
Chapter 3
Contributed Session on Applications of Record Linkage
Chair: Martin David, University of Wisconsin
Authors:
John L.Czajka, Mathematica Policy Research, Inc.
Lin Hattersley, Office of National Statistics, UK
Dennis Utter, National Highway Traffic Safety Admin.
John Horm, National Center for Health Statistics
Linking Administrative Records Over Time: Lessons from the Panels of Tax Returns
John L.Czajka, Mathematica Policy Research, Inc.
Abstract
In 1985 and again in 1987, the Statistics of Income (SOI) Division of the Internal Revenue Service initiated panel studies of taxpayers. Taxpayer identification numbers (TINs) reported on a sample of tax returns from the 1985 and 1987 filing years were used to identify panel members and search for their returns in subsequent years. The 1987 panel also included efforts to capture dependents, based on the TINs reported on Aparents@ and dependents' returns. This paper describes and assesses the strategy used to identify panel members and then capture and link their returns. While the availability of a unique identifier greatly simplifies data capture and record linkage and, as in this case, may determine whether or not a record linkage project is operationally feasible, imperfections in the identifiers generate a range of problems. Issues addressed in this paper include elements of operational performance, validation, and measuring the completeness of matching or data capture. Recommendations for improving the success of such efforts are presented, and implications for linkage across administrative records systems are discussed.
Introduction
How often, when confronted with a task requiring the linkage of records with imperfectly listed names and addresses, recorded in nonstandard formats, do we long for a unique identifier? This paper addresses some of the problems that analysts may face when they perform exact matches using a unique identifier. The paper deals, specifically, with records that have been linked by an exact match on social security number (SSN). The question it poses is, when is an exact match not an exact match? The paper is more about “unlinkage” than linkage per se. The linkages created by exact matches on SSNs represent the starting point. The work that ensues involves breaking some of these linkages as well as creating additional ones. The findings reported here may be relevant to any effort to link administrative records by SSN, whether longitudinally or cross-sectionally.
Overview of the Statistics of Income (SOI) Panel Studies
Over the years, the SOI Division of the Internal Revenue Service (IRS) has conducted a number of panel studies of individual (1040) tax returns. These studies employ a common methodology, for the most part. A base year panel sample is selected from the annual SOI cross-sectional sample, which provides a large and readily available sampling frame for such studies. Panel members are identified by their SSNs, as reported on their base year sample returns. The IRS searches for and captures all returns that list panel SSNs as filers in subsequent years. The returns captured by this procedure are then linked longitudinally. In reality, what are linked over time are persons, and these person linkages imply linkages
between tax returns. In the two most recent panel studies, described below, the SSNs were edited, after this initial linkage, to correct errors and fill in missing values. After the editing was completed, the linkages were re-established. As a result of this process, some of the original links were eliminated while others were added.
The 1985-based Sales of Capital Assets (SOCA) Panel began with about 13,000 base year returns. All filers on these returns were initially designated as panel members. Joint returns, which can be filed only by married couples, have two filers. Returns with other filing statuses have one filer. A SOCA Panel file covering the years 1985 to 1991 has been completed.
The 1987-based Family Panel began with about 90,000 base year returns. Not only filers but also their dependents (as claimed on base year returns) were defined as panel members. Returns filed by separately filing spouses, whether panel members or not, are to be captured and linked to the returns filed by their panel spouses. Returns filed by the dependents who are claimed in any year after the base year, whether they are original panel members or not, are to be captured and linked as well—but only for the years in which they are claimed. Work to implement and review the SOI edits and prepare a panel file is only beginning; further editing will take place over the next few months.
Problems Created by Incorrect SSNs
Incorrect SSNs create a number of problems affecting not only record linkage and data capture but subsequent analysis of the data. In describing these problems, it is helpful to distinguish between incorrect SSNs on base year returns, which by definition include only panel returns, and incorrect SSNs on out-year returns, which include both panel and nonpanel returns.
Incorrect SSNs reported on base year returns have two types of consequences. Both stem from the fact that base year panel SSNs provide the means for identifying and capturing out-year panel returns. First, incorrect base year SSNs produce pseudo-attrition. Individuals whose SSNs were listed incorrectly in the base year will drop out of the panel when they file with correct SSNs. If these individuals are married to other panel members, they will remain in the database, but unless their base year SSNs are corrected their later data will not be associated with their earlier data. These missed linkages lead to incorrect weight assignments, which have a downward bias. A second consequence of incorrect base year SSNs is that the IRS will look for and may link the out-year returns of the wrong individuals to the base year records of panel members. The editing of SSNs is intended to eliminate both kinds of linkage errors.
Incorrect SSNs on out-year returns, as was stated, may involve both panel and nonpanel returns. If a panel member's SSN is misreported on an out-year return, after having been reported correctly in the base year, the out-year SSN will not be identified as panel, which may prevent the panel member's return from being captured at all. This is true if the panel member whose SSN is incorrect is the only panel member to appear on the return. While many panel returns continue to be selected for the annual cross-sectional sample in the years immediately following the base year, such that a panel return may still be captured despite the absence of a panel SSN, the incorrect SSN will prevent the panel member's being linked to the earlier returns. If a nonpanel return incorrectly includes a panel SSN, this error will result in, first, the return's being captured for the panel and, second, the wrong individual's data being linked to the panel member's base year record.
The bias that may be introduced by incorrect SSNs is distributed unevenly. Certain types of returns appear to be more prone to erroneous SSNs than others. Clearly, error rates are higher among lower income returns than among higher income returns. They may be higher as well among joint returns filed by
couples who have a better than average chance of divorce in the next few years, although this observation is more speculative.
The dollar costs of incorrect SSNs cannot be overlooked either. In addition to the editing costs, there is a cost to collecting and processing excess returns.
Identifying Incorrect SSNs
The SSN lacks a check digit. The SSN was established long before it became commonplace to include in identification numbers an extra digit or set of digits that can be used in an arithmetic operation to verify that the digits of the number “add up” right. As a result, there is no quick test to establish that a reported SSN was recorded incorrectly. Instead, it is necessary to make use of a number of other techniques to validate and correct the SSNs that are reported on tax returns or other administrative records.
Range checks are an important tool in screening out incorrect SSNs early in processing. Range checks of SSNs build on what is known and knowable about the distribution of numbers that have been issued by the Social Security Administration (SSA). A very limited range check can be based on the fact that the first three digits of the nine-digit number must fall into either of the ranges 001–626 or 700–728. SSNs with lead digits that fall outside these ranges must be incorrect. (The IRS uses an additional range to assign taxpayer identification numbers to persons who cannot obtain SSNs; these numbers are valid for IRS purposes but cannot be linked to other data.) More elaborate tests may utilize the fact that the 4th and 5th digits of the SSN have been assigned in a set sequence, historically. For each set of first three digits, SSA can report what 4th and 5th digits have been assigned to date or through a specific date. Most of the nine-digit numbers that have never been issued—and, therefore, are incorrect—can be identified in this manner. In addition, the SSNs that were assigned to persons who have since died can be obtained from SSA. Brief records for most SSA decedents can be accessed via the Internet.
The IRS maintains a validation file, using data obtained from SSA, to verify not only that particular numbers have ever been issued, but that they were issued to the persons who report them. The validation file contains up to 10 “name controls” for each SSN, where a name control consists of the first four characters of an individual's surname. If an individual changes his or her name numerous times and registers these changes with SSA, the different name controls will be present on the validation file, sorted from the latest to the earliest. The name control is a relic of period of much more limited computing capacity and less powerful software. The inability of name controls to differentiate among members of the same family, for example, restricts their utility for the editing of tax panel data, since misreporting among family members is a common type of error.
SSA maintains much more extensive data for its own validation purposes as well as other uses. Essentially all of the information collected on applications for new or replacement social security cards is retained electronically. The SSA will also perform validation exercises for other agencies. This was not an option for the IRS data, which could not be shared with SSA, but it may be a viable path for other users to take. In performing its validation and other matching exercises, SSA relies heavily on exact matches on multiple characteristics. SSA utilizes partial matches as well but without the framework of a probabilistic matching algorithm. As a result, SSA's validation tends to be conservative, erring on the side of making too few matches rather than making false matches.
