
Chapter 5
Contributed Session on Confidentiality and Strategies for Record Linkage
Chair: Virginia deWolf, Bureau of Labor Statistics
Authors:
Robert Burton, National Center for Education Statistics
Anco J.Hundepool and Leon C.R.J.Willenborg, Statistics Netherlands
Lawrence H.Nitz and Karl E.Kim, University of Hawaii at Manoa Julie Bernier, Statistics Canada
Using Record Linkage to Thwart the Data Terrorist
Robert Burton, National Center for Education Statistics
Abstract
The traditional goal of record linkage is to maximize the number of correct matches and minimize the number of incorrect matches. Since this is also the goal of the “data terrorist” seeking to identify subjects from microdata files, it makes sense to use record linkage software to thwart the data terrorist.
There are, however, differences between the two situations. At the conceptual level, the relevant loss functions seem quite different. At the practical level, some modifications may be desirable in regard to blocking, assignment, and recoding when using record linkage methods to test the disclosure potential of microdata files. The speaker will discuss these differences and suggest promising ways to use record linkage methods to protect respondent confidentiality.
µ- and t-ARGUS: Software for Statistical Disclosure Control
Anco J.Hundepool and Leon C.R.J.Willenborg, Statistics Netherlands
Abstract
In recent years, Statistics Netherlands has developed a prototype version of a software package, ARGUS, to protect microdata files against statistical disclosure. The launch of the SDC-project within the 4thframework of the European Union enabled us to make a new start with the development of software for Statistical Disclosure Control (Willenborg, 1996). The prototype has served as a starting point for the development of µ-ARGUS, a software package far the SDC of microdata. This SDC-project, however, also plans to develop t-ARGUS software devoted to the SDC of tabular data. The development of these software packages also benefits from the research of other partners in this project. This paper gives an overview of the development of these software packages and an introduction to the basic ideas behind the implementation of Statistical Disclosure Control at Statistics Netherlands.
Introduction
The growing demands from researchers, policy makers and others for more and more detailed statistical information leads to a conflict. The statistical offices collect large amounts of data for statistical purposes. The respondents are only willing to provide the statistical offices with the required information if they can be certain that these statistical offices will treat their data with the utmost care. This implies that their confidentiality must be guaranteed. This imposes limitations on the amount of detail in the publications. Research has been carried out to establish pragmatic rules to determine which tables can be regarded safe with respect to the protection of the confidentiality of the respondents. The well-known dominance rule is often used.
On the other hand, statistical databases with individual records (microdata files) are valuable sources for research. To a certain extent the statistical offices are prepared to make these microfiles available to researchers, but only under the provision that the information in these databases is sufficiently protected against disclosure. At Statistics Netherlands a lot of research has been carried out to establish rules to determine whether a specific database is safe enough to make it available to researchers. In the next section, we will give an introduction to this research. Then, we will go into the development of µ-Argus and we will conclude with an overview of t-Argus.
SDC for Microdata at Statistics Netherlands
Re-identification
The aim of statistical disclosure control (SDC) is to limit the risk that sensitive information of individual respondents can be disclosed from a data set (Willenborg and DeWaal, 1996). In case of a microdata
set, i.e., a set of records containing information on individual respondents, such disclosure of sensitive information about an individual respondent can occur after this respondent has been re-identified; that is, after it has been deduced which record corresponds to this particular individual. So, disclosure control should hamper re-identification of individual respondents.
Re-identification can take place when several values of so-called identifying variables, such as “Place of residence,” “Sex,” and “Occupation” are taken into consideration. The values of these identifying variables can be assumed to be known to friends and acquaintances of a respondent. When several values of these identifying variables are combined, a respondent may be re-identified. Consider for example the following record obtained from an unknown respondent:
“Place of residence = Urk,” “Sex = Female” and “Occupation = Statistician.”
Urk is a small fishing village in the Netherlands, in which it is unlikely for many statisticians to live, let alone female statisticians. So, when we find a statistician in Urk, a female one moreover, in the microdata set, then she is probably the only one. When this is indeed the case, anybody who happens to know this rare female statistician in Urk is able to disclose sensitive information from her record if it contains such information.
An important concept in the theory of re-identification is a key. A key is a combination of identifying variables. Keys can be applied to re-identify a respondent. Re-identification of a respondent can occur when this respondent is rare in the population with respect to a certain key value, i.e., a combination of values of identifying variables. Hence, rarity of respondents in the population with respect to certain key values should be avoided. When a respondent appears to be rare in the population with respect to a key value, then disclosure control measures should be taken to protect this respondent against re-identification (DeWaal and Willenborg, 1995a).
In practice, however, it is not a good idea to prevent only the occurrence of respondents in the data file who are rare in the population (with respect to a certain key). For this, several reasons can be given. Firstly, there is a practical reason: rarity in the population, in contrast to rarity in the data file, is hard to establish. There is generally no way to determine with certainty whether a person who is rare in the data file (with respect to a certain key) is also rare in the population. Secondly, an intruder may use another key than the key(s) considered by the data protector. For instance, the data protector may consider only keys consisting of at most three variables, while the intruder may use a key consisting of four variables. Therefore, it is better to avoid the occurrence of combinations of scores that are rare in the population in the data file instead of avoiding only population-uniques in the data file. To define what is meant by rare, the data protector has to choose a threshold value Dk, for each key value k, where the index k indicates that the threshold value may depend on the key k under consideration. A combination of scores, i.e., a key value, that occurs not more than Dk times in the population is considered unsafe; a key value that occurs more than Dk times in the population is considered safe. The unsafe combinations must be protected, while the safe ones may be published.
There is a practical problem when applying the above rule that the occurrence (in the data file) of combinations of scores that are rare in the population should be avoided. Namely, it is usually not known how often a particular combination of scores occurs in the population. In many cases, one only has the data file itself available to estimate the frequency of a combination of scores in the population. In practice, one therefore uses the estimated frequency of a key value k to determine whether or not this key value is safe or not in the population. When the estimated frequency of a key value, i.e., a combination of scores, is larger than the threshold value Dk, then this combination is considered safe. When the estimated frequency of a
key value is less than or equal to the threshold value Dk, then this combination is considered unsafe. An example of such a key is “Place of residence,” “Sex,” and “Occupation.”
SDC Techniques
Statistics Netherlands, so far, has used two SDC techniques to protect microdata sets, namely global receding and local suppression. In case of global receding, several categories of a variable are collapsed into a single one. In the above example, for instance, we can recode the variable “Occupation.” For instance, the categories “Statistician” and “Mathematician” can be combined into a single category “Statistician or Mathematician.” When the number of female statisticians in Urk plus the number of female mathematicians in Urk is sufficiently high, then the combination “Place of residence = Urk,” “Sex = Female,” and “Occupation = Statistician or Mathematician” is considered safe for release. Note that instead of recoding “Occupation,” one could also recode “Place of residence” for instance.
The concept of MINimum Unsafe Combinations (MINUC) plays an important role in the selection of the variables and the categories for local suppression. A MINUC provides that suppressing any value in the combination yields a safe combination.
