try to assess and document the extent to which the digital library and its content actually improve the processes of teaching and learning. An interesting issue with an undergraduate-oriented digital library in the sciences and engineering is its need to justify its value early in its lifecycle: when one considers a digital library of esoteric
scholarly materials, there are many institutions that will immediately derive value from the availability of such materials, because they do not have them in print (as has been the ease with some of the Journal Storage Project [JSTOR] subscribers, for example). An undergraduate digital library primarily focused on instruction is going to be clearly positioned as a substitute—or at best a supplement—for currently available textbooks and related materials almost everywhere it will be used, and must quickly convince its user community that it offers real added value.
Content and Function
Content for such a digital library would include not only electronic versions of textbooks, but also solved and unsolved problem sets, courseware modules (drills, simulations, models, virtual lab benches, and class presentation materials), focused educational literature covering optional topics that extend syllabi, and some limited amount of carefully selected scholarly literature. It should be possible to rather quickly establish a critical mass of materials for the users of such a library, which is all important for achieving acceptance of the service. The nature of an undergraduate library of science, engineering, mathematics, and technology is that is should be highly focused and there should be broad consensus on at least its core content. Further, it need not, and is not intended, to replace existing print or digital research libraries but rather to complement them, and it is perfectly reasonable to assume that a relatively small number of requests for primary scholarly literature will have to be passed beyond the boundaries of the undergraduate library to the broader existing research library system.
Clearly, there will be a need for some type of editorial quality control process to manage submissions to such a library. There will be other problems that are unique, however: for example, how to organize material such as problem sets and courseware modules that can be repurposed at a very fine level of granularity in order to facilitate such reuse. Projects such as the National Engineering Education Delivery System (NEEDS) within the NSF-funded Synthesis Coalition have been struggling with these problems for almost a decade, and it is clear that they are difficult.
Standards to ensure wide usability of the electronic content and to permit the management of this content across time will be a critical issue. While there has been a considerable amount of convergence to a very limited number of standards for electronic print journals (Portable Document Format, and SGML, in particular) the kinds of supplementary multimedia and courseware materials in such an undergraduate digital library are likely to continue to push the state of the art for some time, and to be particularly vulnerable to problems of competing standards and closed software solutions. Obtaining consensus about standards and best practices among the contributors to this system on an ongoing basis will be vital to its success.
Another issue is whether the primary user community will be teachers or students. I believe that it properly should be, and will be, students. To the extent that students are the primary users, not only will a much larger-scale system be required, but the system will also need to address questions about who can see what materials—for example, can students review answers to problem sets as well as the problem sets themselves? If the primary users of the system are students rather than teachers, we must also consider whether only students within recognized institutions of higher education will be allowed access, or whether use of the system will be extended to gifted high school students, independent adult learners, and other groups. There are some central questions here about system architecture, and the roles and responsibilities of various parties in the operation and use of the undergraduate digital library. One can clearly imagine some sort of national repository that is coherently managed as forming the core of the library; but will institutions load and tailor materials locally for use by their student populations or simply prepare user profiles that allow their students to make direct use of the one national system. (Note here that the term national need not imply centralized; the computing facilities may be distributed but the point is that they are managed in an organized, coherent fashion for the benefit of a national user community.)
We will need to understand how students and teachers interact through the undergraduate digital library. For example, as electronic “textbooks” are freed from the tyranny of page limitations and become even larger and richer than they are at present (note that it is very common today for a teacher to chart a path selectively through a textbook for his
or her class rather than using the entire text cover to cover) teachers will want to tailor selections of materials—perhaps not just from one huge text but from a selection of texts—for students in a particular class. How such views of the digital library's content are tailored and managed, and the extent to which users of the library are kept within the boundaries of these views are important design questions.
An issue that requires careful, discipline-based analysis is the extent to which instructional material needs to be supplemented by professional literature and reference materials. Some work has already been done in this area for engineering in the work a few years ago on the design of the National Engineering Library (NENGIS), where materials such as patents and standards were identified as important materials that might be used alongside textbooks and the professional literature in engineering education.
Simply digitizing printed textbooks will not be very useful; rather textbooks need to be reconceptualized and redesigned for the digital environment. Facilities that permit students to compare expositions of a topic from multiple textbooks, or to explore optional topics in more depth than current textbooks can offer, are likely to be particularly valuable. The ability to integrate access to remedial as well as more advanced material will also be very important; this would allow a student with gaps in his or her preparation to learn the required material in a more integrated fashion. It will also be important to establish and clearly articulate some operating assumptions of this digital library very early in the planning cycle. For example: Is the digital library intended to supplement or replace printed textbooks? Is most of the material in the digital library going to be printed prior to use (in other words, will it act largely as a materials identification and distributed printing system)? Is the system primarily to deliver content, or is it actually an interactive educational system where students can, for example, complete homework assignments or tests and submit them for grading (either by computer or by the human instructor)? To what extent would an undergraduate digital library incorporate specific communication and collaboration tools, as opposed to sharing a common network technology and infrastructure with them? (Note that the broader the functionality of the digital library, the more likely that technologies embodied within it will be at odds with other institutional information technology choices and strategies.)
Economic and intellectual property issues surrounding content in an undergraduate digital library are likely to be very different that those arising in research digital libraries. Articles (or even monographs) that are part of the research literature almost never generate any meaningful revenue for authors. Authors publish in these venues to communicate with colleagues, and to obtain recognition for tenure and promotion. Textbooks, on the other hand, represent real revenue sources not just for publishers but also for authors. The economic structures for developing content in an undergraduate digital library need to recognize this difference. If we are ever to develop models for managing digital intellectual property in the academic context which reward authors financially, an undergraduate library for instruction is one of the few environments where there is actually existing precedent.
Infrastructure Requirements
The majority of use for a research-oriented digital library is likely to be concentrated in at most a few hundred institutions; for many disciplines the numbers will be considerably smaller. A digital library designed to support undergraduate education in the sciences, mathematics, and engineering will likely be relevant to thousands of institutions in the United States (even excluding the widely scattered gibed high school students who might well gain great benefit from access to such a system).
Full benefit from the investment in an undergraduate digital library requires that all of the user institutions have adequate network connectivity—and, equally important, adequate local information technology infrastructure and competence—in order to make use of the resource. Because it is likely that much of the content of the undergraduate library will involve interactive multimedia, high bandwidth connectivity will be required even to relatively small institutions. Current programs such as the EDUCOM-led Internet 2 effort or the federal government's Next Generation Internet (NGI) program will ensure that the major research universities have sufficient network connectivity to exploit such a resource, but don't do much for the rest of the institutions that might make use of the system, such as the huge number of community colleges.