In editing the SSNs reported on tax panel records, the IRS staff employed a number of evaluation strategies. These are discussed below.
The SOI Editing Strategy
The editing strategy employed by SOI staff for the two panel databases included several key elements. The first was the use of automated procedures to flag probable errors. The second was the reliance on manual or clerical review to evaluate the cases that were flagged as containing probable errors. Automated validation tests were not always definitive in identifying false matches, so expert review was often necessary. Furthermore, there was no attempt to automate the identification of the appropriate corrections. The clerical review was responsible, then, for determining if an SSN was indeed incorrect, identifying the correct SSN or an appropriate substitute, and then implementing the needed corrections. The third element of the editing strategy was to correct the base year panel SSNs to the fullest extent possible. This is an important task because the corrected SSNs identify panel members in future years. The fourth element was to eliminate cross-sectional “violations” in the out-years—that is, instances where particular SSNs appeared as filers multiple times in the same tax year, or where the SSNs listed as dependents matched to filers who were not the dependents being claimed. The last element of the editing strategy was to use automated procedures to apply SSN corrections to other years, where errors might exist but may not have been flagged. These corrections are directed at situations where a taxpayer continues to report an incorrect SSN for a filer, a separately filing spouse, or a dependent, year after year or at least for multiple years. These misreported SSNs may not always be flagged as probable errors. Furthermore, it is highly inefficient to rely on independent identification and correction of these errors.
Limitations of the Editing Strategy
The overall strategy has two notable limitations. First, the sheer number of cases that could be flagged as probable errors in a panel database containing nearly a million records, as the Family Panel file does, is very imposing. The obvious response is to limit clerical review to cases whose probabilities of error are judged to be very high. The SOI Division designed a number of validation tests. Certain tests were considered to be fatal; all violations had to be corrected. For other tests, multiple failures or specific combinations of failures were necessary in order to trigger a review. If a test is associated with a low probability of error, clearly it is inefficient to review all cases. But if there is no other test that in combination with this one can identify true errors with a high enough probability to warrant review, then errors will be missed. Below we discuss some of the problems associated with identifying incorrect secondary SSNs.
Another limitation is that cross-sectional error detection strategies have been favored over longitudinal strategies. This can be attributed to two things. First, some of the desired linkages are cross-sectional in nature, and cross-sectional tests have a direct impact on the quality of these matches. Second, it is difficult to define longitudinal tests that identify cases with high probabilities of error. The kinds of longitudinal conditions that suggest errors in SSNs involve breaks in continuity—for example, changes in the SSN of a spouse or in some aspect of filing behavior. While incorrect SSNs will produce such breaks, most of the occurrences are attributable to genuine change.
Validating SSNs Against IRS/SSA Records
In editing the SOCA and Family Panel files, SOI staff used an IRS validation file that contained fields obtained, ultimately, from SSA. These fields were the SSN, up to 10 name controls, and the date of birth. Identifying variables that were present on the panel records included:
-
SSNs (primary, secondary, and dependent);
-
Return name control (derived from surname of first-listed filer);
-
City and state;
-
Full name line—starting in 1988; and
-
Name of separately filing spouse—starting in 1988.
That the SOI Division did not begin to obtain full names until 1988 proved to be unfortunate for both panels. Having full names for the base year would have allowed panel members to be identified by both name and SSN. Some of the problems of validation that grew out of the limited identifying information that was present for the base year returns in both panels are discussed below.
Use of the Return Name Control
Until full names became available, the only identifying information about a filer was the return-level name control, which is derived from the surname of the primary filer, which may differ from that of the secondary filer and one or more dependents. Testing for exact agreement between the return name control and any of the name controls on the validation file for the primary SSN, the secondary SSN, and any dependent SSNs could be automated easily and reliably. Exact agreement was interpreted as validating the SSN. For primary SSNs, the application of this test dispensed with well over 99 percent of the sample cases. In a clerical review of cases failing this test in the base year of the SOCA Panel, more than half were judged to be true matches. The test failures occurred in these cases because of the misspelling of a name control on either file or because the order of the SSNs on the return did not correspond to the order of the names. That is, a couple may have filed as John Smith and Mary Wesson but listed Mary's SSN in the primary position. In this case the return name control of SMIT would not have matched the name control, WESS, associated with the primary SSN in the validation file. For secondary SSNs, the application of the return-level name control test dispensed with over 90 percent of the sample cases in the base year of the SOCA Panel. Still, the remainder were too many to review. Moreover, clerical review of the cases with name control mismatches could not be expected to resolve all of these cases. A secondary filer with a different surname than the primary filer would fail the test. Without a full name line, it was not possible to establish the secondary filer's surname or even that it differed from the primary filer's surname.
Use of Full Name Lines
Full name lines were not available to validate base year SSNs for either panel. From the standpoint of correctly establishing base year names, the one year lag for the Family Panel was not as bad as the three year lag for the SOCA Panel. Still, given that many erroneous SSNs are incorrect for only one year, the problem presented by changes in SSNs for secondary filers is a significant one.
The single most useful piece of information that a full name line provides is a surname for the secondary filer, from which a name control can be constructed. Basing validation tests for secondary SSNs on a secondary name control will yield substantially fewer false failures than tests that use the return level name control. With this improved targeting, clerical review of all violations becomes not only feasible but desirable.
Because the format of the name line is not exactly standard, there will be errors in constructing name controls for the secondary filer. Many of these errors, however, may occur in situations where the secondary filer has the same surname as the primary filer. For example, John and Mary Smith might list their names as John Smith and Mary. While an overly simple algorithm might yield MARY as the secondary name control, which would be incorrect and would produce a test failure, this need not undermine the validation procedures. Any strategy for using secondary name controls generated in this manner should include testing the secondary SSN against both the return name control and the secondary
name control. In this example, the incorrect secondary name control would be irrelevant, as Mary Smith's SSN would be validated successfully against the return name control.
Strategies When Name Lines Were Not Available
For the SOCA Panel, name lines did not become available until year four. Birth dates provided important alternative information with which to evaluate the secondary SSNs. The birth date of the primary filer implies a probability distribution of secondary filer birth years. An improbable birth year for the secondary SSN may be grounds for determining that the SSN is incorrect when it also fails a name control test based on the return name control. Birth dates proved to be particularly helpful in choosing between two alternative secondary SSNs when the reviewer had reason to believe that they referred to the same individual.
Name lines for later years may be valid substitutes for name lines in the base year when the SSNs in question do not change. But what if the secondary SSN does change? In particular, what if the base year secondary SSN failed a validation test based on the return name control and then changed the next year? Was this a true change in spouse or was it simply the correction of an SSN? Unless the two SSNs were so similar as to leave no doubt that one of the two SSNs was in error, the editors had to consider whether the change in SSN coincided with any pronounced change in circumstances, as reflected in the data reported on the two tax returns. Did the couple move, or did the earnings change markedly? These cases reduced to judgment calls on the part of the editors. In the SOCA Panel editing, such calls appear to have favored the determination that the filer changed, not just the SSN.
Multiple Occurrences within Filing Year
Incorrect panel SSNs may belong to other filers. If a panel member continues to use an incorrect SSN after the base year, and this SSN belongs to another filer, multiple occurrences of the SSN in question may be observed within a filing period. Such occurrences provide unambiguous evidence of the need for a correction. If the panel member does not continue to use the SSN, however, the false matches of out-year returns back to the incorrectly reported base year SSN become less easy to detect.
Findings
Table 1 summarizes our findings with respect to the frequency of erroneous SSNs in the population of tax returns filed for 1985, based on the editing of the base year data for the SOCA Panel. Of the SSNs that were determined to be incorrect, 42 percent belonged to other persons who filed during the next six years. Thus, 58 percent of the incorrect SSNs had to be identified without the compelling evidence provided by other filers using those SSNs correctly.