It is important to realize that global recoding is applied to the whole data set, not only to the unsafe part of the set. This is done to obtain a uniform categorization of each variable. Suppose, for instance, that we recode “Occupation” in the above way. Suppose furthermore that both the combinations “Place of residence = Amsterdam,” “Sex = Female,” and “Occupation = Statistician,” and “Place of residence = Amsterdam,” “Sex = Female,” and “Occupation = Mathematician” are considered safe. To obtain a uniform categorization of “Occupation” we would, however, not publish these combinations, but only the combination “Place of residence = Amsterdam,” “Sex = Female,” and “Occupation = Statistician or Mathematician. ”
When local suppression is applied, one or more values in an unsafe combination are suppressed, i.e., replaced by a missing value. For instance, in the above example we can protect the unsafe combination “Place of residence = Urk,” “Sex = Female” and “Occupation = Statistician” by suppressing the value of “Occupation,” assuming that the number of females in Urk is sufficiently high. The resulting combination is then given by “Place of residence = Urk,” “Sex = Female,” and “Occupation = missing.” Note that instead of suppressing the value of “Occupation,” one could also suppress the value of another variable of the unsafe combination. For instance, when the number of female statisticians in the Netherlands is sufficiently high then one could suppress the value of “Place of residence” instead of the value of “Occupation” in the above example to protect this unsafe combination. A local suppression is only applied to a particular value. When, for instance, the value of “Occupation” is suppressed in a particular record, then this does not imply that the value of “Occupation” has to be suppressed in another record. The freedom that one has in selecting the values that are to be suppressed allows one to minimize the number of local suppressions. More on this subject can be found in De Waal and Willenborg (1995b).
Both global recoding and local suppression lead to a loss of information, because either less detailed information is provided or some information is not given at all. A balance between global recoding and local suppression has to be found in order to make the information loss due to SDC measures as low as possible. It is recommended to start by recoding some variables globally until the number of unsafe combinations that have to be protected by local suppression is sufficiently low. The remaining unsafe combinations have to be protected by suppressing some values.
µ-ARGUS allows the user to specify the global recodings interactively. The user is provided by µ-ARGUS with information, helping him to select these global recodings. In case the user is not satisfied with a particular global receding, it is easy to undo it. After the global recodings have been specified the values that have to be suppressed are determined automatically and optimally, i.e., the number of values that have to be suppressed is minimized. This latter aspect of µ -ARGUS, determining the necessary local suppressions automatically and optimally, makes it possible to protect a microdata set against disclosure quickly.
The Development of µ-ARGUS
As is explained above, a microdata file should be protected against disclosure in two steps. In the first step some variables are globally receded. In the second step some values of variables should be locally suppressed. µ-ARGUS, currently under development, will be able to perform these tasks (see Figure 1). µ-ARGUS is a Windows 95 program developed with Borland C++.
Figure 1. —µ-ARGUS Functional Design
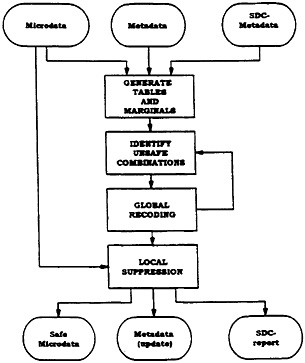
Metadata
To perform its task, µ-ARGUS should be provided with some extra meta information. At this moment, µ-ARGUS expects the data in a flat ASCII file, so the meta information should contain the regular meta data like the name, the position and the field width of the variables in the data file. Besides this the user needs to specify some additional (SDC-specific) metadata:
-
the set of tables to be checked;
-
the priority level for local suppression;
-
an indication whether a variable has a hierarchical coding scheme —this knowledge can be used for global recodings, as the truncation of the last digit is a sensible receding operation for these coding schemes;
-
a coding scheme for each variable; and
-
a set of alternative codes (recoding schemes) for each key-variable.
The user is not required to specify the coding schemes for all the identifying variables. If the coding scheme is not specified, µ-ARGUS will inspect the data file and establish the coding scheme itself from the occurring codes.
The level of identification is used to determine the combinations of the variables to be inspected. However, the user is free to determine the set of combinations to be checked, himself.
Generation of Tables and Marginals and Identification of the MINUCs
In order to identify the unsafe combinations and the MINUC's, the first step will be to generate the required tables and marginals. When the data files are available on the PC, the tables will be generated directly on the PC. However, in the case of very large files stored at an other computer (e.g., a UNIX-box), the part of µ-ARGUS that generates the tables can also be transferred to the UNIX-computer to generate the tables there. The ability to run µ-ARGUS on different platforms was the major reason for choosing C++ as our programming language.
When the tables have been generated, it is possible to identify the unsafe combinations. We are now ready to start the process of modifications to yield a safe file.
Global Recoding and Local Suppression
If the number of unsafe combinations is fairly large, the user is advised to first globally recode some variables interactively. A large number of unsafe combinations is an indication that some variables in the microdata set are too detailed in view of the future release of the data set. For instance, region is at the municipality level, whereas it is intended to release the data at a higher hierarchical level, say at the county or province level. To help the user decide which variables to recode and which codes to take into account, µ-ARGUS provides the user with the necessary auxiliary information. After these initial, interactive recodings, the user may decide to let µ-ARGUS eliminate the remaining unsafe combinations automatically. This automated option involves the solution of a complex optimization problem. This problem is being studied by Hurkens and Tiourine of the Technical University of Eindhoven, The Netherlands. Details can be found in Tiourine (1996). In that case, only those MINUCs can be eliminated automatically for which the SDC-metadata file contains alternative codes. The user should specify a stopping criterion, defining which fraction of the set of original MINUCs is allowed to remain, i.e., to be eliminated later by local suppression. The user can continue to experiment with recodings—both interactive and automatic ones (by undoing them and searching for alternatives) —until deciding which set of recodings to keep. Recodings that have been interactively established imply that the corresponding metadata (code descriptions, etc.) should be updated as well. If no MINUCs remain the job is finished and the global recodings can be performed on the microdata. However, in general, there are still MINUCs left which have to be eliminated by local suppression.
Final Steps
When the above-mentioned steps have been executed, the result is a safe microdata set. The only thing left is to write the safe file to disk and to generate a report and a modified metadata description. In the event that the original data file reside on another computer, µ-ARGUS will generate the necessary recoding information that will be used by a module of µ-ARGUS that runs on that other machine.
The Development of t-ARGUS
Besides the development of µ-ARGUS for microdata sets, the SDC-Project also plans development of t-ARGUS. t-ARGUS is aimed at the disclosure control of tabular data. (See Figure 2.) The theory of tabular disclosure control focuses on the “dominance rule.” This rule states that a cell of a table is unsafe for publication if a few (n) major contributors to a cell are responsible for a certain percentage (p) of the total of that cell. The idea is that, in that case at least, the major contributors themselves can determine with great precision the contributions of the other contributors to that cell. Common choices for n and p are 3 or 70%, but t-ARGUS will allow the users to specify their own choices. However, some modifications to this dominance rule exist.
Figure 2. —t-ARGUS Functional Design
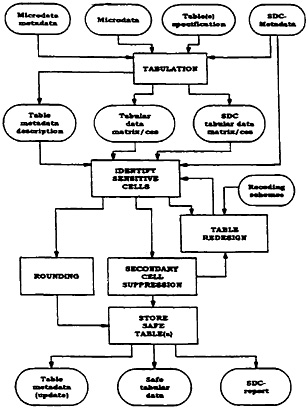
With this “dominance rule” as a starting point, it is easy to identify the sensitive cells, provided that the tabulation package cannot only calculate the cell totals, but also calculates the number of contributors and the individual contributions of the major contributors. Tabulation packages like ABACUS (made by Statistics Netherlands) and the Australian package SuperCross have that capability.