Large numbers of workstations will also be required at the institutions that use the system, since many students will need to interact frequently with
the digital library on a regular and perhaps extended basis. As computer ownership, and the trend to expect individual students to own their own computer, continue to grow, this will be less of a problem—it will not be necessary to massively expand library public access workstation facilities or computer labs to accommodate all of the added use, for example. Certainly the demand for "wired" classrooms of various types will grow substantially.
Non-residential colleges and universities will face a particularly serious access problem: if students at these institutions are trying to use machines at home, it is unlikely that they will be able to obtain network connectivity sufficient to support use of sophisticated multimedia content. The issue is infrastructure to support not just institutions as specific sites, but all members of the institutional communities wherever they learn, and it seems clear that access to high-capacity network access services is going to lag access to computers at least for the next few years.
A sober assessment of the ability of the intended user community to actually exploit the potential of an undergraduate digital library in the sciences, engineering and mathematics is a critical factor in evaluating the viability of the enterprise. It may also shape the design criteria: in the past few years, many of the research efforts to develop advanced content to support learning in the networked information environment have been focused on exploring the leading edge, under the assumption that at least a few well-equipped institutions would be able to utilize the new content immediately, and that experience gained from these institutions would inform the design of the next generation while connectivity caught up for the broader community. These are the wrong assumptions for a broadly-based undergraduate digital library. If a production-oriented undergraduate digital library enterprise (as opposed to a research program in identifying and developing content that may be helpful for undergraduate education) is to be launched, the infrastructure expectations and their design implications for content need to be carefully, and clearly, articulated, and periodically revisited in light of developments in the networking industries.
Conclusions
An undergraduate digital library to support science, engineering, mathematics, and technology education seems to be an extraordinarily attractive environment to explore ways in which sophisticated digital multimedia and networked information can enhance the processes of teaching and learning. It is important to recognize that terming it a "library" is somewhat misleading, however: rather than competing with or potentially supplanting the profoundly endangered system of scholarly communication which is the provenance of research libraries, it will complement or supplant the relatively healthy industry of textbooks and instructional materials. In scholarly communication, the introduction of technologies such as multimedia further stress the economies of an already deeply stressed system; in support of undergraduate instruction, to the extent that it can be demonstrated that multimedia improves the educational experience, the economics are more favorable.
Recognizing that an Undergraduate digital library for science, mathematics, engineering, and technology will be a new complement to, rather than competing with, existing research libraries (which manage, and will continue to manage, both print and electronic content) also underscores the need to explore and understand the relationships with the existing library base, and how linkages can be established between the undergraduate digital library and the evolving research library system both at the intellectual and technical levels. It also seems clear that the team needed to develop such an undergraduate digital library will be somewhat different in composition from those leading the development of more research-oriented digital libraries; while it will certainly require librarians, information technologists, and faculty to work in partnership, the focus on education will mean that author-educators will need to take a leadership role.
Readiness factors on the part of the user community need to be carefully considered. Given the broad-based constituency for undergraduate education, the market failure to date in broadband network services to homes and small businesses is of critical importance, Until this market failure is corrected—either through the widespread availability of cable television-based Internet access or through product offerings from the traditional common carriers or other sources—such a digital library in support of education will only be able to reach a relatively small part of its constituency.
Basic Issues Regarding the Establishment of a National SME&T Digital Library
Francis Miksa
Professor
Graduate School of Library and Information Science
The University of Texas at Austin
Establishing a national SME&T digital library as outlined in Jay Labov's Project Summary appears at first glance to be a worthwhile and feasible prospect. We generally associate the ideas of education and libraries closely and, therefore with respect to undergraduate education in science, mathematics, engineering, and technology, it would appear natural not only to conclude that the proposed library would be a welcome resource but that an electronic digital library would be an especially useful innovation. However, upon examining the prospect of such a library more closely, trenchant issues arise in all four of the areas of concern that Labov has listed. The purpose of this paper is to raise questions related to the first three of the areas, and particularly with respect to how the idea of a library intersects with them. The first sections below are related loosely to his first area of concern—education and pedagogy. The middle sections below are related generally to the intersection between second and third areas of concern—content and technical issues. And the last sections below are related more specifically to his third area of concern—technical aspects of the proposed library.
Educational Objectives
Labov states in his "Project Summary" that the purpose of the national SME&T digital library will be "to provide a comprehensive, dynamic, and readily accessible and searchable collection of high-quality educational material in undergraduate science, mathematics, and engineering that is intended to facilitate and enhance the NSF's programs to improve and evaluate undergraduate teaching and learning." (p. 1) This conclusion is based in turn on several observations about the growing impact of digital libraries, not only in the realm of research in various fields, but also in terms of how education is changing at all levels because of information technology and the availability of electronic information resources. As a result he is able to offer the hope that "Digital libraries also might benefit the scientific, mathematics, and engineering communities that are engaged in higher education." (p. 4)
It strikes me, however, that this kind of hopefulness must contend with the formidable reality that undergraduates in the sciences appear to use only a relatively limited range of library resources in their educational work. They are much more dependent instead on textbooks and manuals which they purchase, laboratory work and information resources, and classroom demonstrations and explanations from instructors. There are good reasons why this appears to be so, mainly related to the need in the sciences to learn basic routines, methods, algorithms, and the like, and to demonstrate having learned such things through laboratory work and testing. What does not seem of as much significance is the independent exploration of information resources of the kind usually associated with a library collection. This conclusion was given expression for me in an unpublished study pursued by one of my doctoral students on library use related to the area of mathematics. The student found little evidence that the sizable and comprehensive mathematics collection at the University of Texas at Austin was needed by the general population of undergraduates in mathematics. Rather, it was used mainly by professors and graduate students in mathematics who were engaged in research. A very small number of the most advanced undergraduates did do some independent exploration in the collection. And there was some use of the mathematics collections by undergraduates, graduate students, and faculty from areas other than mathematics, and even many from the sciences. But, all things being equal, their use amounted to a small part of the whole.1 In sum, an extensive collection of
materials in mathematics was valuable for various populations on campus, but least of all for undergraduates in mathematics.