Table 1. —Percentage of 1985 SSNs Determined to be Incorrect
|
Type of SSN |
Percent incorrect |
|
Primary SSN |
0.57% |
|
Secondary SSN |
1.97 |
|
Source: SOI Division SOCA Panel. |
|
Table 2 summarizes the findings for the 1987 filing year, based on the first year of the 1987 Family Panel. These findings include dependent SSNs, which taxpayers were required to report for the first time in that year. It is striking, first of all, how closely the estimated error rates for primary and secondary SSNs match those of the much smaller SOCA Panel. Second, the error rate for all dependent SSNs is just over twice the error rate for secondary SSNs. This is lower than pessimistic predictions would have suggested, but it could also be an understatement of the true error rate. Most dependents do not file tax returns, and so the evidence on which to base the error determinations may not be as solid as the evidence for primary and secondary filers. The other surprising feature is how the error rate for dependent SSNs takes off after the fourth listed dependent, rising to 24 percent for dependents listed in the 7th through 10th positions. It remains to be determined whether this high error rate is a phenomenon of higher order dependents or, more broadly, of all dependents on returns that report seven or more dependents. The number of sample cases involving more than five dependents is quite small, however, so the precision of these estimates for higher order dependents is relatively low.
Table 2. —Percentage of 1987 SSNs Determined to be Incorrect
|
Type of SSN |
Percent Incorrect |
|
Primary SSN |
0.49% |
|
Secondary SSN |
1.65 |
|
All dependent SSNs |
3.39 |
|
1st dependent SSN |
3.36 |
|
2nd dependent SSN |
3.04 |
|
3rd dependent SSN |
3.63 |
|
4th dependent SSN |
3.56 |
|
5th dependent SSN |
7.78 |
|
6th dependent SSN |
13.59 |
|
7th-10th dependent SSNs |
24.31 |
|
Source: SOI Division Family Panel |
|
Conclusions and Recommendations
The quality of SSNs reported on IRS records in 1985 and 1987 appears to be quite good. For primary SSNs the error rate is exceedingly low, which can be attributed in large part to the quality checks that primary SSNs must pass before the IRS will “post” their returns to its master file. Secondary SSNs have more than three times the error rate of primary SSNs, but the error rate is still low. Moreover, the IRS has increased its validation efforts with respect to secondary SSNs, so their quality should improve over time. Dependent SSNs had twice the error rate of secondary SSNs in 1987, but 1987 was the first year that dependent SSNs were required to be reported. These error rates are likely to decline as taxpayers become accustomed to the new requirements and as the cumulative effect of IRS validation efforts grows. In offering a preliminary assessment of the impact of SSN errors on data quality, I would say that, as of now, there is no evidence from the SOCA Panel that matches lost or incorrectly made due to bad SSNs will seriously compromise analytical uses of the data.
With respect to SOI editing procedures, I would make the following broad recommendations. First, the SOI Division needs to increase the amount of automation in the validation procedures and reduce the amount of unproductive clerical review time. Much of the clerical review time, currently, is spent on cases that are judged, ultimately, to be correct. The strategy that I discuss below for constructing and using secondary name controls will directly address this recommendation. In addition, the application of record linkage technology to the name control validation tests could significantly reduce the potential clerical review by allowing SSNs to pass validation when a name control contains a simple error. What I have in mind is modifying the tests so that they can take account of partial matches. Second, validation and editing must be carried out in a more timely manner. Data capture relies on an exact match to a list of panel SSNs. Unless corrected SSNs are added to the list as soon as possible, returns that could otherwise be captured will be lost.
Finally, I want to encourage the SOI Division to develop secondary name controls from the name lines that became available in 1988 and use these name lines to edit the secondary SSNs in the Family Panel. Secondary name controls derived by even a simple algorithm from the full name line could substantially reduce the subset of cases that are flagged as possibly containing incorrect secondary SSNs. Reviewing all of the secondary SSNs that fail name control tests based on both the return name control and the secondary name control should then be feasible. Doing so will very likely prove to be an efficient way to identify virtually all cases with erroneous secondary SSNs.
Acknowledgments
I would like to thank the SOI Division for its support of this work. I would particularly like to acknowledge Michael Weber for his efforts in designing and overseeing the editing of both panel files, and Peter Sailer for encouraging attention to data quality. Finally, I would like to thank my colleague Larry Radbill for building the data files and generating the output on which the findings presented here are based.
Record Linkage of Census and Routinely Collected Vital Events Data in the ONS Longitudinal Study
Lin Hattersley, Office for National Statistics, U.K.
Abstract
Both manual and computerized methods of record linkage are used in the Office for National Statistics' Longitudinal Study (LS) —a representative one percent sample of the population of England and Wales, containing census and vital events data. Legal restrictions mean that individual name and address data cannot be carried on either census or vital events computer files. Linkage of records has to be achieved by the use of the National Health Central Register (NHSCR) database, where names and addresses are carried together with information on date of birth and medical registration. Once an individual has been identified as a bona-fide LS member and flagged at the NHSCR, data carried on their census record or vital events record(s) can be extracted from the appropriate census file and vital event(s) file and added to the LS database. At no time are the two computer systems linked. This paper will describe the record linkage process and touch on some of the key confidentiality concerns.
What Is the ONS Longitudinal Study?
The ONS Longitudinal Study (LS) is a representative 1 percent sample of the population of England and Wales containing linked census and vital events data. The study was begun in 1974 with a sample drawn from the population enumerated at the 1971 Census using four possible dates of birth in any year as the sampling criterion. Subsequent samples have been drawn and linked from the 1981 and 1991 Censuses using the LS dates of birth. Population change is reflected by the addition of new sample members born on LS dates and the recording of exits via death or emigration. The structure of the population in the LS is shown below.
Figure 1. —The Structure of the ONS Longitudinal Study
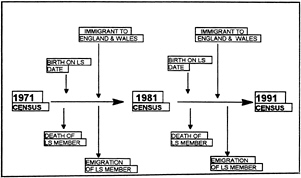
* © Crown Copyright 1997. Data from the ONS Longitudinal Study are Crown Copyright and are reproduced by permission.
At each of the Census points the full census schedule data on the LS person and other (non-LS) members in the same household are included in the database. However, it should be noted that linkages of routinely collected events data are only performed for the LS members. The household an LS member resides in at one Census may well be different from the household they are part of in the next, and other (non-LS) household members may therefore change overtime.
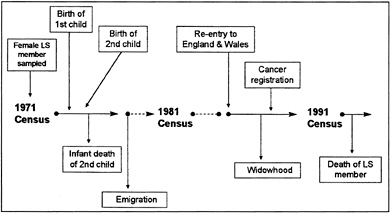
Routinely collected data on the mortality, fertility, cancer registrations, infant mortality of children born to LS sample mothers, widow(er)hoods and migration of LS members are linked into the sample using the National Health Service Central Register to perform the link (Figure 2). Marriages and divorces cannot be linked to the sample in Britain as the marriage certificate includes age, not date of birth.
Figure 2. —Event Linkage—The Event History of an LS Member
Creation of the Sample and Methods of Linkage
Linkage methods vary depending on the source of data, but all linkages are made using the National Health Service Central Register (NHSCR). NHSCR performs the vital registration function for England and Wales and is part of the Office for National Statistics. The register was begun in 1939 using the data from the full census of the population carried out on the outbreak of the Second World War. Each enumerated individual was given an identification number which was used to allocate food rationing cards. This number became the National Health Service (NHS) number in 1948 when the NHS was created. Subsequently NHS numbers were issued at birth, or if the person was an immigrant, an NHS number was allocated when they first signed on with a General Practitioner (GP). The NHS number is thus the only identification number that is almost universally held among the population of England and Wales.
NHSCR was computerized in 1991 and prior to that date all records were kept in hand written registers containing one line per person in NHS number order. Events such as births, deaths, cancer registrations, enlistment into the armed forces, entries into long-stay psychiatric hospitals, re-entries to the NHS, embarkation's and internal migration were noted in the registers together with any ciphers denoting membership of medical research studies. In 1991 an electronic register was created.
The Creation of the Original LS Sample
When the LS was begun in 1974 an index card was created for each potential sample member who was born on an LS date and enumerated in the 1971 Census. A unique 8 digit number was assigned to each LS member and printed on each card together with information that could identify the relevant census forms (such as ward, form number and enumeration district, sex, date of birth, marital status, person number and a usual residence indicator). The relevant census forms were then selected and from these name, usual address and enumeration address were written onto the cards. The cards were then sorted alphabetically and sent to NHSCR where they were matched against the registers. NHS numbers were added to the cards if the person was registered, and the register entries were flagged as LS. These cards were then used to create an LS alphabetical index held at NHSCR.