The problem, however, arises when the marginals of the table are published also. It is no longer enough to just suppress the sensitive cells, as they can be easily recalculated using the marginals. Even if it is not possible to exactly recalculate the suppressed cell, it is possible to calculate an interval which contains the suppressed cell. If the size of such an interval is rather small, then the suppressed cell can be estimated rather precisely. This is not acceptable either. Therefore, it is necessary to suppress additional information to ensure that the intervals are sufficiently large. Several solutions are available to protect the information of the sensitive cells:
-
combining categories of the spanning variables (table redesign) —more contributors to a cell tend to protect the information about the individual contributors;
-
rounding the table, while preserving the additivity of the marginals; and
-
suppressing additional (secondary) cells, to prevent the recalculation of the sensitive (primary) cells to a given approximation.
The calculation of the optimal set (with respect to the loss of information) of secondary cells is a complex OR-problem that is being studied by Fischetti. Details can be found in Fischetti (1996). t-ARGUS will be built around this solution and take care of the whole process. For instance, in a typical t-ARGUS session, the user will be presented with the table indicating the primary unsafe cells. The user can then choose the first step. He may decide to combine categories, like the global recoding of µ-ARGUS. The result will be an update of the table with presumably fewer unsafe cells. Eventually, the user will request that the system solve the remaining unsafe cells, by either rounding the table or finding secondary cells to protect the primary cells. The selection of the secondary cells is done so that the recalculation of the primary cells can only yield an interval. The size of these intervals must be larger than a specified minimum. When this has been done, the table will be stored and can be published.
The first version of t-ARGUS will aim at the disclosure control of one individual table. A more complex situation arises when several tables must be protected consistently, generated from the same data set (linked tables). Then, there will be links between the tables that can be used by intruders to recalculate the sensitive cells. This is a topic of intensive research at this moment. The results from this research will be used to enhance future versions of t-ARGUS, to take into account links between tables.
References
De Waal, A.G. and Willenborg, L.C.R.J. ( 1995a). A View on Statistical Disclosure Control for Microdata, Survey Methodology, 22, 1, 95–101, Voorburg: Statistics Netherlands.
De Waal, A.G. and Willenborg, L.C.R.J. ( 1995b). Global Recodings and Local Suppressions in Microdata Sets, Report Voorburg: Statistics Netherlands.
Fischetti, M. and Salazar, J.J. ( 1996). Models and Algorithms for the Cell Suppression Problem, paper presented at the 3rd International Seminar on Statistical Confidentiality, Bled.
Tiourine, S. ( 1996). Set Covering Models for Statistical Disclosure Control in Microdata paper presented at the 3rd International Seminar on Statistical Confidentiality, Bled.
Willenborg, L.C.R.J. ( 1996). Outline of the SDC Project, paper presented at the 3rd International Seminar on Statistical Confidentiality, Bled.
Willenborg, L.C.R.J. and de Waal, A.G. ( 1996). Statistical Disclosure Control in Practice, New York: Springer-Verlag.
Investigating Auto Injury Treatment in a No-Fault State: An Analysis of Linked Crash and Auto Insurer Data
Lawrence H.Nitz and Karl E.Kim, University of Hawaii at Manoa
Abstract
Hawaii is a no-fault insurance State which provides for choice of a variety of alternative therapies for motor vehicle injury victims. The two most frequently used providers are medical doctors (MD) and doctors of chiropractic (DC). A large portion of this care is rendered in office visits, and can be readily identified from insurance payment records. The focus of this study is the distribution of these types of direct medical care across crash types and circumstances. Study data include police crash reports and 6,625 closed case files of a Hawaii auto insurer for the years 1990 and 1991. The files were linked with Automatch, a probabilistic record linkage program, using crash date, crash time, gender and birth date as match fields (Kim and Nitz, 1995; Matchware Technologies, 1996). The insurance payment file indicates the type of treatment received by persons injured in collisions. The study asks two questions about the choice of care among crash victims:
-
Who goes to a chiropractor?
-
What is the relationship between occupant, vehicle and crash characteristics and the choice of care?
Background
Hawaii has had a no-fault insurance system for over twenty-five years (HRS 431:10C). The program was initially introduced to assure the availability of automobile liability insurance to all residents without age or gender discrimination. Underwriting is limited to rate adjustments based on the driving record of the individual applicant (HRS 531:10C-111(c)). The program, since its inception, provided that each motor vehicle operator's own insurance carrier would provide coverage for personal injury protection (PIP) for all injuries to the operator or his or her passengers, without examination of the issue of fault, up to a certain value, the medical-rehabilitative limit, or “tort floor, ” (HRS 431:10C-103(10)(c). This was $15,000 in 1990.) Injury costs beyond this value could be recovered from a party deemed to be at fault through a tort action in the courts. Each vehicle operator 's auto policy was also required to provide at least a minimum level of bodily injury (BI) protection for others who might be injured by the insured driver. This BI coverage could normally only be touched in the event that the injured party had reached the tort floor by claims against his or her own PIP coverage or had no PIP coverage. (A pedestrian, for example, would be able to make a BI claim directly.) Insurance carriers also offered additional coverage for uninsured and under insured motorists (UI and UIM). Hawaii drivers typically purchased these coverages to protect against catastrophic losses that might be incurred should they be in a collision with an un-or under-insured motorist. In the event that all available coverages had been exhausted, the injured party's medical insurer was held responsible for all remaining medical expenses. The medical insurer was deemed not responsible for any auto-related injury cost prior to the exhaustion of auto policy benefits.
The State Insurance Commissioner is authorized to adust the tort floor, every year to set a level at which 90% of all injury claims will be covered by PIP without resort to a suit (HRS 431:10C-308). In 1990, the tort floor was $15,000. If total medical and rehabilitation expenses and loss of wages exceeded this value, the patient could file a tort suit. Tort suits could be filed without respoect to monetary values for permanent and serious disfigurement, permantent loss of use of a body part, or death. In addition, the Insurance Commissioner set an annual “medical rehabilitative limit,” a value of medical and rehabilitative expenses which would be sufficient to permit filing of a tort suit. The medical rehabilitative limit for 1990 was $7,000, and for 1991 was $7,600. Until recent reform legislation passed in 1994, the auto injury patient 's choice of medical care facility and the scheduling of therapies recommended was very broad (HRS 431:10C-103(10)(A)(i)).
“All appropriate and reasonable expenses necessarily incurred for medical, hospital, surgical, professional, nursing, dental, optometric, ambulance, prosthetic services, products and accommodations furnished, and x-ray. The foregoing expenses may include any non-medical remedial care and treatment rendered in accordance with the teachings, faith or belief of any group which depends for healing upon spiritual means through prayer….”
In this context of open benefit provisions, the state has shown dramatic growth in the availability of chiropractic services, pain clinics, physical therapy facilities, and massage therapy practitioners.
The 1992 legislative session (1992 Hawaii Session Laws Act 123, Sec.7) put the auto injury treatment allowances on the same regimen as the disability-graded allowances for workers' compensation medical care and rehabilitative therapy (HRS 431:10C-308.5). The fact that there has been broad choice of type and amount of therapy for many years suggests that it might be useful to understand the relationships between objective features of the crash event and the actual choice of care. To make this analysis possible, it was necessary to link an auto insurer's payment file to the police motor vehicle accident report file. The next section outlines the data and procedures used to make this linkage.