The foregoing conclusion is bolstered in an offhanded way by research on the rise of modern research over the past century. Generally, over the past several decades scientific and technological researchers have tended to use a relatively narrow range of information resources associated with library collections. This is especially true in cases of highly active and vibrant research fronts. Rather, such researchers are much more likely to use materials generated apart from library storage (for example, data archives or data generated from programs working on such data archives) and information gained through informal channels. When library resources are used, there is a strong tendency to limit materials to only those that are very recent and to those that are very specific to their particular projects.2 To sum up, there would seem to be significant data that show that extensive library collections in the areas covered by the proposed library do not have a very close correlation with undergraduate education. Rather, the correlation is with graduate education and established research although even there library collection use has certain limitations and constrictions. If this is so, of course, then the idea of the proposed library might seem to be questionable.
Now, one may take issue with the foregoing conclusions in three general ways. First, we could simply question the observations of low undergraduate use of library materials until better data has been compiled. Second, we might assume that the proposed library will collect those kinds of materials that simply haven't been associated with traditional libraries—for example, special data collections, data archives, or data generated from active research, and so on. Third, we might simply pursue a different approach altogether, justifying the proposed library as a necessity to what is hoped and planned to be a basically new and different approach to undergraduate education in the sciences in the near future.
The latter approach appears to be implied in Labov's association of the proposed library. with "innovative, research-based educational practices and materials" (p. 5). He, and one supposes others as well, appear to imply that a new and different approach to education in the sciences will be helped in its evolution by the sheer availability of electronic information resources, regardless of whether text and paper-based as associated with traditional libraries or of some new variety. Given the evolution of such a new educational process, the proposed library will be not only of inestimable worth but also extensively used.
This new approach to undergraduate education in science, mathematics, engineering, and technology would join with all other areas of education that are currently developing educational processes that include extensive individual exploration and discovery by undergraduates and extensive use of interactive multimedia. In these processes, not only would information resources of all kinds be used extensively and interactively, but undergraduates would learn to creatively prepare and publish their own findings.
Given the latter, not only could a case be made for the proposed library, but some guidance is offered as to what the library might contain. In the latter respect, one important point to be made is that regardless of how undergraduate use of information resources change, it may well be that the chief users of the proposed library will not be undergraduates themselves or at least not undergraduates in large numbers, but rather will be the teachers of the undergraduates. In this case, the library might major on making teaching materials available, especially those in interactive multimedia format, or materials and interactive instructions on how to prepare such materials. 3 Or, as an alternative, it may be that such interactive teaching materials will exist much like presently published textbooks, methods and materials
available for those teachers who wish to use them or for those people, undergraduate or not, who wish to use them in order to explore topics in the SME & T areas independently of formal educational processes.
Given the foregoing considerations, it would seem imperative that at a minimum answers to the following questions be sought.
- What kinds of information resources are presently used by undergraduates in their educational work in science, mathematics, engineering, and technology, and how are such information resources used?
- What kinds of information resources are presently used by teachers of undergraduates working in the areas of science, mathematics, engineering, and technology, and how are such information resources used?
- To what extent and in what manner will a new approach to undergraduate education in the sciences engage students in independent discovery, analysis, and creation of knowledge which will be dependent on information resources collected in a digital library?
- If a new educational process is envisioned for undergraduate education in the sciences, what kinds of educational materials will it require for both students and teachers?
Libraries and the Educational Process
Libraries have typically been thought of by those outside of their care as something akin to an inert mass of information-bearing entities. This is most likely the case because the obvious physical and structural characteristics of libraries make it difficult to see much else. This view of a library is further exacerbated by a view of information which treats it as inert "stuff," rather like series of encapsulated character strings or byte-sequences that are ready for plundering in some useful way. But, the fact is that a library at its core is a part of a complex communication process involving creators of information-bearing entities on one end and users of such entities on the other end (not to mention an entire range of other persons distributed between these two ends of the continuum who add value to the informational collections in order to help make them usable or who function in an interpretative and instructional way in relationship to the content of the entities found in the library).
Ultimately, a very useful view of a library is that it occupies a point in time and space not simply where people "retrieve packages of information" but where they interact with it and its creators as "reorganizers" of the content of what the library contains. The process of reorganization is a complex social process that ultimately lies at the basis of the growth of social knowledge. The social process of reorganization, described in provocative detail in two works by Patrick Wilson (Wilson 1977; 1983) applies to all who use the library, although not all will contribute to the process in the same way or with the same intensity. The point to be made here is that what occurs makes the idea of a library into something of a "living" structure rather than merely an inert mass of information-bearing entities.
Those who have the most effect on the collections ultimately are those who contribute their own knowledge to it. We ordinarily think of that activity occurring at the end of an involved publishing process, carried on by people who have become accredited in some particular discipline or field of knowledge, and whose work is submitted to critical evaluation by some sort of refereeing process. However, a digital library by its very nature participates in a radically revised realm of publishing, one that often circumvents the kinds of processes that have been fundamental to higher education and libraries associated with higher education in the past. Doubtless, were a revised approach to education of undergraduates in the sciences to be pursued, one that is interactive and involves independent exploration and creativity on the part of undergraduates, it would be highly likely that undergraduates would be both interested in and able to contribute to the body of knowledge that the library contains. It may even be that they should have this goal set for them as part of their education. This would obviously make the national SME&T digital library into something very different from a traditional library. Certainly, it would make the library proposed here an even more dynamic and "living" entity than is usually associated with the idea of a library. Were the proposed library to be viewed in this way, the following question might need to be considered.
- What provisions will the national SME&T digital library provide for the interaction and contribution of students to the library as both a passive knowledge base and a "live" publishing venture?
Education, Libraries, and Information Literacy
One of the most interesting developments in the information age has been the discovery that the delivery of information is often hindered not because of any reasonable fault of document retrieval systems or any fault in the selection of what is in a library, nor even because the users of a library are not conversant with some particular method of retrieval. Rather, information delivery is hindered because of the much more fundamental problem that users often do not know either that they have information needs or how they might satisfy such information needs once they have become recognized. And even were they aware that they have such needs and even that a given information source exists for a need, not all such persons have the capacity to use such information sources. The issues of how people recognize information needs and, given that recognition, how they handle the information-seeking process, is generally the province of people who investigate "information literacy."4
With respect to the need by undergraduates for aid in the use of a library and the use of its materials, none of which is automatic, a successful library of the kind proposed here might well consider the use of information ombudsmen who act as facilitators of "information literacy" (not simply computer literacy) in an electronic context (Miksa 1989). Aid in achieving information literacy may also well have to be done as a "remote" facility of the library.
- What provisions, if any, will the proposed national SME&T digital library have for dealing with information illiteracy?
- What provisions, if any, will the proposed national SME&T digital library have for what traditionally has been called "reference work" in libraries?
