
19- Citable Publications of Scientific Data
John Helly1
University of California at San Diego
This presentation focuses on what we have learned from a history of developments in scientific data publication that began in 1993 and continue today. The first data publication work at the San Diego Supercomputer Center started in 1993 related to natural resource management in San Diego Bay and evolved to an activity with the Ecologic Society of America (ESA) in order to solve some problems related to the preservation of long-term ecological data. These data were at risk of being lost, but in 1998 we set up a website that was designed for publishing data papers by the ESA. This effort then led to a letter in Nature2, which suggested that the scientific community should raise data collections to the status of citable entities in journals. This was followed by an ACM publication in 20023 and several other publications related to scientific data publication in the earth sciences and scalable models of data sharing. This meant that we were able to distill some basic principles and requirements for systems. These are the design principles that we employ in systems now in operation as well as new systems across disciplines and domains.
The three earliest digital library systems in continuous operation since their inception are:
1- The Scripps Institution of Oceanography (SIO) SIOExplorer, since 2001.
2- The Site Survey Databank (SSDB) for Integrated Ocean Drilling Project (IODP), since 2003.
3- The National Science Foundation Center for Multi-scale Modeling of Atmospheric Processes (CMMAP) Digital Library project in the atmospheric science, since 2005.
These systems are designed to deal with data up to the multi-petabyte range for data storage and transportation requirements. From these developments we have learned how to change the workflow for scholarly publication to achieve the goal of citable scientific data. The basic workflow for scientific scholarly research starts with collecting data, doing the research, writing and publishing a manuscript for which some of the people get credit for it through citations. Within the past few years, it has become possible for individuals to obtain the authority to issue digital object identifiers (DOIs). Previously this was an authority available only to commercial publishers. This new capability allowed us to introduce the use of DOIs for data to this workflow and make citable data publication a reality.
______________________
1 Presentation slides are available at http://sites.nationalacademies.org/PGA/brdi/PGA_064019.
2 J. Helly. New concepts of publication. Nature, 393, 1998.
3 J. Helly, T. T. Elvins, D. Sutton, D. Martinez, S. Miller, S. Pickett, and A. M. Ellison. Controlled publication of digital scientific data. CACM (accepted October 3. 2000), May, 2002.
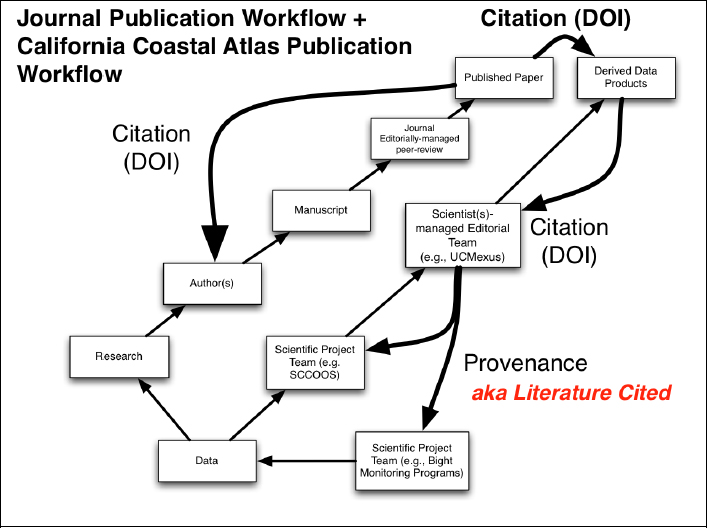
FIGURE 19-1 Basic scholarly workflow paralleling the new corresponding workflow for data publication.
SCCOOS and UCMexus are acronyms pertaining to specific projects.
We kept the same basic workflow with a path for data paralleling the manuscript path. The key here is to develop the training necessary to teach these steps to graduate students and expert scientists to ensure progress in this area for a number of reasons. Only scientific experts can ensure data quality and provide sufficient metadata to enable this process. The federal agency archival requirements for data developed under federal grants are clearer than previously, but we need some incentives as well. There are also financial issues to deal with: How are long-term archives to be supported?
Non-interoperability of DOIs from different systems is also a looming problem. Recent information has come to light that the main DOI providers for data are not interoperating. This is a problem because the whole concept of changing the workflow hinges on the ability to resolve the DOI issues across the different domains and publishing systems. The scientific community may need another solution that fully realizes the value of DOIs and warrants the effort to use them. It looks like many of the old players in the publication industry are moving to “wall-off’ what they perceive as their intellectual property by sequestering their DOI cross-referencing.
Let me now talk about the California Coastal Atlas. It is designed for data publication, with a focus on developing methods and training people to do high-quality scientific data production,
primarily in the geospatial data area. The model is scalable by design. We know that science proceeds through research projects and that these projects have finite life times. The key people are the Principal Investigators, the research managers sponsoring the projects, and the other people who are doing the work. So, through cooperation between the chief editor of the Atlas and the different projects teams, the projects agree to do their data management according to the Atlas conventions and standards. By modifying that workflow slightly, though not dramatically, we were able to provide a platform for those scientific projects to have high-quality data end products.