Data
The police crash report file is maintained by the Hawaii State Department of Transportation. The four county police departments in Hawaii are required to report every motor vehicle collision on a public road which involves an injury or death or estimated damages of $1,000 or more (in 1990). The reporting form contains extensive description of the crash circumstances, features of the roadway and traffic environment, and driver characteristics. Where an injury has been reported, it also contains the police officer's description of the severity of injury on a five-level scale (K = killed, A = incapacitating injury, B = non-incapacitating injury, C = possible injury, and 0 = no injury). Drivers were also identified by their birth dates. Two years, 1990 and 1991, form the pool of reported motor vehicle collisions for this analysis.
The insurance file consisted of 6,625 closed case records of a Hawaii auto insurer for the years 1990 and 1991. The file contained the closing accounting records on these cases, showing the total of all sums paid out, and the elementary data on the characteristics of the crash and the injured party. All records represented claims actually paid; the maximum payment is the policy limit chosen by the insured in buying the policy. For this particular group of policies, the maximum policy limit the company offered was $300,000. Any additional coverage that might have been carried by way of an umbrella clause appeared in a different set of accounts. Injured persons were identified by birth date, gender, and date and time of the collision. The crash date, crash time, gender and driver age are common to both files, and provide a basis for linking the insurance payouts to details on the crash itself. Another insurance file contained details of about 58,000 transactions recording specific payments made in processing the claim. This file was initially proc-
essed by extracting the payee field as a SAS character field, and parsing it for common character combinations of the license designations MD (Medical Doctor) and DC (Doctor of Chiropractic). The file was then summed by claimant; applicable office call charges for MD and DC services were used to create separate analysis variables. This summary file was then merged with the matched crash and insurance event record file.
The Matching Procedure
Matchware Technologies's Automatch 4.0 was used to match the crash and the closed case file in three steps (Matchware Technologies, 1996). (See Kim and Nitz, 1995, for a more extensive discussion of the Automatch application.) Pass 1 divided the file into homogeneous blocks based on age and sex, and matched on time of crash, date of crash, and birth date. The log frequency distribution of the Fellegi-Sunter match weights for Pass 1 is shown in Figure 1. For Pass 1, 2,565 record pairs were designated as matches, with match weights meeting or exceeding the cutoff value. The optimal cutoff for the first pass was 16.0, which marks a relatively clear division in the distribution, as indicated in Figure 1. (The count of nonmatches with match weights of -19 and lower was truncated at 80,000 pairs, and the observed frequencies (+.5) were logged for display purposes.)
Figure 1.
Pass 1 Match Weight Distribution
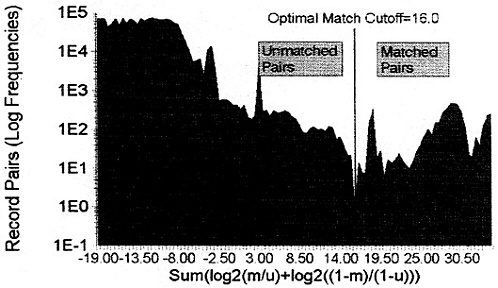
Pass 2 blocked on date of crash and sex, and matched on time and birth date. An additional 1,001 record pairs were selected as matches with a criterion value of 12.0. Pass 3 was designed to pick up erroneous recording of military time values. A field was created in the driver crash record which recoded afternoon and evening times into the 12-hour time scale. The cases were blocked on date and birth date and matched on sex and the 12-hour time value. Only seven additional cases were identified, using a criterion value of 7.0, to produce a total matched set of 3,573 cases. (The analyses to follow report the smaller numbers with complete information on crash characteristics of interest.)
ID values were extracted from the match output file and used to index the matching cases in the crash report, EMS run report, and insurance case files. These were then directly merged by common ID values in a SAS step.
Match Results
A comparison of the distributions of the police crash file and the matched file suggest parallel profiles for temporal and environmental crash characteristics. Of the insurance cases, 3,573 (54%) were matched to drivers and other principals identified by birth date in the crash file. There were no significant differences in the two distributions by intersection/mid-block location (Chi-square=.51, 1 df, p<.48, phi=.002), month (Chi-square 5.77, 11df, p<.89, phi=.008) or day (Chi-square= 4.09, 6 df, p<.66, phi=.007). The profiles for time distribution by hour, urban/rural location, and daytime and nighttime peak traffic periods showed significant, but low level differences (phi coefficients generally <.02). Gender, human factor, and police judgements of injury severity differed substantially across the two files, with the matched insurance file being more seriously injured (57% of insurance claimants denoted “not injured ” versus 74% of the police report file), more female (46% female in the insurance file to 34% in the police report file), less likely to report driving errors (62% v. 55%), and less likely to report human factor problems (55% to 49%).
Findings
Who Goes to the Chiropractor?
Earlier work with matched cases in Hawaii suggests that the configuration of the crash event, in particular crash type, and driver behaviors (human factors, driving errors, and other fault indicators) are major determinants of injury outcomes (Kim et al., 1995; Kim and Nitz, 1996; Kim et al., 1994). The linked insurance file allows further examination of the role of these factors, along with standard demographic indicators, in the choice of medical and therapy office calls.
In this discussion, we will first present effects that distinguish crash victims who use three classes of therapy: only chiropractic services; only medical services (MD-only); and some combination of chiropractic and medical services. Next we will discuss the patterns of therapy choices for demographic groups, then we will examine care usage for specific crash circumstances.
Relatively few of the crash drivers—89 persons, about 7% of the cases with detailed crash data, used only chiropractic services. This is a somewhat unexpected finding, considering the popularity of chiropractic care for auto trauma cases. Forty-four percent of the group using only chiropractic services were male, as opposed to 55% for those using both chiropractic and physician services, and 50% for those using only physician services. The most frequent age group for chiropractic-only use was 21–34 year-olds, with a
53% use rate, as opposed to 45% for those using both chiropractic and physician care and 36% for MD care alone. Those in the 45–64 age group comprised about 10% of the chiropractic service users, compared with 19% of the MD-only users. Seventy-one percent of the chiropractic-only users had no police recorded driving errors, as opposed to about 58% for users of the chiropractic and physician combination users and the MD-only users.
The small number of chiropractic-only users suggests that the group might be combined with those who use both chiropractic and physician services. Over 1,400 cases used a combination of chiropractic and physician services, and 1,105 used only physician services. Grouping all chiropractic users together will permit examination of the question of who goes to a chiropractor in Hawaii.
Table 1. —Chiropractic and Physician Office Visits by Driver Gender
|
Sex of Occupant |
Chiropractic Use |
MD Only |
Totals |
|||
|
N |
% |
N |
% |
N |
% |
|
|
Female |
722 |
45.35 |
550 |
50.00 |
1,272 |
47.25 |
|
Male |
870 |
54.65 |
550 |
50.00 |
1,420 |
52.75 |
|
All |
1,592 |
100.00 |
1,100 |
100.00 |
2,692 |
100.00 |
|
Chi-square = 5.64, 1 df, p< 018 |
||||||
Table 1 presents the choice of therapy by gender. The MD-only users were evenly split between men and women, while 55% of the users of chiropractic services were men. The pattern of usage by age is shown in Table 2. The age profiles differ significantly (p<.001). The 21–34 year-old group constitutes 47% of the chiropractic users, while it accounts for only 37% of the MD-only users. At the higher end of the age scale, the 45–64 year-old group comprises 13% of the chiropractic users, but 20% of the MD-only users. The pattern appears to suggest rapidly declining use of chiropractic services and relatively slower decline in use of MD-only services as individuals age. Other age groups do not differ meaningfully in chiropractic and MD use.