The essential element in the linkage of events to LS members is the possession of an NHS number and their presence as a member of the NHS register. Those LS members who do not possess NHS numbers are known as “not traced” and although Census data can be linked to them, vital event notifications, which are used by NHSCR in maintaining the registers, cannot. By the end of 1976 all but 3.2 percent of the 1971 sample LS members were traced in the register.
Different mechanisms are employed for census record linkage and event record linkage but both are covered by Acts of Parliament which restrict the use of certain data and at present prevent an electronic link being performed between the computer systems of NHSCR and the rest of ONS. Census data is covered by the Census Act which prevents the use of any data that can be used to identify an individual. As a result all completed census forms are stored for one hundred years before public release. Data from the schedules are held in electronic form but exclude names and addresses by law. However, dates of birth of all persons enumerated on each census form are included in the data. This inclusion of date of birth allows the identification of potential LS members at any census and together with the data which identifies each form uniquely, allows ONS to extract the forms and provide NHSCR with the names and addresses which can be used to match with their records.
The Linkage of Census Data to the LS
ONS have performed two LS-Census links to date, the first linking the 1971 and 1981 LS Census samples together, the second linking the 1981 and 1991 Census samples. Both LS-Census links were done in the same manner, although the computerisation at NHSCR in 1991 helped to speed the process of the second link.
After the 1981 Census, index cards and listings of potential LS members were created from the Census GB Households file by extracting data for each household which contained any person with an LS date of birth. Each potential LS member was allocated a unique 1981 LS serial number which was printed on both the cards and the listings. As in 1971, when the LS was created, the information printed on the index cards was used to locate the Census forms and the name and address were transcribed from the forms. These cards were then sent to NHSCR for matching against the LS alphabetical index. If the LS member already existed in the index (that is had been enumerated in 1971 or had been born or immigrated after the 1971 Census) the 1971 LS number was added to the 1981 card which was then returned to OPCS (now ONS) for processing. If the cards were not matched with any entry in the LS index then a search of the NHS registers was made and if a match was found then the Central Register was flagged LS81 and that person entered the LS as a new member. Further searches against the electoral registers, birth indexes, marriage indexes and the Family Practitioner Committee's GP patient registers were also made for unmatched cards in 1981. The cards were also checked for “traced” or “not traced” status and were then returned to OPCS for processing as one of five
types. These five types were:
-
matched to an existing “traced” LS member;
-
new “traced” 1981 entrant;
-
new “not traced” 1981 entrant;
-
matched to an existing “not traced” LS member (these could be “traced” or “not traced” in 1981); or
-
matched to a 1971 LS member but a double enumeration.
The LS numbers on the returned cards were validated and the resulting file was run against the 1981 LS Households file in order to add the 1971 LS number or intercensal entry LS number to the records. The final process in the link was the creation of separate LS personal and household files for 1981. After this was completed the cards were returned to NHSCR for addition to the LS index.
Figure 3. —The Linkage Process
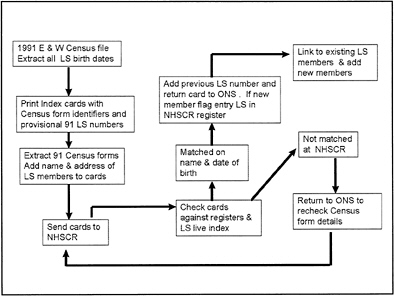
The 1981–1991 LS—Census link was completed in 1995 (Figure 3). Although NHSCR had been computerized in 1991 a manual linkage process was used to fulfill the confidentiality rules. As in 1981 index cards and listings were produced giving census schedule identifiers and 1991 LS serial numbers. The Census forms were extracted and the names and addresses were added for NHSCR identification purposes. Once the cards had been completed and checked they were sent to NHSCR for matching and tracing against the registers and LS indexes. The matching and tracing process was easier and faster than in 1981 as the cards were initially matched and traced against the NHSCR database entries rather than manually against the two rooms full of index cards which formed the LS alphabetical index. Only if no previous LS number existed or
there was no entry on the NHSCR database were the cards checked against the clerical registers and indexes. Any cards not matched were returned to OPCS for re-checking against the census forms to identify transcription errors. The NHS number and any pre-1991 LS numbers were added to the cards before their return to OPCS for processing.
How Good Was the Linkage Between Censuses?
The two LS-Census links so far performed have been extremely successful, with at least 90 percent of traced LS member's records being linked together. It should be noted that 97 percent of 1971 LS members., 99 percent of 1981 LS members and 98 percent of 1991 LS members were traced at NHSCR at the time of linkage (Table 1).
Table 1. —Forward Linkage Rates for the 1971–1981 LS-Census Link and the 1981–1991 LS-Census Link
|
Forward Linkage Rates |
|||||
|
1971 Census Sample* |
71–81 Linked Sample |
1981 Census Sample** |
81–91 Linked Sample |
1991 Census Sample*** |
|
|
N = 512,881 |
N = 530,248 |
N = 534,647 |
|||
|
Died prior to next census |
58,911 |
58,931 |
|||
|
Embarked prior to next census |
5,625 |
4,399 |
|||
|
Eligible to be in next census |
448,345 |
466,918 |
|||
|
Recorded in next census |
408,451 |
420,267 |
|||
|
Forward linkage rate |
91% |
90% |
|||
|
* Traced at NHSCR prior to the 1981 Census (97%). ** Traced at NHSCR prior to the 1991 Census (99%). *** Traced at NHSCR at the 1991 Census (98%). |
|||||
However, even allowing that LS-Census forward linkage rates were extremely good there were still approximately 10 percent linkage failures at each census. This problem of linkage failure was investigated using the NHSCR records to examine 1 percent samples of linkage failures as part of each of the LS-Census Link exercises.
Table 2. —Reasons for Failure to Link
|
Reasons for Failure to Link |
Number Believed to Still be in Sample But Not Found at Census |
|||
|
1971–81 Link N= 39,616 |
1981–91 Link N = 46,652 |
All LS Members Who Failed to Link by the 1991 Census* N = 92,580 |
||
|
Date of birth discrepancy between Census & NHSCR |
37% |
21% |
18% |
|
|
Cancelled NHS registration — whereabouts not known |
6% |
9% |
16% |
|
|
Missed event (emigration, death, enlistment) |
14% |
5% |
4% |
|
|
Not known |
10% |
5% |
18% |
|
|
Currently registered at NHSCR but not enumerated |
38% |
61% |
44% |
|
|
* Includes LS members lost to link in 1981 and still not linked in 1991 and LS members linked in 1981 but not in 1991. Excludes LS members who were lost to link in 1981 but were linked in 1991. |
||||
The total number of LS members lost to link between 1971 and 1991 was 92,580 (Table 2). Date of birth discrepancies were a major cause of failure to link providing at least 37 percent of failures in 1971. Those in the “Not known” category may well also have included sample members who had given dates of birth other than LS dates on their Census forms. The rise noted in “Cancelled NHS registrations,” which tend to occur if a person has not been seen by their GP for over two years, suggests that many of the persons in this category may have in fact emigrated but not reported it.
Vital Events Linkage
While the LS-Census links only take place once every ten years, vital events linkage occurs annually for most events and six monthly for some. There are two methods of identifying vital events occurring to LS members—firstly, through routine notification of events to NHSCR, where the LS member is identified by the presence of an LS flag in the register; and secondly, through the annual vital events statistics files compiled by ONS. Some types of event, deaths and cancer registrations are identified using both methods as a cross checking device (Table 3).