Library Content—Conflicting Demands
Academic libraries, along with all libraries which serve heterogeneous communities of information users, commonly face conflicting demands with respect to what they are to "acquire" in the way of information resources (i.e., "link to," possibly, in the context of a digital library). One such need is that of supporting research with the very latest texts and other informational materials in a wide range of languages. (Of course, this supposes that the library will be a research support collection at least in part.)
Another need is to provide essential materials for those academic institutions that cannot by themselves afford them—for example in the same manner that the "Texshare" program in Texas supplies electronic information resources for schools in South Texas. In reality, the idea that a library exists in part to supply materials that some users or user communities cannot afford has been a basic part of the "modem library" since its beginnings late in the nineteenth century. In this respect, in fact, the modem library has always represented a kind of economy of scale, where a single library suffices more or less for a large number of persons who individually could not afford what that library collects (Miksa 1996).
A third need is to support the needs of individuals apart from the needs of a larger group—that is, in modem terms to engage in "demand-driven acquisitions," where some resource is gotten for an individual client of the library regardless if any other client needs it. A final need is for a library of the type proposed here to include to an extent well beyond what has been the practice in the print library realm the instructional materials needed by the SME&T faculty—that is, that huge variety of interactive multimedia instructional materials that promise to attend SME&T education in the coming years.
Any close examination will quickly reveal that these four goals often operate at cross-purposes. For example, acquiring material for a group will regularly be in conflict with demand-driven acquisitions, any collecting of research materials will be in conflict with collecting basic materials for elementary curricular needs, and any collecting of instructional materials will often conflict with both research
and elementary curricular needs, especially when funding is limited. If this aspect of a proposed SME&T library is to be adequately broached, the following questions might well need to be raised.
- Who will set the goals of what the national SME&T digital library should contain?
- What information user groups needs will be served, and in what order of priority?
The Idea of a Library—Value-Adding Roles
It seems incumbent that the library proposed here be invested with a viable administrative and operational infrastructure as well as a viable technological infrastructure. As already implied, a library (any library, including one that is "digital") is more than a warehouse or dumpsite of information that is merely delivered. It is more than simply a collection of inert packages of information represented by bits and bytes that are merely shuffled about. It is more than a publishing venture at the head of which is an editorial staff that can decide what to publish or send off merely by market studies. In short, it is not merely a disinterested operational structure with some sort of a simple delivery system for the people who come to it. It is instead a complex operation of selecting, acquiring, organizing, delivering, advising about, etc., information which adds value to the information included in it at every possible point.
The foregoing is the experience learned from approximately 130 years of the "modern" library of print information-bearing entities, the only kind of library that virtually anyone now working on digital libraries of any kind have ever experienced but of which most are not much aware. Were the library being created for undergraduate SME&T education to observe this normative, "enriched" idea of a modem library, the following questions will need to be addressed.
- What value-adding activities must be provided for in the proposed national SME&T digital library?
- Given the answer to question 1 above, what sort of an administrative infrastructure needs to be provided for the library?
Technical Issues—Interfacing with Information Use Styles
It seems obvious that the national SME&T digital library proposed here will encounter a wide range of information use styles, some of which depend on finding bits and pieces of information-bearing entities useful for one's current information need often in some practical or utilitarian way, but others of which focus on identifying and "reading" whole information-bearing entities so as to interact with entire idea-sets of the creators of those entities. In short, sometimes one needs little more than a character string from a text, or from a database, or simply an illustrative photograph, and so on, and that is quite enough. It would appear that this kind of information use is particularly amenable to quick and dirty (or even cleaner, more structured) indexing devices. And it would seem to be served well by some of the more recent ideas for the creation of intelligent agents.
However, others kinds of information seeking do not simply assemble bits and pieces of information, but need and even revel in the retrieval of and interaction with "whole" information bearing entities. Such objects are sought not simply to solve some immediate problem but rather to augment and even to reconstruct one's own thoughts and emotions in some creative way. This kind of need requires more than an Alta Vista type search engine. It needs, in fact, the plodding, labor-intensive results of cataloging, where information-bearing entities are not simply categorized for searchers to find potentially useful groups of items, but also carefully described so as to identify them uniquely and thus to promote efficient "known-item" searches. It needs, in fact, the capacity for a person to look for and precisely find individually created "works" even when they are buried in other collections of information-bearing entities. Should this wide expanse in information use be recognized in the proposed library, then some attention must be paid to the following questions.
- What provisions will be made in the proposed national SME&T digital library for listing information-bearing entities "included" in the library (as well as the "works" they contain) in such a way that such entities and works can be specifically found?
- Given the answer to question I above, what attempts should be made to adhere to nationally adopted standards of cataloging and indexing?
The Library as an Intellectually-Structured Space
One mark of a library, regardless of whether it is of the traditional kind or digital form is that the materials that it includes are organized in terms of an intellectually cohesive and structured "space" (Miksa and Doty 1994). Much is made these days of "intelligent agents" and automatic indexing and retrieval devices that will somehow remove the bottleneck of human intervention in the information storage and retrieval process. The quest for this kind of automatic approach to human information organization and retrieval began with the beginning of the computer revolution and has tended to be kept alive especially by the aforementioned "inert stuff" view of information.
But, if the history of the West has any lesson it is that information organization needs an intellectual framework (knowledge structure) to achieve its greatest impact in a given cultural context. Further, applying such a structure to massive collections of information-bearing entities is a labor-intensive human endeavor that has not yet been successfully made into an automatic routine. (It may someday be accomplished and therefore attempts to solve this trenchant problem should not cease. However, it has not yet been accomplished and that places a particular burden on anyone planning a library of any kind.)
Over the centuries a variety of knowledge structures have been imported into information organization so as to make them into a rational realm for searching and discovery. Although it might be difficult to make a case for applying any given current knowledge structure to the library envisioned here, a case can be made that some such structure is needed. Such a structure need not be rigid, at least from the standpoint of an individual's own homepage base for collecting information links. But, one must have a point of departure for retrieving information from a library for many kinds of information searches and that point of departure will ultimately incorporate knowledge structures. Were the library proposed here to pay attention to this most basic social and cultural need of information organization, the following questions might well be considered.
- What kinds of information retrieval search engines should be employed in the proposed national SME&T digital library.
- What recognition should be given to controlled vocabulary, structured searching environments, if any?
References
Breivik, Patricia S. and E. Gordon Gee. 1989. Information Literacy: Revolution in the Library. New York: American Council on Education.