The current projects are:
• UCMexu: Declining Oxygenation and pH of the Eastern Pacific Margin.
• US Navy: A Methodology for Assessing the Impact of Sea Level Rise on Military Installations in the Southwestern United States.
• California Environmental Data Exchange Network: the 303D-listing Dataset.
• The California Spatial Data Infrastructure.
We believe that the real keys to success in this process are a set of factors that can be summarized as follows:
• Changing scientific workflows in familiar, but powerful ways to attribute high- quality data to the authors.
• Incentivize researchers to modify their existing workflows only slightly and provide tools to do it.
• Integration into a well-established and trusted system of scholarly publication.
• Providing the basis for protecting intellectual property rights.
The figure below provides the visual representation of our approach to automate the production of metadata. The intermediate products that are generated automatically include a bibliographic reference file, a metadata interchange file that talks only to OAI- PMH, and then the basic underlying metadata or the data content in the form of what we call an arbitrary digital object.
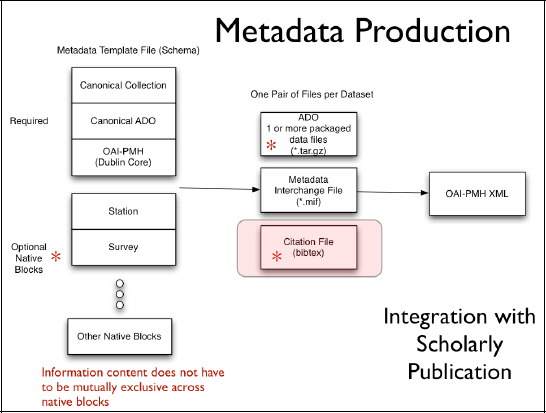
FIGURE 19-2 Metadata production process emphasizing the modular nature of metadata organization to support the minimal needs for cataloging as well as the disciplinary needs for re-use of the data.
We use conventional tools (LaTex/BibTex) that have seen a resurgence in the past five years to produce the content of the Atlas and to ingest the bibliographic reference information using tools like BibTex, so that the data underlying an image, for example, could be directly cited within the context of the document in the California Coastal Atlas.
The editorial policy is probably the most confusing part, especially in terms of how it is actually done. The following figure attempts to depict it.
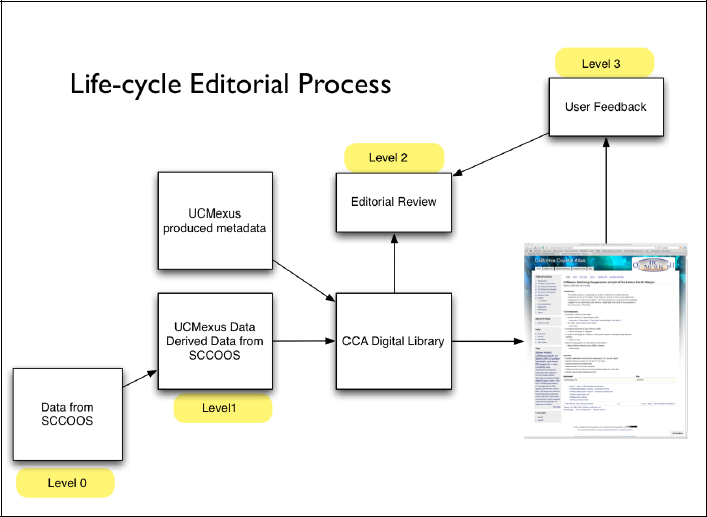
FIGURE 19-3 The editorial workflow organized into levels with requirements to transition from one level to another. Level 0 is raw data. Levell is data that has been quality controlled and provisioned with metadata. Level 2 data is data that has been through peer-review and Level 3 data has been used by others and may be combined with other data.
We define levels of data in the form of state machine transitions, since there are requirements for going from level zero to level one and then to level two. There is always a question of managing derived data, how to combine and track it and that is where DOIs play a powerful role. There is an on-going question of user feedback when data anomalies are found in subsequent use and the project that produced the data has ended. How do anomalous reports get factored back into the maintenance of the data collection?
I will conclude with this set of editorial requirements for data publication, which are essentially the instructions to authors. With editorial guidance, data authors should provide:
• Derived data products in CCA-conforming data format and packaging;
• CCA-conforming metadata (fully-provenanced);
• Procedural software for reading the data object;
• Corresponding output listing for verification of data contents;
• Metadata for obtaining a Digital Object Identifier;
• Manifest with summary description (e.g., README) describing what is contained in the arbitrary digital object; and
• Licensing statement.