Table 3. —Vital Events and the Methods of Linkage
|
Event Type Currently Collected |
Linked Through Routine Notification |
Linked Through Stated Date of Birth |
|
New births into sample |
X |
|
|
Births (live & still) to LS mothers |
X |
|
|
Infant deaths of LS mothers children |
X |
|
|
Widowerhoods |
X |
|
|
Deaths of LS members |
X |
X |
|
Cancer registrations |
X |
X |
|
Immigrants into sample |
X |
|
|
Emigrations |
X |
|
|
Enlistment into armed forces |
X |
|
|
Re-entries from emigration and enlistment |
X |
How the Linkage Process Works
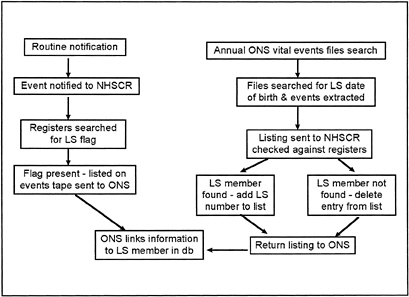
The identification of immigrants into the LS sample, emigrations out of England and Wales by sample members, enlistments into the armed forces and re-entries from emigration or enlistment are all made through the routine notification of these events to NHSCR (Figure 4). When NHSCR updates their database the LS flag is noted for all existing sample members and the details including the LS number are entered onto a tape that is sent twice yearly to ONS to update the LS database. Included in the tapes are details of date of emigration, enlistment or re-entry together with the relevant LS numbers, and for immigrants date of birth and entry details. ONS returns a listing to NHSCR containing the new LS numbers allocated to immigrants joining the sample and this is used by NHSCR to flag their database.
New births into the sample, births to sample mothers, infant deaths of LS members children and widow(er)hoods are all identified using date of birth searches of the annual vital events statistics files. The process involves extracting a subset of data from the statistics files using the LS birth dates as the selection criteria. In the case of new births an LS number is allocated and a listing is sent to NHSCR containing LS number, Date of birth and NHS number. The entry is checked and the LS number is added to the register entry and the new LS member is flagged.
Births to LS mothers are also extracted from the annual England and Wales births file, but the criterion used here is the date of birth of the mother which must be an LS date. A listing including registration details is sent to NHSCR where it is used to extract the relevant birth drafts to identify the name of the mother. The mother's name is then used to find the LS number which is added to the listing which is then returned to ONS for processing.
Infant death details are extracted from the annual deaths file and the mothers date of birth is then matched with the data on the LS births to sample mothers file. Any queries are sent to NHSCR for resolution using the registers. Widow(er)hoods are also linked using the annual deaths file. An LS date of birth search for the surviving spouse is used to extract the data and a listing giving the date of death and registration details is sent to NHSCR. NHSCR have access to the ONS deaths system and use this to identify the names of the deceased and their surviving spouse. The register is then searched for the surviving spouse's name and the LS number extracted and added to the listing.
Figure 4. —The Linkage Process
How Good Is the Linkage of Events?
The quality of event linkage is extremely good for new births into the sample and deaths occurring to sample members. Virtually 100 percent of these events are linked (Table 4). The rate of linkage for other events is high, with the exception of migration events. Unlike events directly associated with births and deaths which have to be registered within set times by law, migration events do not have to be compulsorily registered. Immigrants can only be linked to the sample when they register with a GP and this may be long after the date of immigration. The date of birth for immigrants is that taken from their NHS registration details and may not be accurate. Certainly, between 1971 and 1981, 62 percent more immigrants were linked to the LS than were expected based on the England and Wales immigration figures. Emigrations of LS members out of England and Wales are only captured if an LS member returns their medical card to their Family Health Service Authority on leaving the country or if the Department of Social Security informs NHSCR when a pensioner or a mother with children is no longer resident. As a result not only are emigrations undercounted but they are often notified to NHSCR many years after the event.
Table 4. —How Good is the Linkage of Events?
|
Event |
Percentage Linked Between 1971 And 1981 Census |
Percentage Linked Between 1981 And 1991 Census |
|
New births into sample |
101% |
100% |
|
Immigrants into sample |
162% |
106% |
|
Deaths of sample members |
98% |
109% |
|
Emigrations of sample members |
65% |
36% |
|
Births to sample mothers |
92% |
93% |
|
Widow(er)hoods |
77% |
84% |
|
Cancer registrations |
98% |
103%** |
|
Infant mortality |
86%* |
91% |
|
* Available from 1976 ** Available until 1989 |
||
Confidentiality Issues
There are two sets of confidentiality issues involved with the maintenance and usage of LS data. First, how to link data without breaching the legal restrictions on the release of census and certain vital statistics data, and second how to ensure that confidentiality is maintained by researchers using the data for analysis.
The processes of data linkage would be accelerated if electronic linkage could be achieved between ONS and NHSCR. However, at present this would contravene all legal requirements including that of current UK data protection legislation. The LS is not a survey where an individual gives their consent for the use of personal data but a study where administrative data collected for other purposes is used to provide a rich source of socio-demographic and mortality data about the England and Wales population over time. Given the restrictions imposed by this situation, the maintenance of the study must not only be done in such a manner as to comply with the legal instruments but must also be publicly seen to do so.
The restrictions on the methods used for linkage of the data also apply to the release of data for analysis by outside researchers. Any data which could conceivably identify an individual such as the LS dates of birth and LS number are used only within the database to achieve linkage between data files. Extraction of data is done within ONS itself and data is only released to researchers in aggregated form which will not permit the identification of an individual.
Conclusion
The LS is a complex linkage study which, by using the only universal identifier held by members of the population of England and Wales (the NHS number), has provided extremely high quality linked data on a 1 percent sample of that population for over 20 years.
The linkage methods used are partially computerised but because of legal restrictions much of the linkage is still labour intensive and reliant on the skills of ONS and NHSCR staff. Automatic linkage would be the ideal, but until it is legally feasible to electronically link the LS system to all other ONS systems (including the Census database) and to NHSCR, this is unlikely to be achieved.
Use of Probabilistic Linkage for an Analysis of the Effectiveness of Safety Belts and Helmets
Dennis Utter, National Highway Traffic Safety Administration
Abstract
This presentation will describe the use of linked data by the National Highway Traffic Safety Administration to generate population-based crash and injury state data that include the medical and financial outcome for specific crash, vehicle, and behavior characteristics. The linked data were used by NHTSA far a Report to Congress as mandated by the Intermodal Surface Transportation Efficiency Act (ISTEA) of 1991. Benefits were to be measured in terms of about their impact on mortality, morbidity, severity, and costs.
Hawaii, Maine, Missouri, New York, Pennsylvania, Utah, and Wisconsin, states with the most complete statewide crash and injury data, were funded by NHTSA to implement Crash Outcome Data Evaluation Systems (CODES). The states linked crash to hospital and EMS and/or emergency department data using their most recent data year available at the time, ranging from 1990–1992. Implementation of a uniform research model by the seven CODES states was successful because of the linked data. The presentation will discuss how the linked data were used to standardize non-uniform data and expand existing data for analysis.
Introduction
Motor vehicle traffic crashes continue to be a significant problem in the United States. Each year there re more than 6 million crashes investigated by police agencies. In these crashes 3.5 million people are injured, 450,000 of them severely, and nearly 42,000 are killed. Crashes produce a staggering economic toll, too. Nearly $151 billion are lost due to medical costs, property damage, legal costs, productivity losses, and other factors. Clearly, reducing the number of crashes and their severity is a necessity.
The National Highway Traffic Safety Administration (NHTSA) was created to reduce the number of deaths, the severity of injuries, and other damage resulting from motor vehicle traffic crashes. It does so through a variety of programs aimed at making vehicles safer, therefore mitigating the results of crashes, and by getting vehicle drivers and occupants to do things that would either prevent crashes or mitigate their outcomes. Evaluation of these programs requires a significant amount of data. Data linkage provides NHTSA, and the traffic safety community at large, with a source of population-based crash and injury state data that include the medical and financial outcome for specific crash, vehicle, and behavior characteristics.
Data files created from police reported motor vehicle crash data alone do not include medical outcome information for everyone involved in a motor vehicle crash. Thus, linking data became necessary when NHTSA was required by the Intermodal Surface Transportation Efficiency Act (ISTEA) of 1991 to report to the Congress about the benefits of safety belts and motorcycle helmets. Benefits were to be defined in terms of mortality, morbidity, severity, and costs. Statewide crash data files were determined by NHTSA to be the only source of population-based information about the successes (those who use the countermeasure and receive no or a less serious injury), the failures (those who do use the countermeasure and receive an injury), those not affected (those who do not use the countermeasure and receive no injury) and those who were not injured as seriously as they might have been because of the safety device.