Dervin, Brenda. 1976. "The Everyday Information Needs of the Average Citizen: A Taxonomy for Analysis." In Information for the Community , ed. By M. Kochen and J. C. Donohue, 19-38. Chicago: American Library Association.
"Development of Technology Integrated Learning Environments: A Report of the Multimedia Instruction Committee, Spring 1995." The University of Texas at Austin. Available at: <http://www.utexas.edu/computer/mic/>.
Farmer, D. W. and Terrence E Mech, editors. 1992. Information Literacy: Developing Students as Independent Learners . San Francisco: Jossey-Bass.
Instructional Technology Connections. (Website) University of Colorado at Denver, School of Education. <http://www.cudenver.edu/~mryder/itcon.html>.
Miksa, Francis. 1987. Research Patterns and Research Libraries. Dublin, Ohio: OCLC.
Miksa, Francis. 1989. "The Future of Reference II: A Paradigm of Academic Library Organization." College and Research Library News 50 (no. 9, October): 780-90.
Miksa, Francis. 1996. "The Cultural Legacy of the 'Modern Library' for the Future." Journal of Education for Library and Information Science 37 (no. 2, Spring): 100-119. Also available at: <http://www.gslis.utexas.edu/faculty/Miksa/modlib.htm>.
Miksa, Francis and Philip Doty. 1994. "Intellectual Realities and the Digital Library." Proceedings of Digital Libraries '94: The First Annual Conference on the Theory and Practice of Digital
Libraries. Eds. J. L. Schnase . . . [et. al], pp. 1-5. College Station, Texas: Hypermedia Research Laboratory, Department of Computer Science, Texas A&M University. Also available at: <http://abgen.cvm.tamu.edu/DL94/paper/miksa. html>.
Wilson, Patrick. 1977. Public Knowledge, Private Ignorance: Toward a Library and Information Policy. Contributions in Librarianship and Information Science, no. 10. Westport, Conn.: Greenwood Press.
Wilson, Patrick. 1983. Second-hand Knowledge: An Inquiry into Cognitive Authority . Contributions in Librarianship and Information Science, no. 14. Westport, Conn.: Greenwood Press.
The Case for Creating a Systematic Indexing System for the National SME&T Digital Library
Francis Miksa
Professor
Graduate School of Library and Information Science
The University of Texas at Austin
Joan Mitchell
Editor
Dewey Decimal Classification
OCLC/Forest Press
Diane Vizine-Goetz
Senior Researcher
Office of Research
On line Computer Library Center (OCLC)
Dublin, Ohio
Abstract
A case is presented for creating a systematic indexing system for the proposed national SME&T digital library. Two sets of assumptions are provided as background, the first having to do with what is “included” in the library's collections, the second with typical factors related to indexing in general. Indexing is defined operationally in a very general way, as making available and using for information searches in the library the attributes of information-bearing entities which the library identifies as members of its collections. The main features of a systematic indexing system include a controlled vocabulary for topical and formal attributes of information-bearing entities, a taxonomic and faceted structure (with notation) of the concept terms that shows relationships among terms, and an alphabetical index to the structure. The idea of the system is illustrated by reference to the Dewey Decimal Classification. A rationale is provided. Its two major loci are how the system supports the undergraduate educational process, and how the system supports searches for materials in topical areas. Finally, after problems are presented for implementing this system are given, questions pertinent to the issues are listed.
Background
For the sake of presenting our approach to indexing the national SME&T digital library we will begin with two sets of assumptions—one that concerns the nature of the library's collection, the other with factors related to indexing in general. First, we assume that the proposed national SME&T digital library will "include" graphic and textual information-bearing entities such as texts, audio and graphic files (or combinations of such entities in the form of multimedia files), databases, websites (which contain still other collections of information-bearing entities), etc., in its "collections." Here, "include" means that such entities are purposefully and intellectually included in what the library considers its realm; and "collections" refers to the sum of such entities included in its realm. It is understood, of course, that in the context of a digital library, "includes" essentially means available in electronic format through telecommunications links.
Second, we assume certain things about indexing itself. Operationally speaking, indexing the national SME&T digital library simply means making available and using for information searches in the library the attributes of the information-bearing entities that the library identifies as members of its collections. This is a very broad interpretation of indexing which includes the widest possible range of systems. Thus, a library catalog is considered an index to a library collection just as a more specifically named indexing service constitutes an index of the periodicals and other items which it includes in its purview.
When this operational goal is implemented, the form that indexing takes is controlled by various basic factors. Some of the most important of these are shown in Table 1.
The implementation of each of the factors listed should be viewed as ranging along a continuum that begins with the statement in column A and proceeds in the same row to column B. For example, an indexing system might include only carefully assigned attributes as found in 1A, or it might include all naturally occurring attributes identified in the entities by some automatic algorithm as designated in 1B; but likely as not a typical system will include some combination of attributes from the two sources. Likewise, an indexing system might carefully segregate kinds of attributes according to
TABLE 1. Controlling Factors in Indexing
some tradition as when traditional library cataloging carefully segregates a name functioning as an author of a document from a name that functions as a subject of a document. Or, again, an indexing system may simply intermix all such functions as in searches made by AltaVista on the Internet. Likely as not, however, a planned indexing system will segregate some attributes from others in order to make the system function more efficiently.
We include this table first of an in order to provide a general framework for considering various important aspects of indexing when considering how the national SME&T digital library might be indexed, and also to offer a way to distinguish existing indexing approaches. With respect to the latter, for example, traditional library catalogs as they evolved from the late nineteenth century to about the 1950s can most readily be associated with column A of the table. However, as library catalogs have migrated to a computerized context, they have tended to move in some respects toward column B. This is especially evident in various efforts to enhance controlled vocabulary subject heading systems in online public access catalogs by automatically incorporating natural language keyword searching on terminology used in the bibliographic records for individual entities listed in such catalogs. One thing is certainly true with respect to indexing that follows many of the provisions of column A, that is, that it tends to be labor-intensive and, therefore, costly.
In contrast to the foregoing, much of the research done in the realm of information storage and retrieval systems over the past four decades has tended to be identified with column B in the table (cf. Belkin and
Croft 1987). One reason for this is that the provisions of column B are strongly related to tapping the computer's capacity to engage in automatic routines. This has generally been viewed as a necessity in order to break through what has been considered the labor-intensive and costly "bottleneck" of indexing under the provisions of column A. Recent efforts to combine derived indexing methods and the information ordering capabilities provided by established classification schemes are being reported with increasing frequency (Programming Systems Research Group, 1996; Koch and Day, 1997; Thompson, Shafer, and Vizine-Goetz, 1997; Weiss et al., 1996).