What Is the Relationship Between Occupant, Vehicle, and Crash Characteristics and Choice of Care?
There are slight differences in police-reported seatbelt use for chiropractic and physician service users, with 97% of the chiropractic users reporting belt use, and 95% of MD-only users report having been belted during the crash, as shown in Table 3. The crash report belt use rate is higher than previous independently observed belt use rates in the 80% range. Hawaii has a primary enforcement law for seatbelt violations. The penalties for being unbelted may raise reported belt use rates.
Table 2. —Chiropractic and Physician Office Visits by Driver Age
|
Driver Age |
Chiropractic Use |
MD Only |
Totals |
|||
|
N |
% |
N |
% |
N |
% |
|
|
Less than 15 |
27 |
1.70 |
17 |
1.55 |
44 |
1.64 |
|
15–18 |
84 |
5.30 |
102 |
9.32 |
186 |
6.94 |
|
18–21 |
143 |
9.02 |
95 |
8.68 |
238 |
8.88 |
|
21–34 |
748 |
47.16 |
401 |
36.65 |
1,149 |
42.87 |
|
35–45 |
302 |
19.04 |
215 |
19.65 |
517 |
19.29 |
|
45–64 |
212 |
13.37 |
214 |
19.56 |
426 |
15.90 |
|
65 + |
70 |
4.41 |
50 |
4.57 |
120 |
4.48 |
|
All |
1,592 |
100.00 |
1,100 |
100.00 |
2,692 |
100.00 |
|
Chi-square = 47.76, 6 df, p < 001 |
||||||
Table 3. —Chiropractic and Physician Office Visits by Seatbelt Use
|
Seatbelt Use |
Chiropractic Use |
MD Only |
Totals |
|||
|
N |
% |
N |
% |
N |
% |
|
|
Not belted |
48 |
3.17 |
52 |
4.98 |
100 |
3.90 |
|
Belted |
1,468 |
96.83 |
993 |
95.02 |
2,461 |
96.10 |
|
All |
1,516 |
100.00 |
1,045 |
100.00 |
2,561 |
100.00 |
|
Chi-square = 5.4, 1 df, p < 020 |
||||||
The distribution of users of chiropractic versus MD-only care differs in a number of ways across types of crashes. Table 4 illustrates the distribution of care choices across crash types commonly considered “at fault.” (The “at fault” drivers are identified as those striking another car, and those involved in rollovers.) The fault profiles of the two usage groups differ significantly. The not-at-fault drivers comprise 58% of the chiropractic users and 64% of the MD-only users. These rates are consistent with a pattern of using services more frequently when another party is felt to be at fault.
Table 4. —Chiropractic and Physician Office Visits by Crash Fault
|
Fault |
Chiropractic Use |
MD Only |
Totals |
|||
|
N |
% |
N |
% |
N |
% |
|
|
At fault |
540 |
42.32 |
287 |
35.83 |
827 |
39.82 |
|
Not at fault |
736 |
57.68 |
514 |
64.17 |
1,250 |
60.18 |
|
All |
1,276 |
100.00 |
801 |
100.00 |
2,077 |
100.00 |
|
Chi-square=8.65, 1 df, p < 003 |
||||||
Table 5 illustrates the relationship between care choice and police reported injury severity. The profiles differ significantly (p< 001). Of the chiropractic service users, 64% are reported by police to be “no injury” cases, while only 46% of the MD-only group are reported without injury at the scene. Computing the fraction of each injury level which uses MD-only services indicates that the 34% of those reported as no injury use MD services only, the rest using a combination of chiropractic and physician services. Sixty-six percent of those with incapacitating injuries using MD-only services, while only 17% use a combination of both chiropractic and physician services.
Table 5. —Chiropractic and Physician Office Visits by Police Reported Injury Severity
|
Police Injury Severity |
Chiropractic Use |
MD Only |
Totals |
|||
|
N |
% |
N |
% |
N |
% |
|
|
No injury |
853 |
63.70 |
447 |
46.13 |
1,300 |
56.33 |
|
Possible injury |
252 |
18.82 |
231 |
23.84 |
483 |
20.93 |
|
Non-incapacitating injury |
211 |
15.76 |
243 |
25.08 |
454 |
19.67 |
|
Incapacitating injury |
22 |
1.64 |
43 |
4.44 |
65 |
2.82 |
|
Fatality |
1 |
0.07 |
5 |
0.52 |
6 |
0.26 |
|
All |
1,339 |
100.00 |
969 |
100.00 |
2,308 |
100.00 |
|
Chi-square = 82.21, 4 df, p < 001 |
||||||
Crash type affects the distribution of care choices also, as shown in Table 6. Sixty-two percent of the chiropractic service users were involved in rear-end collisions, while only 54% of the MD-only users were involved in rear-end collisions. Head-on collisions and rollovers account for 3.5% of chiropractic users, compared to 8.1% of MD-only users. Broadside collisions, similarly, account for more MD-only than chiropractic usage (25% to 21%).
Table 6. —Chiropractic and Physician Office Visits by Crash Type
|
Crash Type |
Chiropractic Use |
MD Only |
Totals |
|||
|
N |
% |
N |
% |
N |
% |
|
|
Broadside |
269 |
20.53 |
215 |
25.29 |
484 |
22.41 |
|
Head on/rollover |
46 |
3.51 |
69 |
8.12 |
115 |
5.32 |
|
Rear end |
816 |
62.29 |
458 |
53.88 |
1,274 |
58.98 |
|
Sideswipe |
179 |
13.66 |
108 |
12.71 |
287 |
13.29 |
|
All |
1,310 |
100.00 |
850 |
100.00 |
2,160 |
100.00 |
|
Chi-square = 32.29, 8 df, p < 001 |
||||||
Human factors show several small effects on care choice (see Table 7). Chiropractic service users are slightly more likely to have committed misjudgements than MD-only users (12% to 9%), and about half as likely to have been in an alcohol or fatigue related crash as MD-only users (1.4% to 3.5% and 1.3% to 2.1%, respectively).
Table 7. —Chiropractic and Physician Office Visits by Human Factors
|
Human Factors |
Chiropractic Use |
MD Only |
Totals |
|||
|
N |
% |
N |
% |
N |
% |
|
|
Inattention |
331 |
20.92 |
233 |
21.47 |
564 |
21.15 |
|
Misjudgement |
190 |
12.01 |
100 |
9.22 |
290 |
10.87 |
|
Fatigue |
22 |
1.39 |
38 |
3.50 |
60 |
2.25 |
|
Alcohol |
21 |
1.33 |
23 |
2.12 |
44 |
1.65 |
|
Other |
70 |
4.42 |
61 |
5.62 |
131 |
4.91 |
|
None |
948 |
59.92 |
630 |
58.06 |
1,578 |
59.17 |
|
All |
1,582 |
100.00 |
1,085 |
100.00 |
2,667 |
100.00 |
|
Chi-square = 22.17, 5 df. P < 001 |
||||||
A variety of driving errors are known to lead to different types of crashes (Kim et al., 1995) Table 8 shows that chiropractic user crashes consisted of 3.5% involving excess speed, while MD-only users involved 4.9% crashes involving excess speed. A similar pattern is found for driving the wrong way: 11% of chiropractic users, and 13% of MD-only users were involved in these types of crashes. (Driving the wrong way includes driving in the wrong lane, crossing the centerline, improper passing, and related offenses.) Following too closely accounted for nearly twice as much chiropractic as MD-only use—9.5% of chiropractic users followed too closely, while only 5.3% of the MD-only users did so.