CODES
Hawaii, Maine, Missouri, New York, Pennsylvania, Utah, and Wisconsin, states with the most complete statewide crash and injury data, were funded by NHTSA to implement Crash Outcome Data Evaluation Systems (CODES). The states linked crash to hospital and EMS and/or emergency department data using their most recent data year available at the time, ranging from 1990–1992. The study population was chosen from police reported data because of the importance of the safety belt and helmet utilization data contained in the crash file. The safety belt analysis included 879,670 drivers of passenger cars, light trucks and vans and the motorcycle analysis consisted of 10,353 riders of motorcycles. This presentation will describe how linked data made it possible for NHTSA to conduct a medical and financial outcome study of the benefits of safety belt and motorcycle helmets using routinely collected, population-based, person-specific state data.
Use of Linked Data to Standardized Non-Uniform Data for Analysis
Outcome Analysis Using “As Reported” Data
Measuring outcome is complicated when using “as reported” utilization data. Using this type of data, the CODES results indicated that although each state was different, all safety-belt odds ratios from all states agreed that safety belts are highly effective at all analysis levels at less than the 001 significance level. The non-adjusted effectiveness rates indicated that safety belts were 89% effective for preventing mortality and 52% effective for preventing any injury. The downward shift in severity was demonstrated by the decreasing effectiveness rates ranging from 89% for victims who die to 75% for those who die or are inpatients and to 54% for those who die, are inpatients, or are transported by EMS. But these results are inflated. When safety belt usage is mandated, human beings being human have a tendency to exaggerate their use of a safety belt, particularly when crash evidence or their injury type and severity are not likely to indicate otherwise. Over reporting of belt use moves large numbers of unbelted uninjured persons into the belted uninjured column thus inflating belt effectiveness. NHTSA repeated the research model to incorporate observed safety belt utilization rates into the analysis. Adjustments were made based on the assumption that 35 percent of the belted who were uninjured or slightly injured may have misreported their belt use at the time of the crash. These adjustments obtained the more realistic effectiveness rates of 60 percent for preventing mortality and 20–45 percent for preventing morbidity. In the future, as state injury data systems are improved to include safety utilization and external cause of injury information, linkage will make it possible to use the injury data to confirm utilization of the safety device.
Definition of the Occurrence of an Injury and Injury Severity
Although the study population was defined from the crash report, the linked data were used to define the occurrence of an injury and the various levels of injury severity. This standardization was necessary to compensate for inconsistent implementation of the police reported KABCO severity scale by the different states. For example New York classified one-third of the occupants involved in crashes as suffering “possible” injuries compared to about 10 percent in the other CODES states. For CODES, injury and the severity levels were defined by combining “injury severity” on the crash report with “treatment given” on the injury records to create five levels—died, inpatient, transported by EMS or treated in the ED, slightly injured or no injury. Police reported “possible” injuries were classified as non-injured unless the crash report linked to an injury or claims record. The severity levels were used to define the outcome measures (mortality, morbidity, injury severity, and cost) for the uniform research models for both the belt and helmet analyses as follows:
|
Mortality: |
Died versus all other crash-involved victims. |
|
Morbidity: |
Any injured compared to those not injured. |
|
Shift in Severity: |
Separate effectiveness rates for each severity level were calculated and then compared to measure the downward shift in injury severity |
|
Cost: |
Defined as inpatient charges because non-inpatient charges were not comparable among the seven states. |
Use of Linked Data to Expand Existing Data
Identifying Injuries Not Documented by the Police
Police are required to document only those crashes and injuries that occur on public roads and meet mandated reporting thresholds. In addition, some reportable injuries are not documented because of non-compliance with the requirements. CODES excluded cases not documented by the police because of the need for standardized safety device utilization information. But using only crash reports to document the injuries understates the total injuries. The CODES states used the linked crash and injury records to identify those injuries not documented by the police.
Identifying Financial Outcome
Data linkage provides highway safety with access to financial outcome information related to specific characteristics of the crash event. Lack of uniformity in the documentation of EMS and emergency department charges limited the CODES analysis to inpatient billed charges as indicated in the hospital data. These data were used to calculate average charges for inpatient drivers and all crash involved drivers. The analysis indicated that the average inpatient charge for unbelted drivers admitted to a hospital was 55% higher than for the belted, $13,937 compared to $9,004. If all drivers involved in police-reported crashes in the CODES states had been wearing a safety belt, costs would be reduced 41 percent (approximately $68 million in reduced inpatient charges or $47 million in actual costs). This type of information is powerful in the political arena and is unavailable to highway safety except through data linkage.
Identifying the Type of Injury
Linked data were crucial for the helmet analysis. By using only the level of severity NHTSA found that the effectiveness rates were low for helmets, 35% effective in preventing mortality, and only 9% effective in preventing morbidity. The downward shift in injury severity was much less than for safety belts. The linked data enabled NHTSA to redirect the analysis to brain injuries which the helmet is designed to prevent and found that helmets were 67 percent effective in preventing brain injury. That means 67% of the unhelmeted brain injured would not have been so injured if they had been helmeted. Looking at the costs for the brain injuries also justified focusing the analysis. Average inpatient charges for the brain injured were twice as high. Approximately $15,000 in inpatient charges would be saved during the first 12 months for every motorcycle rider who, by wearing the helmet, did not sustain a brain injury. Again, this type of information is more powerful than the overall effectiveness rate for helmets.
Barriers to Linkage of Crash and Injury Data
Probabilistic linkage requires computerized data. Unfortunately, not all states have crash and injury data that are statewide and computerized. Almost all of the states have computerized crash data statewide. Half of the states have developed state EMS data systems, but only a few have state emergency department data systems. A majority of the states have computerized state hospital discharge data systems. All of the states have computerized Medicaid and Medicare data systems, but few states have statewide computerized data files for private vehicle or health insurance claims data. Access to data for the less seriously injured victims, a group that includes many of the successes for highway safety, is difficult to obtain because the data may not be computerized. Or if computerized, they are computerized by provider or by insurance group and rarely statewide. Injury data are particularly useful to highway safety because they document what happens to all victims injured in motor vehicle crashes, regardless of whether the crash itself meets police reporting thresholds.
Benefits of Data Linkage
Data linkage provides documentation, generated from a state's own linked data, that is more credible among local decision makers who may be tempted to repeal the safety mandates, such as helmet legislation. And the data linkage process itself has the added benefit of making data owners and users more aware of the quality, or lack thereof, of the data being linked. The CODES states found that important identifiers that should have been computerized uniformly statewide were not; or if the identifiers were computerized, some of the attribute values were missing or inaccurate. All of the states became adept in discovering errors in the data and were motivated to revise their edits and logic checks. Thus annual linkage of the crash and injury state data provides the states, NHTSA, public health and injury control, with a permanent and routine source of outcome information about the consequences of motor vehicle crashes at the same time that the quality of state data are improved for their originally intended purposes.
Multiple Causes of Death for the National Health Interview Survey
John Horm, National Center for Health Statistics
Abstract
The National Health Interview Survey (NHIS) is a nationally representative health survey of the United States population. The NHIS is a rich resource for national and subnational health information such as chronic and acute conditions, doctor visits, hospital stays and a wide variety of special health topics knowledge, attitudes, and behaviors each year. Basic socio-demographic information is routinely collected on each person in the NHIS. The NDI contains records for virtually 100 percent of persons who die in the United States. Respondents to the NHIS who are age 18 or over are now routinely linked with the National Death Index (NDI) to create a new resource of immense public health and epidemiologic potential An automated probabilistic approach has been used to link the two data files from the date of interview through 1995 and classify the linked records as either true (deceased) or false (alive) matches. It is estimated that over 97 percent of deceased persons and 99 percent of living persons are correctly classified as to vital status. The linked NHIS-NDI files contain all of the survey information along with vital status, multiple causes of death and date of death if deceased.