The second reason for including the foregoing table of indexing factors is to provide a framework for identifying what this paper advocates—that is, that regardless of any other indexing approaches which might be taken for the national SME&T digital library, one that should be seriously considered is indexing the library according to a systematic, logically related structure of controlled vocabulary index terms for the topical and other relevant aspects of the information-bearing entities included in the library. This kind of a system will adhere at a minimum to 1A in the table (controlled vocabulary), 3A (for topic, form, etc., attributes), 4A (a systematic taxonomic structure of term relationships), and 6A (a predetermined structure), with extensions into column B on factors 2 and 5. (See shaded areas in the table.) In short, we advocate the creation of a multiple entry classified index for the library. What remains here is to briefly describe such a system and to provide a rationale and other considerations regarding it.
A Systematic Indexing System
A systematic indexing system of the kind envisioned here will adhere to the following provisions.
- It will contain a set of controlled vocabulary concept terms which are assigned to each of the information-bearing entities in the national SME&T digital library—as many for each item as are necessary to highlight useful aspects of each entity—and which are expanded as needed for new entities added to the library. Such concept terms should feature the following attributes of the information-bearing entities when appropriate:
- topicality of the entities (i.e., "aboutness" attributes)
- formal aspects of the entities (i.e., such attributes as "genre," medium, arrangement, formal digital characteristics, etc.)
- other formal aspects of the entities (i.e., those related to "of-ness" of items such as saying what a graphic is "of" rather than "about," or those related to the "for-ness" of items such as saying that an entity has been created “for” such and such an audience or purpose, etc.)
- The concepts so assigned are then arranged in a taxonomic order with heavy emphasis on "faceted" structures such that both indexers and those searching for information-bearing entities with particular attributes of these kinds may be able to use the system as an aid—for indexers in assigning concepts to new items, and for information seekers when constructing search algorithms. Faceting here means grouping like attributes in "families" (not unlike the particular values in any given field in a database) that are highly adaptable for multiple use in different sections of the structure. For the purposes of ease of use, a notation of the system should be attached to the concepts that will "express" the relationships of the concepts and be available as a shorthand way of referring to parts of the system.
- An alphabetical arrangement of the concept terms (i.e., an index to the systematic structure) should be maintained in order for indexers and information searchers to gain access to starting points in the systematic map of concept relationships, but also for searching independent of that structure.
A moment's reflection will show that what is actually proposed is similar to what in the past has been called a "classified catalog." Classified catalogs consisted of three parts: 1) a listing (numerically by notation from the system) of entries representing items in the system in their classified order (any item being represented by as many different notations as necessary), 2) an alphabetical listing of terms used in the system, sometimes with inverted index references to the entries, and 3) an alphabetical listing of items in the system by author, title, etc. Classified catalogs were almost always made as manual systems. More recently, as online public access
catalogs (OPACs) have begun to provide access to items by their library classification numbers, some semblance of classified catalog arrangement has been achieved. It is limited, however, because it generally does not provide multiple representations of any particular item in the system under different class numbers.
The foregoing brief sketch for indexing can be illustrated by envisioning the use of a system such as the Dewey Decimal Classification (DDC) for indexing the national SME&T digital library but with certain variations of the system as now constructed and typically used. The DDC in its present form is a systematic, logical structure of concepts that are assigned to items in a library by attaching the notation representing each concept or combination of concepts to the items. Its structure of concept terms is highly developed, having been modified constantly by including new concepts, modifying old ones, and restructuring concepts over many years by means of a strong, centralized editorial process. It has adopted faceted structures in various places in the system, has a reasonably thorough index of its concepts, and has many other features that cause it to be one of the best such systems for information retrieval available.
What is envisioned here for the national SME&T digital library is using a system like the DDC to index the information-bearing entities that the library includes in its collections. Multiple index terms or term combinations (represented by classification numbers) would be assigned to each entity for each of the various categories of terms noted above. As a result, those who need to search the library will have both the structured system and the alphabetical arrangement of terms available as a way to search the system. In addition, the structured system will also serve as a map of the categories in the system quite apart from specific search needs (cf. Cochrane and Johnson, 1996; Bendig, 1997; and more generally, Iyer and Giguere, 1995).
The purpose for invoking the DDC is not to champion that system in particular, as excellent as it has become, but rather simply to use it as an example of what is meant here. All things being equal, even the DDC in its present state does not yet have all the requirements for fulfilling the goals outlined here, although it has great potential for being able to do so ultimately. For example, the DDC does not have a fully controlled vocabulary of concept terms and does not always differentiate completely between the various formal and other attributes of entities which were described above. It also does not yet use faceted concept structures to the fullest extent possible although these are being incorporated at an increasing rate under the present editorial direction of the system (Mitchell, forthcoming). Finally, the typical application of the DDC in libraries generally follows a "single-entry" approach, where each information-bearing entity in a collection is generally assigned a single concept statement from the system. This follows the common use of the system as a device physically to arrange library items rather than to index them thoroughly. One Internet-based exception is OCLC's NetFirst database which provides access to Internet and Web-accessible information-bearing entities through multiple classification numbers assigned to an entity. (Vizine-Goetz 1997a)
Nevertheless, the DDC is especially adaptable for the present case, and it especially is adaptable for use in an indexing environment with a layered approach to access. For example, keyword access to information-bearing entities in the national SME&T digital library will be one way to approach its indexing needs. However, most people are doubtless aware of the weaknesses of the straight keyword approach. One question this raises is how to blend the keyword approach with the context and relationships provided by the structured approach to improve retrieval.
In the SME&T library, we assume an increasing number of items may be available in digital form. This offers an opportunity to present a layered approach to information retrieval that in many ways represents previous approaches, but in a more efficient manner. Say we have a textbook on machine learning. A general textbook on machine learning is summarized in Dewey under the number 006.31, and in the Library of Congress subject headings by the phrases Machine learning and Computer algorithms. In the index to the book, there is no mention of computer algorithms, but many examples of specific algorithms which may or may not be known to undergraduates. "Machine learning" has just a few entries in the index, but it is the central "about-ness" of the book. An undergraduate may be looking for algorithms for machine learning, with or without knowing the specific name of one. The
summarizing function of the DDC number and subject headings brings one to a promising initial set of documents, the general texts on machine learning. Once in this set, the browse could then move to a keyword search of indexes (back-of-the-book) and browse within those indexes to find a particular algorithm (e.g., backpropagation algorithm).