Table 8. —Chiropractic and Physician Office Visits by Driver Errors
|
Driver Errors |
Chiropractic Use |
MD Only |
Totals |
|||
|
N |
% |
N |
% |
N |
% |
|
|
Excess speed |
56 |
3.53 |
54 |
4.94 |
110 |
4.10 |
|
Disregard controls |
20 |
1.26 |
28 |
2.56 |
48 |
1.79 |
|
Driving wrong way |
174 |
10.96 |
146 |
13.36 |
320 |
11.94 |
|
Improper turn |
8 |
0.50 |
2 |
0.18 |
10 |
0.37 |
|
Following too closely |
145 |
9.13 |
58 |
5.31 |
203 |
7.57 |
|
Other |
150 |
9.45 |
121 |
11.07 |
271 |
10.11 |
|
None |
1,035 |
65.18 |
684 |
62.58 |
1,719 |
64.12 |
|
All |
1,588 |
100.00 |
1,093 |
100.00 |
2,681 |
100.00 |
|
Chi-square = 29.08, 6 df, p < 001 |
||||||
Summary and Discussion
The set of police crash report records matched to insurance claim records is associated with higher levels of injury than the unmatched police reports. It also has a larger proportion of females than the overall police report population. Typical environmental variables, such as time of day and intersection vs. mid-block location, show no meaningful differences between the matched and unmatched cases. The principal distinguishing factor in the reported crashes which match to insurance records appears to be the severity of injury— more severe injuries result in more frequent insurance claims.
This study provides new and useful information about the choice between traditional medicine, and approaches which rely to some degree on alternative forms of care, in this case, chiropractic care. Several conclusions emerge from the analysis:
-
persons who are “not-at-fault” (usually the struck party) use MD and chiropractic services more frequently than those “at-fault;”
-
the use of chiropractic services is substantially higher than the use of MD-only services among occupants with low severity police reported injuries;
-
those who commit what might be seen as the most serious driving errors in the course of a collision (driving on the wrong side, ignoring traffic controls, speeding) are less likely to use chiropractic care than those who commit no errors or more minor errors (e.g., following too closely, inattention, misjudgment);
-
when the driver has been impaired by alcohol, the use of chiropractic services is about half the level of use of MD-only services; and
-
more chiropractic services are used by men than women, particularly in the ages of 21 to 34.
Our study has a number of limitations. The first stems from the nature of the auto insurance market in Hawaii: no single insurer holds a very large share of the total market, so the number of policies, and thus claims paid by each insurer are relatively small. The second is that the data spans only a portion of a time period in which three substantial changes have been made to Hawaii's motor vehicle insurance laws. The third is the restriction of the present analysis to choice of care, rather than total cost of care.
There is decidedly a need for additional research to address these limitations. Case files from additional insurers would increase the pool of claims, and allow exploration of whether company practices affect claim patterns. Extending the time period covered from 1990 –91 through 1995–96 would span a major change in the way chiropractic charges were to be reimbursed under Hawaii motor vehicle insurance policies, providing a natural quasi-experiment. This would allow a test of the effect of subjecting chiropractic treatment to the workers' compensation schedule.
New research questions on choice of therapy could extend the results of this study by examining some questions not raised in the present study.
-
That is the relationship between fault and the quantity and cost of chiropractic or other alternative care used?
-
How do drivers' prior histories in terms of traffic violations or insurance claims affect the nature of the care they choose when injured in a collision?
-
How would the patterns of choices and costs of care differ in a pure tort law state?
-
There is clearly a need for more research on the role of crash and occupant characteristics in choice of therapies.
References
Hawaii Revised Statutes, Annotated. 1994 Replacement and 1996 Supplement. Michie & Co.
Hawaii Session Laws ( 1992). Act 123, Sec. 7.
Kim, K.E. and Nitz, L.H. ( 1995). Application of Automated Records Linkage Software in Traffic Records Analysis, Transportation Research Record, 1467, 40–55.
Kim, K.E. and Nitz, L.H. ( 1996). Understanding Causes of Injuries in Motor Vehicle Crashes, Transportation Quarterly, 50, 1, 105–113.
Kim, K.E.; Nitz, L.H.; Richardson, J.; and Li, L. ( 1994). Analyzing the Relationship between Crash Types and Injuries in Motor Vehicle Collisions in Hawaii, Transportation Research Record, 1467, 9–13.
Kim, K.E.; Nitz, L.H.; Richardson, J.; and Lei, L. ( 1995). Personal and Behavioral Predictors of Automobile Crash and Injury Severity, Accident Analysis and Prevention, 27, 4, 469–481.
Matchware Technologies, Inc. ( 1996). Automatch 4.0.
Quantitative Evaluation of the Linkage Operations of the 1996 Census Reverse Record Check
Julie Bernier, Statistics Canada
Abstract
A probabilistic linkage of two files is performed using the theory derived by Fellegi and Sunter (1969). The decision on whether a unit from each file are linked is based on the linkage weight obtained. In effect the linkage weight, a one-dimensional variable, is divided into three ranges: one for which links are accepted, one for which they are rejected and the intermediate range, where a link is possible. Manual inspection of possible links is needed to decide which ones represent the same unit. At the end of the linking procedure, the accepted links and those possible links that were confirmed by the manual check are kept. Under certain conditions, the results of this check provide all the information needed for a quantitative evaluation of the quality of the links. In this article we present a brief description of the Reverse Record Check (RRC) and the role of probabilistic linkage in this project. We then offer a definition of the reliability of a link and describe a procedure for estimating the minimum reliability of the links kept, using a fitted logistic regression model based of links. Finally, we present the results obtained for the RRC96, describing the number of links obtained and the reliability of those links.
Introduction
When a probabilistic linkage is performed between two files, any of several approaches may be used. Depending on the approach chosen, it may be that among the linkage weights obtained, there will be a limited number of different values. In this case, a number of links are associated with each weight, and we can proceed by sampling to estimate the proportion of true links for each possible weight value. The next step is to manually inspect the links sampled. It may also happen that the set of possible values of the linkage weight will be quite varied. This may result in the use of a great number of comparison rules, each making a different contribution to the total weight depending on whether or not there is a match between the fields compared. This variety of weights may also result from the use of comparison rules that assign frequency weights in the event of a match. The use of frequency weights means that where there is a match, a different contribution is made to the total weight depending on whether the content of the fields compared is more or less frequent in the population. For example, a larger contribution is made when there is a match on a relatively rare family name. In the case of a set of varied weights, the distribution of links on the basis of the linkage weights closely resembles a continuous distribution. The proportion of true links may then be estimated by grouping the weights by intervals or by using a logistic regression. The use of logistic regression was chosen as the method of estimating the proportion of true links in the linkage of the 1996 Reverse Record Check (RRC96) with the 1990 Revenue Canada files (RCT90), since in that linkage, a number of comparison rules were involved. Furthermore, for two of the fields compared, namely family name and the first three entries of the postal code, frequency weights were used.