Introduction
The National Health Interview Survey (NHIS) is a large in-person health survey of the United States population conducted annually by the National Center for Health Statistics (Dawson and Adams, 1987). Health and health-related information is collected on approximately 122,000 persons per year (42,000 households) among the civilian, non-institutionalized population (note that since matching with the NDI is done only for persons aged 18 and over, the sample size for this purpose is about 85,000 persons). The NHIS consists of a basic health and demographic questionnaire (BHD) with information on every person in the household. The BHD contains basic socio-demographic information, acute and chronic conditions, doctor visits, hospital stays, and related items. In addition to the BHD, one or more surveys on Current Health Topics (CHT) is also conducted each year. The CHT surveys are usually administered to one randomly selected sample person over the age of 18 in each family although there are some family-style CHT surveys. The sample-person CHT surveys yield information on about 42,000 persons per year. Recent CHT surveys include the following content areas: alcohol use; cancer epidemiology and control; child health; health insurance; adult immunization; Year 1990 health objectives; Year 2000 health objectives and others. All questionnaires and topic areas included from 1985 through 1989 have been published by Chyba and Washington (1993). Response rates for both components of the NHIS are high: 95 percent for the BHD and about 85 percent for the CHT's.
The NDI is a central computerized index with a standard set of identifying information on virtually every decedent in the United States since 1979 (Boyle and Decoufle, 1990) managed by the National Center for Health Statistics and can be used to enumerate and identify decedents in epidemiologic studies. The NDI produces matches between user records and death records based on a set of twelve criteria. The user must then develop a methodology to classify the potential matches returned by the NDI as either true or false matches.
The approach taken here to classify the NHIS-NDI potential matches is a modification of the probabilistic approaches developed by Fellegi and Sunter (1969) and refined by Rogot, Sorlie, and Johnson (1986).
Methods
The NDI contains records on all deaths occurring in the United States since 1979 and is fully documented in the National Death Index User 's Manual (1990). The NDI has developed a set of 12 criteria under which matches between user records and NDI records are produced. These criteria are based on various combinations of Social Security Number, date of birth, first name, middle initial, and last name. The 12 matching criteria are:
-
Social security number and first name;
-
Social security number and last name;
-
Social security number and father's surname;
-
If female, Social security number, last name (user's record) and father's surname (NDI record);
-
Month and year of birth and first and last name;
-
Month and year of birth and father's surname;
-
If female, month and year of birth, first name, last name (user's record) and father's surname (NDI record);
-
Month and year of birth, first and middle initials, and last name;
-
Month and ±1 year of birth, first and middle initials, and last name;
-
Month and ±1 year of birth, first and last names;
-
Month and day of birth, first and last names; and
-
Month and day of birth, first and middle initials, and last name.
An NDI record is matched to a user record if any one of the above 12 criteria result in a match.
An indication of agreement between the user record and the NDI record is returned to the user for each of the seven items involved in the twelve matching criteria. In addition to the items involved in the matching criteria the NDI returns an indication of agreement/disagreement between the user record and the NDI record on five additional items: age at death; race; marital status; state of residence; and state of birth. Multiple NDI records may be matched to a single user record and a possibly large number of false positive matches may be returned by the NDI. Matches between NDI records and NHIS records are referred to as potential matches.
The NHIS routinely collects all of the seven data items used by the NDI for matching as well as the five additional items used for assessing the quality of potential matches. The NHIS has essentially 100 percent complete reporting of these items except for social security number (SSN) and middle initial. Completeness of reporting of SSN and middle initial varies by year but is generally between 65 and 75 percent. Various studies have indicated that the NDI is capable of identifying over 90 percent of known deaths (Patterson and Bilgrad, 1986; Stampfer et al., 1984; Williams, Demitrack and Fries, 1992) with some studies finding that the proportion is in the upper 90's when a full set of identifiers is available (Calle and Terrell, 1993; Curb et al., 1985; Horm and Wright, 1993). Social Security Number is a key identifier in the matching process. When the SSN is not available the proportion of known deaths identified drops to about 90 percent.
Tepping (1968) developed a model for computerized matching of records from the perspective of the cost of making correct or incorrect decisions about potential matches. Fellegi and Sunter (1969) developed a theory-based approach for record linkage which incorporated the concept of weighting factors with the weight being positive if the factor agreed and negative if it disagreed With the magnitude of the weight being inversely
proportional to the frequency of the factor in the population. This approach was refined by Rogot, Sorlie, and Johnson (1986) who used binit weights [Log2 (1/pi)] where pi is the proportion of the population with the ith characteristic. Newcombe, Fair, and Lalonde (1992) while not espousing a particular form for the weights did make a case for the necessity of weighting by something more than simple agreement/disagreement weights.
Weights
Weights for each of the eleven items used for assessing the quality of the potential matches were constructed based on the composition of the 1988–91 NHIS and 1986–91 U.S. deaths (SSN is handled separately).
A weight is the base 2 logarithm of the inverse of the probability of occurrence of the characteristic based on the above files. For example, since males constitute about 46.3 percent of the population aged 18 and over, the weight is log2(1/.463) = 1.11. Weights are constructed in a similar manner for race, last name, father's surname, birth month, day, and year, state of residence, and state of birth. Since middle initials are sex-specific, sex-specific weights were constructed for middle initial. Weights for marital status were constructed to be jointly age and sex specific. First name weights are both sex and birth year cohort (<1926, 1926 –1935, 1936–1955, and >1955) specific because of secular trends in the assignment of first names.
Weights may be either positive or negative. If a particular item matches between the NHIS record and the NDI record, the weight is positive. If the item does not match, the weight is negative. Weights for items missing from the NHIS file, the NDI file, or both are assigned a weight of zero.
Last name weights have been modified for females. Since some females change their surnames upon marriage, divorce, remarriage, etc., matching on surname only may produce false non-matches. The NDI returns an indication of a match on the father's surname as well as last name which is used as auxiliary information for females. If last name does not match on the two records (the last name weight is negative), the last name weight is replaced with the father's surname weight if positive, otherwise the last name weight is retained. This approach provided the best classification performance for females.
Because all information provided to the NDI is proxy reported and information provided to the NHIS may be proxy reported, there is a considerably likelihood that one of the two files may contain a respondent's given first name while the other contains his/her commonly used nickname. We have constructed files of common nicknames which are used in the classification process if the first name on file does not provide a good match.
Frequency-based weighting schemes such as proposed by Fellegi and Sunter and Rogot, Sorlie, and Johnson are attractive since the rarer occurrences of a matching item is given more weight than more common occurrences. However, the user is still left with the problem of properly classifying matched records into at least minimal categories of true matches, false matches, and questionable matches. Recent work by Belin (1993) and Belin and Rubin (1993) suggests that the false-match rate is sensitive to the setting of cut-points.
Calibration Samples
Calibration samples need to have known vital status information such as date and location of death, and ideally, death certificate number on the sample subjects based on sources independent of the NDI. Two NCHS surveys meet this criteria.
The 14,407 persons who participated in the NHANES I examination survey (1971–75) were used as the first calibration sample. Active followup was conducted on this sample to ascertain the vital status of the participants and death certificates obtained for persons found to be deceased (Finucane et al., 1990). NHANES is a large nationally representative survey and is sufficiently similar to the NHIS to be used as a calibration sample for developing a methodology for classification of the NHIS-NDI matches.
The NHANES I followup sample was then matched to the NDI and randomly stratified into two samples, a developmental sample and a confirmation sample.
Any one calibration sample may have an inherent structural process which differs systematically from the target sample. Even though the NHANES sample was randomly stratified into two samples, systematic differences between NHANES and the NHIS could exist in both parts. Thus a second calibration sample was used to counteract potential structural differences. The second calibration sample used was the Longitudinal Study on Aging (LSOA) (Kovar, Fitti, and Chyba, 1992), a subset of the 1984 NHIS. The data used from this sample were those participants aged 70 and over at the time of interview and followed through August, 1988. Vital status was obtained independent of the NDI by interviewer followback in both 1986 and 1988.
Classification of Potential Matches
Potential matches returned by the NDI must be classified into either true or false matches. This is done by assigning a score, the sum of the weights, to each match.