A bottom-up approach would also work within the same structure—a large keyword retrieval could be sorted and summarized by category using the structure and relationships provided by the DDC and controlled vocabulary. A look at the OCLC NetFirst database will help to illustrate this possibility. Using the hierarchical structure of the Dewey Decimal Classification, a NetFirst user can select from subject categories (such as health, home, technology), topics (such as health and medicine) and subtopics (such as diseases, preventive medicine, and public health) to reduce a results set numbering nearly 14,000 to a more manageable set of 249 records. Further refinements in searching can be achieved by combining one or more terms with DDC topic categories. For instance, a NetFirst user interested in finding electronic resources containing information about health concerns for travelers can browse to the second level topic health and medicine under the category health, home, technology and then search for items in this topic area about travel and tourism. Browsing and filtering the database records in this way (using the structure of DDC but not its class numbers) enables users to retrieve relevant items that may not be as easily discovered using traditional keyword searching capabilities. In this case, a keyword search for health and (travel or tourism) retrieves 143 items; a similar search filtered by DDC topic area retrieves 25 items, with several potentially relevant items included on the first page of the results display (Vizine-Goetz, 1997b).
Rationale
The rationale for indexing the national SME&T digital library with the kind of systematic indexing approach outlined here resides chiefly in two assumptions about how such a library might be used, the first assumption having to do with the educational support the library is intended to provide, the second, having to do with efficiency in searches which focus on surveying an area of knowledge.
Educational support
We assume that the focus of the national SME&T digital library, being supportive of undergraduate education in science, mathematics, engineering, and technology, will need a capability for searching that enhances the ability of undergraduates to engage in the personal exploration of ideas, and that given this need, the indexing system of the library will therefore need to include a broad range of information search types.
We illustrate this broad range of search types by referring to two parts of the taxonomy of kinds of knowledge-information "uses" found in Fritz Machlup's work. He outlined five kinds of knowledge-information uses, of which the first two kinds have special relevance here—the "instrumental" or "practical" use of information on the one hand, and the “intellectual" use of information on the other hand (Machlup, 1980, 107-9; cf. Miksa, 1985).
The first of these two types focuses on the need for (and, therefore, the search for) very specific information found as a result of very specifically defined information searches. This information is often needed quickly, and it is generally needed in order to complete some task, make some decision, etc. This kind of information use and search is predicated in turn on one knowing exactly what is needed and the capacity to generate an information search that precisely meets the information need. It is certainly basic to known-item searching for library items about which one knows some due about its attributes and which one pursues because of the expectation that the item will fulfill one's information need in some fashion. This kind of information use is also basic to searches on topical terms for very specific topics differentiated from other closely related topics. This approach to searching is basic to many of the information storage and retrieval systems created over the past four decades and especially to systems created to serve scientists and other educated researchers who one supposes know when they have information needs and have some skill in stating precisely what they want or need in the way of information.
We assume that while the undergraduate education supported by the national SME&T digital library will necessitate this kind of searching on the part of undergraduates some of the time, the second important type of knowledge-information use designated by Machlup and its corresponding kind of search
type will play an equally if not even more important role. Machlup's second kind of information use, which he called the "intellectual" use of information and which he associated with information gained in some repose for more general educational purposes rather than for specific instrumental ends, is a much less specific approach to information need and searching. It actually amounts to a kind of exploratory approach to information where information is surveyed by categories in a manner that has great likeness to mapping knowledge, often for little more than one's personal satisfaction. Its main emphasis is the mental exploration of ideas and is characteristically associated with the browsing done by students in the stacks of a library where books on various topics are surveyed according to the progression of topics they represent on the shelves, books being pulled and examined often sequentially, with topical hints and ideas coming in a flood from the books themselves, from their association with other books along side them in the same category, and from differences with books in nearby categories.
We assume that this kind of information use and, by extension, information searching, is especially relevant to the national SME&T digital library as a support for undergraduate education insofar as that education will emphasize the exploration of ideas in the form of personal research and exploration rather than the directed research of seasoned researchers in creating new social knowledge. It is precisely this kind of intellectual activity, in fact, that produces the kind of thinking that appears to be fundamental to the national SME&T digital library idea.
If our assumptions about information use are accurate, and we believe they are, then an indexing system is needed for the library that will support this kind of information use and searching as well as the instrumentally precise kind of information use and searching described above. In this respect we conclude that a systematic approach to indexing the national SME&T digital library of the kind we propose will support this need very directly in a way that no other indexing approach can. Our proposed system will do so because it "maps" knowledge categories into a logical structure, and given a system in which such a knowledge structure is available, will promote this kind of information searching to the undergraduates who use it. It will promote and facilitate, in other words, the kind of browsing or exploratory searching described here.
As a caveat, it should be noted that the "mapping" of knowledge relationships in the sense meant here is not designed to be some ultimate and absolute set of knowledge categories and their relationships, but rather merely a beginning point for an information seeker's own personal mapping of knowledge. In short, any such structure constitutes no more nor less than a starting point, concluding that it is in the nature of this kind of mental activity to use such a structure to build one's own personal knowledge structure, redefining and extending the relationships one begins with and which are found in such a structure as needed and not simply absorbing the given structure as absolute. The basis for doing so, however, is that some such knowledge structure is available as a beginning point and that one has the capability of browsing through such a structure with both guidance in its use but also with a good deal of freedom (Miksa, 1997).
Efficiency in Surveying Information
The second reason why a systematic indexing system of the kind proposed here will be useful for the national SME&T digital library has to do with a certain kind of usefulness in searching that is sometimes, but not always, needed in information retrieval but which is hard to come by in other kinds of systems—that is, searching for all aspects of a topic where the aspects are indexed under a variety of names. For example, given a search for various aspects of, say, the realm of Bryophyta, unless one were a seasoned researcher who already knew the classes of plants included in Bryophyta (for example, different kinds of mosses, hornworts, and liverworts) or such various aspects of the study of Bryophyta or any of its subclasses as anatomy, physiology, morphology, ecology, molecular and cellular issues, and so on, it would be much easier to find what a library of any kind had on the area were these all gathered systematically in one place in an indexing system. In short, it would be more efficient for one to see a concept map of the area than simply diving in without a clue about what is included trying to survey it.
Searching for related topics such as these can be done by controlled vocabulary systems such as subject headings if a strong structure of narrower and related term cross-references are available, but such
cross-references ultimately must be derived from a systematic structure of the kind the system proposed here would supply as a matter of course. Not all searches are conducted with this goal in mind, of course, but where they are the system proposed here would expedite them with some efficiency.