The Reverse Record Check
The purpose of the reverse record check is to estimate the errors in coverage of the population and of private households in the Census. It also seeks to analyse the characteristics of persons who either were not enumerated or were enumerated more than once. The method used is as follows:
-
Using a sample frame independent of the 1996 Census, a sample is drawn of persons who should have been enumerated in the Census.
-
A file is created containing as much information as possible on these persons and their census families.
-
If possible, the addresses of the selected persons (SP) and their family members (close relatives living under the same roof) are updated using administrative files.
-
Retrieval operations are carried out by interviewers in order to contact the selected person and administer a questionnaire to him or her. The purpose of the questionnaire is to determine the addresses at which the person could have been enumerated.
-
Search operations are carried out on the questionnaires and in the Census database in order to determine how many times the selected person was enumerated.
The Role of Probabilistic Linkage
Probabilistic linkage is used in the address updating procedure. In this procedure there are two principal stages. First, probabilistic linkage of the RRC96 with the Revenue Canada 1990 (RCT) file is carried out. The reason for choosing the year 1990 is that this database was created in early 1991 and the sample frame of the RRC is largely made up of the database of the 1991 Census and the files of the RRC91. When this linkage is successfully completed, we obtain the social insurance number (SIN) of the selected person or a member of that person's family. In the second stage, an exact linkage is made between the RRC96 and the 1991, 1992, 1993, and 1994 Revenue Canada files in order to obtain the most recent address available in those files. For this linkage, the SIN is used as an identifer. It is by means of these addresses that we can begin tracing the selected persons by the RRC.
During operations to link the RRC sample with the 1990 Revenue Canada files, we determined, for each of the eight region-by-sex groups, a threshold linkage weight beyond which all links were considered definite or possible and were retained for the next stage. Subsequently, we checked the weakest links in order to determine whether they were valid or false. This enabled us firstly to eliminate the false links before proceeding to subsequent operations and secondly to determine the reliability of the links retained. Two other approaches may be used. One can define a fairly low linkage weight beyond which all links are kept without being checked. This yields a greater number of links, some of which have little likelihood of being valid. There are two drawbacks to this approach. First, it means that the interviewers responsible for tracing selected persons are given more false leads. This can result in time loss during tracing and a greater probability of interviewing by error a person other than the one selected in the sample. Second, the update address is processed in the search operation. This too can needlessly increase the size of this operation. The other possible approach is to define a fairly high linkage weight beyond which all links are
retained without being checked. They yields fewer links, but those obtained have a strong probability of being valid. The disadvantage of this method is that it increases the number of persons not traced. This type of nonresponse is more common in the case of persons living alone, and such persons are also the ones who have the greatest likelihood of not being enumerated. It is for this reason that we preferred the approach that requires manual checking but serves to reduce this type of nonresponse without needlessly expanding the tracing and search stages.
Checking Procedure
In light of the amount of data to be processed, linkage is carried out separately in eight groups defined by the sex and the geographic region of the individual to be linked. The four geographic regions are: Eastern Canada, Quebec, Ontario, and lastly, Western Canada and the Northwest Territories. For each of the four regions it is necessary to define a grey area within which links are considered “possible” rather than being accepted automatically. This area extends from the lower boundary weight (LOW) to a weight determined iteratively (UPP) in the course of checking. The point LOW is determined through guesswork, by examining the links ranked by descending order of weight. The persons engaged in this task try to choose a point LOW such that manual checking will be done when links have a fairly high probability of being valid (approximately 75%). The checking begins with UPP chosen such that the grey area contains roughly 1.5% of the links retained for the region in question. To reduce the workload, some of these links are then checked automatically, in the following manner: when both spouses in a household have linked, if one of the two (C1) obtained a high linkage weight and if in addition that person's record at RCT is found to contain the SIN of the spouse (C2), and if that SIN is the same as the one found in the record that is linked with C2, then the link of C2 with RCT is considered reliable, even if it obtained a linkage weight within the grey area. All the links in the grey area that did not satisfy the foregoing criterion were checked manually. These checks were carried out using all available information on the household as a whole. After the entire grey area was checked, if the number of rejected links seemed high, UPP was changed so as to add from 1.5% to 2% more links to the grey area. These two steps (choosing UPP and checking) were repeated until the rejection rate for the links checked seemed lower than 10% for links with a linkage weight close to UPP.
Shown below, for each region, are the grey area boundaries, the percentage of links within those boundaries and the total percentage of links rejected in the grey area.
Table 1. —Results of Checking
|
Region |
LOW |
UPP |
Percentage of Links Checked |
Percentage of Links in Grey Area Rejected |
|
Eastern |
222 |
244 |
1.5 |
2.1 |
|
Quebec |
221 |
304 |
7.5 |
23.0 |
|
Ontario |
274 |
309 |
2.0 |
1.2 |
|
Western |
219 |
258 |
1.5 |
4.9 |
As stated in the introduction, these checks are useful in two ways. First, they serve to eliminate most of the false links. They therefore enhance the quality of the set of links obtained. Second, these checks
enable us to form a data set that contains, for various links, both their status (valid or false) and their linkage weight. Using this data set, we were then able to assess the reliability of the accepted links.
Definition of the Reliability of a Link
The probabilistic linkage procedure consists in calculating, for each pair of records, a weight W based on whether the fields compared match or do not match and on the probability of matching these fields given a linked pair or an unlinked pair. Generally, during the matching procedure, we try to determine a lower boundary and an upper boundary such that pairs with a weight lesser than LOW are rejected, those with a weight greater than UPP are accepted and those between these two boundaries are considered as possible links and eventually undergo another classification procedure. The following figure illustrates these concepts.
Figure 1. —Distributions of Pairs of Records by Linkage Weight
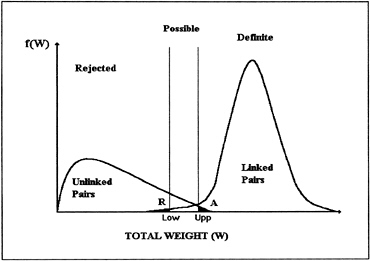
In linkage, two types of error are possible: accepting a pair that is not linked (A) or rejecting a linked pair (R). We are usually interested in the following probabilities:
P(accept a link | the pair is not linked) = P(W>UPP | the pair is not linked) and
P(reject a link | the pair is linked) = P(W<LOW | the pair is linked),
which are called classification error probabilities. We try, then, to choose LOW and UPP such that these two probabilities meet certain optimization criteria (see Fellegi and Sunter). Methods for estimating these probabilities may also be obtained by using samples of accepted links and rejected links that are checked manually (see Armstrong and Mayda, 1993 for a partial review of these methods). For the RRC96, we proceed differently. We determine a point LOW below which all links are rejected, but we do not define in
advance a point UPP that would separate possible links from definite links. This point is instead determined during the manual check when it is felt that the links checked exhibit a high enough frequency to stop checking. Here we are instead interested in the following probabilities:
P(the link is valid | the link is accepted) = P(valid | W>UPP) and
P(the link is valid | the link is rejected) = P(valid | W<LOW).