Score = Wfirstname X sex X birthcohort+Wmiddleinitial X sex+Wlastname
+Wrace+Wmaritalstatus X sex X age+Wbirthday
+Wbirthmonth+Wbirthyear+Wstateofbirth+Wstateofresidence
The NHANES I developmental sample suggested that classification efficiency could be increased by grouping the potential matches into one of five mutually exclusive classes based on which items matched and the number of items matching. These classes are:
|
Class 1: |
Exact match on SSN, first, middle, and last names, sex, state of birth, birth month and birth year. |
|
Class 2: |
Exact match on SSN but some of the other items from Class 1 do not match although certain cases were moved from Class 2 to Class 5 because of indications that the reported SSN belonged to the spouse. |
|
Class 3: |
SSN unknown but eight or more of first name, middle initial, last name, birth day, birth month, birth year, sex, race, marital status, or state of birth match. |
|
Class 4: |
Same as Class 3 but less than eight items match. |
|
Class 5: |
SSN known but doesn't match. Some cases were moved from Class 5 to Class 3 because of indications that the reported SSN belonged to the spouse. |
In this classification scheme all of Class 1 are considered to be true matches implying that the individuals are deceased while all of the Class 5 matches are considered false matches. Assignment of records falling into one of Classes 2, 3, or 4, as either true matches or false matches was made based on the score and cut-off points within class. Records with scores greater than the cut-off scores are considered true matches while records with scores lower than the cut-off scores are considered false matches.
The cut-off scores were determined from the NHANES I developmental sample using a logistic model. The logistic model was used within each of classes 2, 3, and 4 to determine cut-off scores in such a manner as to jointly maximize the number and proportion of records correctly classified while minimizing the number and proportion of records incorrectly classified. The cut-off scores were then applied to the NHANES I confirmation sample for refinement. Slight fine-tuning of the cut-off scores was required at this stage because of the relatively small sample sizes. Finally the weights and cut-off scores were applied to the LSOA sample for final confirmation. Further refinements to the cut-off scores were not made.
Results
The recommended cut-off scores are estimated to correctly classify over 97 percent of NHIS decedents and over 99 percent of living persons. It is known that the NDI misses about five percent of known decedents. An adjustment for this has not been included in these classification rates.
Subgroup Biases in Classification
The correct classification rate for females who were known to be deceased is about 2.5 percentage points poorer for females than males. This is due to linkage problems caused by changing surnames through marriages, divorces, and widowhood. Even though father's surname is being used to provide additional information there still remain problems of correctly reporting and recording surnames in both the survey and on the death certificates. Both males and females have the same correct classification rates for living persons.
Among non-whites there are multiple problems including lower reporting of social security numbers and incorrect spelling/recording of ethnic names. The correct classification rates for non-white decedents dropped to 86 percent while the classification rate for living persons remained high at over 99 percent. The classification rate for deceased non-white females was about three percent lower than that for non-white male decedents (84.7 percent and 87.8 percent, respectively). These biases are due to the relatively large proportions of non-white decedents in Class 4 because of incorrect matching information. Females and non-whites falling into Classes 1, 2, 3, or 5 have the same classification rates as white males.
Discussion
Application of the above outlined matching and classification methodology to 1986 through 1994 NHIS survey year respondents provides death follow-up from the date of interview through 1995. The linkage of these files yields approximately 900 deaths for each survey year for each year of follow-up. For example, there are 7,555 deaths among respondents to the 1987 survey with an average of 8 1/2 years of follow-up. Although years can be combined to increase the sample sizes for data items included in the NHIS core (BHD items), this is not generally the case for supplements which change topic areas each year. NHIS supplements are usually administered to one randomly chosen person age 18 or over in each household. This results in an annual sample size for the NHIS of about 42,000 persons. The number of deaths among such supplement respondents would be approximately one-half the number of deaths listed above (e.g., about 450 deaths per survey year per year of follow-up).
The NHIS-NDI linked files (NHIS Multiple Cause of Death Files) can be used to estimate mortality rates (although caution must be given to biases), life expectancies, and relative risks or odds ratios of death for a wide variety of risk factors while controlling for the influence of covariates. For example, the impact of poverty or health insurance status on the risk of dying could be explored while simultaneously controlling for age, sex, race, acute or chronic conditions. Or, mortality rates according to industry or occupation could be
developed or for central city residents relative to rural residents. Such analyses are possible because the NHIS carries its own denominators (number at risk).
References
Belin, T.R., and Rubin, D.B. ( 1995). A Method for Calibrating False-Match Rates in Record Linkage, Journal of the American Statistical Association, 90, 430, 694–707.
Belin, T.R. ( 1993). Evaluation of Sources of Variation in Record Linkage Through a Factorial Experiment, Survey Methodology, 19, 1, 13–29.
Boyle, C.A., and Decoufle, P. ( 1990). National Sources of Vital Status Information: Extent of Coverage and Possible Selectivity in Reporting, American Journal of Epidemiology, 131, 160–168.
Calle, E.E., and Terrell, D.D. ( 1993). Utility of the National Death Index for Ascertainment of Mortality among Cancer Prevention Study II Participants, American Journal of Epidemiology, Vol 137, 235–241.
Chyba, M.M., and Washington, L.R. ( 1993). Questionnaires from the National Health Interview Survey, 1985–89, National Center for Health Statistics, Vital and Health Statistics, 1(31), DHHS Publication No. (PHS) 93–1307, Public Health Service, Washington, D.C. U.S. Government Printing Office.
Curb, J.D.; Ford, C.E.; Pressel, S.; Palmer, M.; Babcock, C.; and Hawkins, C.M. ( 1985). Ascertainment of Vital Status Through the National Death Index and the Social Security Administration, American Journal of Epidemiology, 121, 754–766.
Dawson, D.A., and Adams, P.F. ( 1987). Current Estimates from the National Health Interview Survey, United States, 1986, National Center for Health Statistics, Vital and Health Statistics, Series 10, No. 164, DHHS Pub. No. (PHS) 87–1592, Public Health Service, Washington, D.C. U.S. Government Printing Office.
Fellegi, I.P., and Sunter, A.B. ( 1969). A Theory for Record Linkage, Journal of the American Statistical Association, 64, 1183–1210.
Finucance, F.F.; Freid, V.M.; Madans, J.H.; Cox, M.A.; Kleinman, J.C.; Rothwell, S.T.; Barbano, H.E.; and Feldman, J.J. ( 1990). Plan and Operation of the NHANES I Epidemiologic Followup Study, 1986, National Center for Health Statistics, Vital and Health Statistics, Series 1, No. 25, DHHS Pub. No. (PHS) 90–1307, Public Health Service, Washington, D.C. U.S. Government Printing Office.
Horm, J.W., and Wright, R.A. ( 1993). A New National Source of Health and Mortality Information in the United States, Proceedings of the Social Statistics Section, American Statistical Association, San Francisco.
Kovar, M.G.; Fitti, I.E.; and Chyba, M.M. ( 1992). The Longitudinal Study on Aging: 1984–90. National Center for Health Statistics, Vital and Health Statistics, 1(28).
National Center for Health Statistics ( 1990). National Death Index User's Manual, U.S. Department of Health and Human Services, Public Health Service, Centers for Disease Control, National Center for Health Statistics DHHS Pub. No. (PHS) 90–1148.
Newcombe, H.B.; Fair, M.E.; and Lalonde, P. ( 1992). The Use of Names for Linking Personal Records. Journal of the American Statistical Association, 87, 1193–1208.
Patterson, B.H., and Bilgrad, R. ( 1986). Use of the National Death Index in Cancer Studies, Journal of the National Cancer Institute, 77, 877–881.
Rogot, E.; Sorlie, P.; and Johnson, N.J. ( 1986). Probabilistic Methods in Matching Census Samples to the National Death Index, Journal of Chronic Diseases, 39, 719–734.
Stampfer, M.J.; Willett, W.C.; Speizer, F.E.; Dysert, D.C.; Lipnick, R.; Rosner, B.; and Hennekins, C.H. ( 1984). Test of the National Death Index, American Journal of Epidemiology, 119, 837–839.
Tepping, B.J., ( 1968). A Model for Optimum Linkage of Records, Journal of the American Statistical Association, 63, 1321–1332.
Williams, B.C.; Demitrack, L.B.; and Fries, B.E. ( 1992). The Accuracy of the National Death Index When Personal Identifiers Other than Social Security Number Are Used, American Journal of Public Health, 82, 1145–1147.
