Other Considerations
Having hopefully made a case for the need of the kind of systematic indexing system proposed here, we close by pointing out several difficult issues that must be considered in implementing such a system.
- The system proposed here is labor-intensive and, therefore, relatively costly to implement, as is any controlled vocabulary and concept-assigned system. However, there seems at the present time no alternative to it that would yield this kind of a system. Further, in order to implement such a system an organized, managed, and funded approach to the indexing process will be needed.
- Creating any systematic system will bog down if its goal becomes to create what could be called the "one best system" or knowledge taxonomy—a system considered to be "more correct" than any other system. We assume that all knowledge structures are ultimately artificial and capable of growth and evolution. Thus, what is needed is an emphasis on adaptability in such a system where the official version of the system can not only be easily modified, but can be used in whatever modified or "non-official" form one wants for the system without losing contact with the form in which the official version of the system is found.
- Some will claim that a systematic structure of knowledge categories arranged in someone's logical manner will be evidence of little more than what post-modernists such as Michel Foucault and others would consider the blatant exercise of power and authority in the intellectual realm so as to squelch intellectual dissent. We conclude that to the extent that any classification of knowledge categories is at base an information-losing process (i.e., by excluding alternative arrangements, at least in any "official" or basic version of the system), and that the purpose is to provide only one approach to knowledge structure, this objection has some merit. We also conclude, however, that the solution to the problem is not to avoid making taxonomic structures in the first place, or to argue incessantly about what is right or wrong about them, but rather to create a system with malleability sufficient to allow it to be arranged and searched in alternative arrangements, much like one can rearrange the reporting structures of databases.
Questions
We conclude with a list of questions for discussion that arise from the foregoing remarks.
- What indexing implications arise from the meaning of the assertion that information-bearing entities are "included" in the national SME&T digital library and, in fact, from how that process will function?
- What do the educational objectives underlying the national SME&T digital library yield in terms of the information search needs and patterns of the undergraduate users of the library?
- What other users of the national SME&T digital library are expected besides undergraduates in the areas of science, mathematics, engineering, and technology, and how does the expectation of the information use needs of these other information users impact on the indexing of the library?
- What combination of typical indexing factors are necessary and sufficient for the users of the national SME&T digital library?
- If the answer to question 4 consists of a layered approach to indexing, of what should the layers consist?
- What combination of typical indexing factors for the library is both practical and affordable?
- What alternatives to a systematic indexing system of the kind envisioned here are presently available for meeting the information use needs described in the "rationale" above?
- If a presently available system such as the DDC were used for creating a systematic indexing system for the national SME&T digital library, what changes might be recommended with respect to the system and how it is typically applied?
- Which persons or bodies would be given responsibility for indexing the national SME&T digital library?
- To what extent should the indexing needs of the national SME&T digital library provide a test-bed for indexing experimentation?
References
Belkin, Nicholas J., and W. Brace Croft. 1987. "Retrieval Techniques." Annual Review of Information Science and Technology 22: 109-45.
Bendig, Mark. 1997. "Mr. Dui's Topic Finder," Annual Review of OCLC Research 1996. Dublin, Ohio: OCLC. Also available at: <http://www.purl.org/oclc/review1996>.
Cochrane, Pauline, and Eric Johnson. 1996. "Visual Dewey: DDC in a Hypertextual Browser for the Library User." In Knowledge Organization and Change: Proceedings of the 4th International ISKO Conference, 15-18 July 1996, Washington, D.C., ed. by Rebecca Green. Frankfurt/Main: INDEKS Verlag, 95-106.
Iyer, Hemalata, and Mark Giguere. 1995. "Towards Designing an Expert System to Map Mathematics Classificatory Structures," Knowledge Organization 25 (no. 3/4): 141-47.
Koch, T., and Michael Day. 1997. The role of classification schemes in Interact resource description and discovery . [Development of a European Service for Information on Research and Education (DESIRE) project report posted on the World Wide Web.] Retrieved July 29, 1997 from the World Wide Web: <http://www.ukoln.ac.uk/metadata/DESIRE/classification/class_ti.htm>.
Machlup, Fritz. 1980. Knowledge and Knowledge Production. Vol. I of Knowledge: Its Creation, Distribution, and Economic Significance . Princeton, N.J.: Princeton University Press.
Miksa, Francis. 1985. "Machlup's Categories of Knowledge as a Framework for Viewing Library and Information Science History." Journal of Library History 20 (Spring): 157-92.
Miksa, Francis. 1997. The DDC, the Universe of Knowledge, and the Post-Modem Library. Albany, N.Y.: Forest Press, a division of OCLC Online Computer Library Center, Inc.
Mitchell, Joan S. "Challenges Facing Classification Systems: A Dewey Case Study." In Knowledge Organization for Information Retrieval: Proceedings of the 6th International Study Conference on Classification Research, 16-18 June 1997. London. (Forthcoming.)
Programming Systems Research Group, MIT Laboratory for Computer Science. HyPursuit Homepage. [Document posted on the World Wide Web.] Retrieved July 29, 1997 from the World Wide Web: <http://paris.LCS.MIT.EDU:80/Projects/CRS/HyPursuit/>.
Thompson, Roger, Shafer, Keith, and Diane Vizine-Goetz. 1997. "Evaluating Dewey Concepts as a Knowledge Base for Automatic Subject Assignment." Paper presented at 2nd ACM International Conference on Digital Libraries, Philadelphia, Pa., July 23-26, 1997. Also available at: <http://purl.oclc.org/scorpion/eval_dc.html>.
Vizine-Goetz, Diane. 1997a. "Classification Research," Annual Review of OCLC Research 1996. Dublin, Ohio: OCLC. Also available at: <http://www.purl.org/oclc/review1996>.
Vizine-Goetz, Diane. 1997b. "OCLC Investigates Using Classification Tools to Organize Internet Data," OCLC Newsletter (March/April 1997): 14-18. Also available as: <http://www.oclc.org/oclc/new/n226/frames_man.htm>.
Weiss, R., et al. 1996. HyPursuit: A Hierarchical Network Search Engine that Exploits Content-Link Hypertext Clustering. [Compressed file posted on the World Wide Web.] Retrieved July 29, 1997 from the World Wide Web: <http://www.psrg.lcs.mit.edu/ftpdir/papers/hypertex96.ps.gz>.


















