These two probabilities will be called the reliability of accepted links and the reliability of rejected links. It should be noted that the term reliability applies here to a link and not to the procedure that leads to the acceptance or rejection of this link. We therefore speak of the reliability of a rejected link as being the probability that this link is valid, which in fact amounts to a classification error. We could estimate these two probabilities respectively by the proportion of linked pairs among the accepted links and the proportion of linked pairs among the rejected links. These estimates would require manual checking of two samples drawn respectively from the accepted links and the rejected links. We ruled out this method for two reasons. First, the rejected links set was not retained. Second, for an estimate of a very low error rate to be acceptable, a very large sample is required, which means that the more successful the linkage procedure, the more costly the quantitative evaluation of the reliability of links using two samples. We therefore chose an alternative that allows us to use checking in the grey area rather than requiring checking of one or two additional samples.
Reliability Evaluation Procedure
We can speak generally of P(valid | W>UPP), which is the reliability of the links in the accepted links set, and of P(valid |W<LOW), the reliability of the links in the rejected links set; but we cannot speak more specifically of P(valid | W), the proportion of valid links in the subset consisting of pairs with linkage weight W. The proportion P(valid | W) may be defined as the reliability of a link of weight W. When we speak of quantitative evaluation, we may want to obtain a general estimate of the reliability of the accepted links and the rejected links, or we may want more specifically to estimate P(valid | W) for certain critical values of W. Since this probability increases with W, we have only:
P(valid | W=UPP) constitutes a lower boundary for the reliability of the accepted links.
P(valid | W=LOW) constitutes an upper boundary for the reliability of the rejected links.
In addition, no error is associated with the grey area, meaning that we consider that the manual check is a total success. Our quantitative evaluation therefore consists in estimating P(valid | W=UPP) and P(valid | W=LOW). To do this we use a logistic regression model, the parameters of which are estimated from the links in the grey area. This method is based on two assumptions. First, it must be assumed that the variable W is linked linearly to the logit function of the reliability to be estimated (logit(p)=log(p/1-p)). The logistic model is of the following form:
logit(p | W) = a + ß W, where p is the probability that the link is valid.
This condition, which constitutes a test of goodness of fit for the model, is verified by a method described in the appendix. Second, the grey area must contain a sufficient number of unlinked pairs with various W values. When the number of unlinked pairs in the grey area is insufficient, the hypothesis ß=0 cannot be rejected at a meaningful level. In the latter case, the proportion of valid links in the grey area is very high and can serve as the upper boundary for P(valid | LOW) and the lower boundary for P(valid | UPP). It should be noted that such a situation means that we have been too strict in choosing the cutoff point LOW
in the linkage operations, and have therefore rejected many valid links and inappropriately used manual checking on a set of links with very high reliability. The procedure proposed is therefore the following:
-
Check links in the grey area; each pair is considered linked or unlinked.
-
Estimate parameters a and ß of the logistic regression.
-
Test the goodness of fit of the model and test the hypothesis ß=0.
-
If the results of the tests are satisfactory, estimate P(valid | W=UPP) by using
logit(P(valid | W=UPP)) = a + ß UPP and estimate P(valid | W=LOW) by using
logit(P(valid | W=LOW)) = a + ß LOW.
-
If the results of the tests do not allow us to use the model, we merely estimate the proportion of valid links in the grey area.
Results
Shown below are the results obtained for the four regions. The estimates are made using both males and females, since introducing the sex variable into the logistic regression does not make a significant contribution.
Table 2. —Estimate of Reliability
|
Region |
Eastern |
Quebec |
Ontario |
Western |
|
Estimate of regression equation |
logit(p)= -2.82 + 0.0165 W |
logit(p)= -12.70 +0.0665 W |
||
|
Estimate of reliability at W=LOW |
69.6% |
86.6% |
||
|
Estimate of reliability at W=UPP |
> 97.9% |
90.0% |
> 98.8% |
98.8% |
|
Estimated W for which reliability is 90% |
304 |
224 |
For Eastern and Ontario regions, we didn't find enough unlinked pairs to do a logistic regression. This means that we could probably have set LOW lower in the linkage operations. For Quebec and Western regions, we estimated the reliability using the logistic regression model. It will be recalled that we check either 1.5% of the weakest links or several series of links until the estimated reliability at W=UPP seems to us to be greater than 90%. For Region 2, the estimate of 90% for reliability at UPP shows that we succeeded in choosing UPP such as to ensure good reliability of links while minimizing manual checking.
It should be recalled that:
-
All links in the grey area were checked, and those that were false were rejected.
-
The estimated reliability at point UPP is a lower boundary for the reliability of the accepted links.
-
The overall reliability in the interval [LOW,UPP] is also a lower boundary for the reliability of the accepted links.
We therefore estimate that the accepted links have a reliability greater than 97.9% in the Eastern region, greater than 90% in Quebec, greater than 98.8% in Ontario, and greater than 98.8% in the Western region.
It should lastly be noted that often in linkage procedures, the approach used is one that seeks to retain as many links as possible. In such cases, the LOW and UPP boundaries are set much less strictly than was done for the RRC-RCT linkage. In that situation, using the method described here could prove to be ineffective or even discouraging, since the reliability calculated by means of logistic regression is a lower boundary for the reliability of the accepted links. In some cases, that boundary could be very low although the overall rate of false links is acceptable. In such cases, it may be preferable to instead use a sample of the accepted links to estimate reliability generally.
Linkage Results and Conclusion
After choosing LOW and UPP and determining the links to be retained (either automatically or by manual checking), we obtain the following linkage rates for Canada's different geographic regions:
Table 3. —Linkage Results by Region
|
Region |
Eastern |
Quebec |
Ontario |
Western |
|
Selected person(SP) linked |
57% |
54% |
58% |
54% |
|
SP not linked but other family member linked |
36% |
35% |
31% |
36% |
|
No linkage |
6% |
10% |
9% |
9% |
|
Linkage not attempted |
1% |
1% |
2% |
1% |
|
Sample size |
12,440 |
7,328 |
9,243 |
16,820 |
As may be seen, an update address is obtained for more than half of the selected persons, with an address reliability greater than 90%. As regards persons who are not linked, in many cases another member of the household is linked, so that we can nevertheless obtain a valid address for tracing in roughly an additional 35% of cases.
These results should enable us to obtain a satisfactory response rate for the RCC96.
To verify the linearity of the relationship between the logit of reliability and weights W, we grouped the weights into intervals and worked with the midpoints of these intervals. For the two regions where a model has been used, the model obtained in this way is very close to the one obtained by means of logistic regression. This confirms that the logistic model functions well for predicting the reliability of the links in
the manual checking range. This model could also be used on a sample of links checked during the linkage procedure, so as to determine UPP and LOW points that result in both an acceptable level of reliability and a reasonable amount of manual checking, or even to choose to change the linkage rules if we suspect that it will not be possible to achieve these two objectives simultaneously.
References
Armstrong, J.B. and Mayda, J.E. ( 1993). Model-Based Estimation of Record Linkage Error Rates, Survey Methodology, 19, 2, 137–147.
Fellegi, I.P. and Sunter, A.B. ( 1969). A Theory for Record Linkage, Journal of the American Statistical Association 64, 1183–1210.






























